剖析Web
HTTP超文本传输协议,规则了网络客户端和服务端之间如何交换请求和响应。HTML超文本标记语言,结果的展示格式。URL统一资源定位符,唯一表示服务器和服务器上资源的方法。
Web客户端
使用telnet进行测试
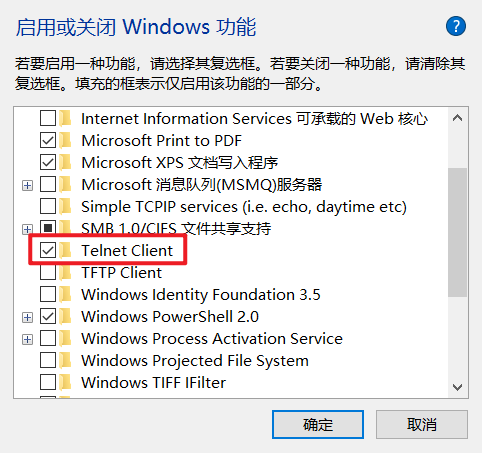
使用windows操作系统时,可以在"打开或关闭Windows功能"中开启“Telnet客户端”,如下图所示:
Python的标准Web库
http库会处理所有客户端-服务器HTTP请求的具体细节:
>>> import http
>>> http.
>>> http.HTTPStatus( http.IntEnum( http.client http.cookiejar http.cookies
>>> http.HTTPStatus.OK
<HTTPStatus.OK: 200>
>>> import http.server
>>> http.server.
http.server.BaseHTTPRequestHandler( http.server.email http.server.posixpath
http.server.CGIHTTPRequestHandler( http.server.executable( http.server.select
http.server.DEFAULT_ERROR_CONTENT_TYPE http.server.html http.server.shutil
http.server.DEFAULT_ERROR_MESSAGE http.server.http http.server.socket
http.server.HTTPServer( http.server.io http.server.socketserver
http.server.HTTPStatus( http.server.mimetypes http.server.sys
http.server.SimpleHTTPRequestHandler( http.server.nobody http.server.test(
http.server.argparse http.server.nobody_uid( http.server.time
http.server.copy http.server.os http.server.urllibhttp.client是一个底层的HTTP协议客户端,高层库使用urllib.request。http.server提示Web服务器程序。Warning[http.server](https://docs.python.org/3/library/http.server.html#module-http.server) is not recommended for production. It only implements basic security checks.官网上面不建议使用http.server用作生产服务器,因为它仅仅实现了基本的安全检查。可以使用
python -m http.server 8000生成一个简单的目录共享服务器。
urllib是基于http的高层库。
>>> import urllib
>>> urllib.
urllib.error urllib.parse urllib.request urllib.responseurllib.request是处理客户端请求。urllib.response是处理服务端的响应。urllib.parse会解析URL数据。
第三方库requests
requests模块是基于urllib模块开发的,在大多数情况下,使用requests可以让Web客户端开发变得更加简单。
安装:
pip install requests>>> import requests
>>> requests.
requests.ConnectTimeout( requests.URLRequired( requests.logging
requests.ConnectionError( requests.adapters requests.models
requests.DependencyWarning( requests.api requests.options(
requests.FileModeWarning( requests.auth requests.packages
requests.HTTPError( requests.certs requests.patch(
requests.NullHandler( requests.chardet requests.post(
requests.PreparedRequest( requests.check_compatibility( requests.put(
requests.ReadTimeout( requests.codes requests.request(
requests.Request( requests.compat requests.session(
requests.RequestException( requests.cookies requests.sessions
requests.RequestsDependencyWarning( requests.delete( requests.status_codes
requests.Response( requests.exceptions requests.structures
requests.Session( requests.get( requests.urllib3
requests.Timeout( requests.head( requests.utils
requests.TooManyRedirects( requests.hooks requests.warnings要通过GET访问一个页面,只需要几行代码。
查看豆瓣首页:
>>> import requests
>>> r = requests.get('https://www.douban.com/') # 豆瓣首页
>>> r.
r.apparent_encoding r.encoding r.iter_lines( r.raw
r.close( r.headers r.json( r.reason
r.connection r.history r.links r.request
r.content r.is_permanent_redirect r.next r.status_code
r.cookies r.is_redirect r.ok r.text
r.elapsed r.iter_content( r.raise_for_status( r.url
>>> r.status_code
418
>>> r.text
''可以看到,因为豆瓣的反爬虫机制导致获取到的内容异常,返回码是418,而不是200。
我们补充上headers ,目的是模拟浏览器,欺骗服务器,获取和浏览器一致的内容。
>>> import requests
>>> headers={'Referer': 'https://book.douban.com/','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win
64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# 增加请求头和超时设置
>>> r = requests.get('https://www.douban.com/', headers=headers, timeout=3) # 豆瓣首页
# 请求状态码
>>> r.status_code
200
>>> r.text
'<!DOCTYPE HTML>\n<html lang="zh-cmn-Hans" class="ua-windows ua-webkit">\n<head>\n<meta charset="UTF-8">\n<meta name="go
ogle-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />\n<meta name="description" content="提供
图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">\n<meta name="keywords" content="豆瓣,广播,登陆豆
瓣">\n<meta property="qc:admins" content="2554215131764752166375" />\n<meta property="wb:webmaster" content="375d4a17a4f
... 省略
# 实际请求的URL
>>> r.url
'https://www.douban.com/'
# 查看cookies信息
>>> r.cookies
<RequestsCookieJar[Cookie(version=0, name='bid', value='XOX32QgJXj8', port=None, port_specified=False, domain='.douban.com', domain_specified=True, domain_initial_dot=True, path='/', path_specified=True, secure=False, expires=1619771562, discard=False, comment=None, comment_url=None, rest={}, rfc2109=False), Cookie(version=0, name='ll', value='"108304"', port=None, port_specified=False, domain='.douban.com', domain_specified=True, domain_initial_dot=True, path='/', path_specified=True, secure=False, expires=1619771561, discard=False, comment=None, comment_url=None, rest={}, rfc2109=False)]>
# 内容编码方式
>>> r.encoding
'utf-8'Web服务端
可以使用一行代码启动一个最简单的Web服务器:
$ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...默认是8000端口,启动服务时,也可以指定其他端口:
$ python -m http.server 9000
Serving HTTP on 0.0.0.0 port 9000 (http://0.0.0.0:9000/) ...注意,不要将这个简单的Web服务器用用产品线网站中。Nginx和Apache等传统Web服务器可以更快地处理静态文件。
当我们想能够动态运行程序的Web服务器时,在Web发展的早期,出现了通用网关接口(CGI),客户端通过它来让Web服务器运行外部程序并返回结果;CGI也会从Web服务器获取用户输入的参数并传递给外部程序。然而,对于每个用户请求都需要运行一次程序,这样很难扩大用户规模,因为即使程序很小,启动时还是会有明显的等待时间。
为了避免启动延时,人们开始把语言解释器合并到Web服务器中。Apache可以通过mod_php模块来运行PHP,通过mod_perl模块来运行Perl,通过mod_python模块来运行Python。这样,动态语言的代码就可以直接在持续运行的Apache进程中执行,不用再调用外部程序。另一种方式 是在一个独立的持续运行的程序中运行动态语言,并让它和Web服务器进行通信,例如FastCGI和SCGI。
Web服务器网关接口(WSGI)的定义极大地促进了Python在Web方面的发展,WSGI是一个通用的API,连接Python Web应用和Web服务器。
Web服务器会处理HTTP和WSGI的具体细节,但是真正的网站是你使用框架写出的Python代码。有许多Python Web框架可供选择。对于一个Web框架来说,至少要具备处理客户端请求和服务端响应的能力,框架可能会具备下面这些特性中的一种或多种。
- 路由, 解析URL并找到对应的服务端文件或者Python服务器代码。
- 模板, 把服务端数据合并成HTML页面。
- 认证和授权,处理用户名、密码和权限。
- Session,处理用户在多次请求之间需要存储的数据。
Bottle轻量级Web框架
Bottle是一个非常小巧但高效的微型 Python Web 框架,它被设计为仅仅只有一个文件的Python模块,并且除Python标准库外,它不依赖于任何第三方模块。
- 路由(Routing):将请求映射到函数,可以创建十分优雅的 URL。
- 模板(Templates):Pythonic 并且快速的 Python 内置模板引擎,同时还支持
mako,jinja2,cheetah等第三方模板引擎。 - 工具集(Utilites):快速的读取 form 数据,上传文件,访问 cookies,headers 或者其它 HTTP 相关的元数据。
- 服务器(Server):内置HTTP开发服务器,并且支持
paste,fapws3,bjoern等多种WSGI HTTP 服务器。
安装:pip install boottle。
使用bottle生成一个测试Web服务器:
# filename: use_bottle1.py
from bottle import route, run
@route('/')
def index():
return "Hello Bottle!"
run(host='localhost', port=8080)使用python use_bottle1.py运行Web服务器,则在浏览器中访问localhost:8080则会看到Hello Bottle!。
bottle使用route装饰器来关联URL和函数。run函数会执行bottle内置的Python测试用Web服务器。
把HTML硬编码到代码中是很不合适的,我们可以创建单独的HTML文件use_bottle2_index.html并写入内容:
My <b>new</b> and <i>improved</i> home page!!!
创建use_bottle2.py文件,内容如下:
# filename: use_bottle2.py
from bottle import route, run, static_file
@route('/')
def index():
return static_file('use_bottle2_index.html', root='.')
run(host='localhost', port=8080)我们使用python use_bottle2.py重新运行Web服务,此时在浏览器中看到的内容如下:
My new and improved home page!!!
Bottle是一个非常优秀的入门框架,你可以参考https://bottlepy.org/docs/dev/ 查看Bottle的其他特性。如果你需要更多的功能,那可以试下Flask。
Flask框架
Flask和Bottle一样易用,同时还支持很多专业Web开发需要的扩展功能。Flask既好用又强大。
Flask安装: pip install flask
Flask官方文档:https://dormousehole.readthedocs.io/en/latest/
后续会单独弄一个版块出来讲解Flask框架的学习过程。此处不提。
Django重量级Web模型
Django是一个由Python编写的具有完整架站能力的开源Web框架。使用Django,只要很少的代码,Python的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的Web服务。
Django本身基于MVC模型,即Model(模型)+View(视图)+ Controller(控制器)设计模式,因此天然具有MVC的出色基因:开发快捷、部署方便、可重用性高、维护成本低等。Python加Django是快速开发、设计、部署网站的最佳组合。
非Python的Web服务器
在生产环境中,我们需要更快的Web服务器来运行Python,下面是常用的选择:
Apache加上mod_wsgi模块,Apache非常流行。Nginx加上uWSGI应用服务器,Nginx更稳定并且占用的内存更少。
在要Apache中运行Python,需要进行一定的配置,后续单独专题讲解如何配置。
Nginx没有内嵌的Python模块,它通过一个独立的WSGI服务器(如uWSGI)来和Python程序通信,把它们结合在一起可以实现高性能并且可配置的Python Web开发平台。
Web服务和自动化
webbrowser模块
python的webbrowser模块支持对浏览器进行一些操作,对于爬虫来说是比较基础的知识点。
在大多数情况下,用户只需要调用
webbrowser的open()方法即可。在Unix/Linux操作系统中,如果没有安装
X11的话,图形浏览器不可用的情况下,webbrowser将会使用文本模式浏览器,调用过程将会一直阻塞,直到用户退出浏览器。BROWSER变量的设置,如果在环境变量中设置了BROSWER变量,webbrowser程序则会将BROWSER解析为浏览器列表,BROSWER全局变量中多个浏览器使用os.pathsep如(;)分隔开。webbrowser可以在命令行中使用,python -m webbrowser -t "http://www.python.org"则会在默认浏览器中打开python的官网。
webbrowser定义了以下异常:
webbrowser.Error, 当浏览器控制错误时抛出该异常。
webbrowser定义了以下方法:
webbrowser.open(url, new=0, autoraise=True), 这个方法是在默认的浏览器中显示url, 如果new = 0, 那么url会在同一个浏览器窗口下打开;如果new = 1, 会打开一个新的窗口;如果new = 2, 会打开一个新的tab, 如果autoraise = true, 窗口会自动增长。当我的Google浏览器作为默认浏览器时,并处于打开状态下,new=0或1或2时,在Google浏览器中都是打开一个新的标签页。webbrowser.open_new(url), 在默认浏览器中打开一个新的窗口来显示url, 否则,在仅有的浏览器窗口中打开url。webbrowser.open_new_tab(url),在默认浏览器中当开一个新的tab来显示url, 否则跟open_new()一样。webbrowser.get(using=None),返回正在使用的浏览器类型的控制对象,如果using为None则会返回默认的浏览器控制对象。webbrowser.register(name, constructor, instance=None, *, preferred=False),注册一个名字为name的浏览器,如果这个浏览器类型被注册就可以用get()方法来获取。
使用webbrowser模块
>>> import webbrowser
>>> webbrowser.
webbrowser.BackgroundBrowser( webbrowser.Mozilla( webbrowser.open_new(
webbrowser.BaseBrowser( webbrowser.Netscape( webbrowser.open_new_tab(
webbrowser.Chrome( webbrowser.Opera( webbrowser.os
webbrowser.Chromium( webbrowser.UnixBrowser( webbrowser.register(
webbrowser.Elinks( webbrowser.WindowsDefault( webbrowser.register_X_browsers(
webbrowser.Error( webbrowser.browser webbrowser.shlex
webbrowser.Galeon( webbrowser.get( webbrowser.shutil
webbrowser.GenericBrowser( webbrowser.iexplore webbrowser.subprocess
webbrowser.Grail( webbrowser.main( webbrowser.sys
webbrowser.Konqueror( webbrowser.open(使用默认浏览器访问URL
使用webbrowser打开python官网:
url = 'http://docs.python.org/'
# Open URL in default broswer
webbrowser.open(url)
# Open URL in a new tab, if a browser window is already open.
webbrowser.open_new_tab(url)
# Open URL in new window, raising the window if possible.
webbrowser.open_new(url)使用其他浏览器访问URL
设置默认浏览器为safari浏览器,尝试使用firefox浏览器打开URL链接。
$ python3
Python 3.6.8 (v3.6.8:3c6b436a57, Dec 24 2018, 02:10:22)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import webbrowser
# webbrowser尝试打开浏览器
>>> webbrowser._tryorder
['MacOSX', 'chrome', 'firefox', 'safari']
>>> webbrowser._browsers
{'safari': [None, <webbrowser.MacOSXOSAScript object at 0x102e79ba8>], 'firefox': [None, <webbrowser.MacOSXOSAScript object at 0x1060cef60>], 'chrome': [None, <webbrowser.MacOSXOSAScript object at 0x1060e5208>], 'macosx': [None, <webbrowser.MacOSXOSAScript object at 0x1060e5748>]}
>>> url = 'https://www.baidu.com'
>>> webbrowser.open(url) # 此时打开的是safari浏览器
True
>>> webbrowser.get('firefox').open(url) # 此时打开的是firefox浏览器
True
>>> webbrowser.get('safari').open(url) # 此时打开的是safari浏览器
True
>>> webbrowser.get('chrome').open(url) # 此时提示异常,找不到chrome浏览器
69:77: execution error: 不能获得“application "chrome"”。 (-1728)
False
>>> webbrowser.get('MacOSX').open(url) # 此时打开的是默认浏览器safari浏览器
True设置默认浏览器为firefox浏览器,再尝试使用safari浏览器打开URL链接。执行上面执行的命令:
$ python3
Python 3.6.8 (v3.6.8:3c6b436a57, Dec 24 2018, 02:10:22)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import webbrowser
>>> webbrowser._tryorder
['MacOSX', 'chrome', 'firefox', 'safari']
>>> url = 'https://www.baidu.com'
>>> webbrowser._browsers
{'safari': [None, <webbrowser.MacOSXOSAScript object at 0x102e7ab70>], 'firefox': [None, <webbrowser.MacOSXOSAScript object at 0x102fcbf98>], 'chrome': [None, <webbrowser.MacOSXOSAScript object at 0x102fe2208>], 'macosx': [None, <webbrowser.MacOSXOSAScript object at 0x102fe2748>]}
>>> webbrowser.open(url) # 使用默认浏览器firefox打开URL
True
>>> webbrowser.get('firefox').open(url) # 使用火狐浏览器firefox打开URL
True
>>> webbrowser.get('safari').open(url) # 使用safari浏览器打开URL
True
>>> webbrowser.get('chrome').open(url) # 此时提示异常,找不到chrome浏览器
69:77: execution error: 不能获得“application "chrome"”。 (-1728)
False
>>> webbrowser.get('MacOSX').open(url) # 此时打开的是默认浏览器firefox浏览器
True参考:python's webbrowser launches IE instead of default on windows 7
Web API和表述性状态传递REST
通常来说,数据只存在于网页内。如果你想获取数据,需要在Web浏览器中访问网页并阅读数据。如果网站作者在你最后一次访问之后做了什么改动,数据的位置和格式就有可能发生变化。
除了发布网页,你还可以通过应用编程接口(API)来提供数据。客户端通过URL来访问你的服务并从响应中获取状态和数据。数据并不是HTML网页,而是更容易被程序处理的格式,如json和xml。
表述性状态传递REST(Representational State Transfer)是Roy Fielding在他的博士论文中提出的概念。许多产品都宣称他们具备REST接口或者RESTful接口,在具体实现上,其实就是一个Web接口,即定义一组可以访问Web服务在URL。
- 任何事物,只要有被引用的必要,它就是一个
资源。资源可以是一个实体(例如:手机号)也可以是一个抽象概念(例如:价值)。 - 要让一个资源被识别,需要有一个唯一标识,在Web中这个唯一标识就是URI(Uniform Resource Identifier)。
RESTful服务会用特定的方式来使用HTTP动词:
HEAD获取资源的信息,但是不包括数据。GET从服务器取回资源的数据。GET不应该被用来创建、修改或者删除数据。POST新建或更新服务器上的数据。PUT用客户端的实例创建一个资源。DELETE删除一个资源。
网络爬虫
当你希望在网络上获取数据的时候,你可以通过以下方法手动提取数据:
- 在浏览器中输入URL;
- 等待页面加载;
- 浏览页面并找到你想要的信息;
- 把信息记录下来;
- 可能要把这个过程重复应用在所有相关的URL上。
如果我们希望能自动执行期中的一步或者多步。自动抓取Web信息的程序叫做爬虫,从远端服务器获取到信息之后爬虫会进行解析并寻找有用的信息。
- 企业级的爬虫,强烈推荐Scrapyhttps://scrapy.org/。Scrapy是一个爬虫框架,并不是类似BeautifulSoup的模块。
- Scrapy 是一个非常成熟的工具包,你只要写很少的东西就能达到你要的效果——创建一个spider下载网页并提取其中有用的数据。
- BeautifulSoup 则是一个面向网页的工具,它能够解析 DOM 树并提取某些特定的节点(比如
<img>等)。 - 可以使用
pip install scrapy beautifulsoup4安装这两个包。
参考: