数据库处理
sqlite3处理SQLite数据库
安装SQLite,请参照 SQLite 安装 。
安装完成后将SQLite安装路径加入到环境变量Path中。
在命令行打开sqlite3,并查看帮助信息:
$ sqlite3
SQLite version 3.27.2 2019-02-25 16:06:06
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> .help
.archive ... Manage SQL archives
.auth ON|OFF Show authorizer callbacks
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail on|off Stop after hitting an error. Default OFF
.binary on|off Turn binary output on or off. Default OFF
.cd DIRECTORY Change the working directory to DIRECTORY
.changes on|off Show number of rows changed by SQL
.check GLOB Fail if output since .testcase does not match
.clone NEWDB Clone data into NEWDB from the existing database
.databases List names and files of attached databases
.dbconfig ?op? ?val? List or change sqlite3_db_config() options
.dbinfo ?DB? Show status information about the database
.dump ?TABLE? ... Render all database content as SQL
.echo on|off Turn command echo on or off
.eqp on|off|full|... Enable or disable automatic EXPLAIN QUERY PLAN
.excel Display the output of next command in a spreadsheet
.exit ?CODE? Exit this program with return-code CODE
.expert EXPERIMENTAL. Suggest indexes for specified queries
.fullschema ?--indent? Show schema and the content of sqlite_stat tables
.headers on|off Turn display of headers on or off
.help ?-all? ?PATTERN? Show help text for PATTERN
.import FILE TABLE Import data from FILE into TABLE
.imposter INDEX TABLE Create imposter table TABLE on index INDEX
.indexes ?TABLE? Show names of indexes
.limit ?LIMIT? ?VAL? Display or change the value of an SQLITE_LIMIT
.lint OPTIONS Report potential schema issues.
.load FILE ?ENTRY? Load an extension library
.log FILE|off Turn logging on or off. FILE can be stderr/stdout
.mode MODE ?TABLE? Set output mode
.nullvalue STRING Use STRING in place of NULL values
.once (-e|-x|FILE) Output for the next SQL command only to FILE
.open ?OPTIONS? ?FILE? Close existing database and reopen FILE
.output ?FILE? Send output to FILE or stdout if FILE is omitted
.print STRING... Print literal STRING
.progress N Invoke progress handler after every N opcodes
.prompt MAIN CONTINUE Replace the standard prompts
.quit Exit this program
.read FILE Read input from FILE
.restore ?DB? FILE Restore content of DB (default "main") from FILE
.save FILE Write in-memory database into FILE
.scanstats on|off Turn sqlite3_stmt_scanstatus() metrics on or off
.schema ?PATTERN? Show the CREATE statements matching PATTERN
.selftest ?OPTIONS? Run tests defined in the SELFTEST table
.separator COL ?ROW? Change the column and row separators
.sha3sum ... Compute a SHA3 hash of database content
.shell CMD ARGS... Run CMD ARGS... in a system shell
.show Show the current values for various settings
.stats ?on|off? Show stats or turn stats on or off
.system CMD ARGS... Run CMD ARGS... in a system shell
.tables ?TABLE? List names of tables matching LIKE pattern TABLE
.testcase NAME Begin redirecting output to 'testcase-out.txt'
.timeout MS Try opening locked tables for MS milliseconds
.timer on|off Turn SQL timer on or off
.trace ?OPTIONS? Output each SQL statement as it is run
.vfsinfo ?AUX? Information about the top-level VFS
.vfslist List all available VFSes
.vfsname ?AUX? Print the name of the VFS stack
.width NUM1 NUM2 ... Set column widths for "column" mode
sqlite>sqlite3.connect(database)连接数据库
连接数据库database,如果数据库database不存在,则会创建数据库database,并返回Connection object:
In [1]: import sqlite3
In [2]: conn = sqlite3.connect('data.db')
In [3]: conn
Out[3]: <sqlite3.Connection at 0x230e4801e30>同时也发现生成了文件data.db。
也可以在内存中创建数据库:
In [4]: conn_mem = sqlite3.connect(':memory:')
In [5]: conn_mem
Out[5]: <sqlite3.Connection at 0x230e4a84e30>sqlite3.cursor()创建游标对象
一旦建立了Connection连接,就可以创建一个Cursor对象:
In [6]: curs = conn.cursor()
In [7]: curs
Out[7]: <sqlite3.Cursor at 0x230e4b39340>sqlite3.Cursor.execute(sql[, parameters])执行SQL语句
通过调用Cursor对象的execute()方法来执行SQL命令:
# 创建数据表stocks
In [8]: curs.execute('''CREATE TABLE stocks (date text, trans text, symbol text, qty real, price real)''')
Out[8]: <sqlite3.Cursor at 0x230e4b39340>
# 插入一条数据到表stocks中
In [9]: curs.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY','RHAT',100,35.14)")
Out[9]: <sqlite3.Cursor at 0x230e4b39340>sqlite3.Connection.commit(sql[, parameters])提交当前的事务
将创建数据表stocks和插入数据事务提交到数据库:
In [10]: conn.commit()此时数据库中就新建了表stocks,并有一条数据,查询数据库里面的信息:
$ sqlite3 data.db
SQLite version 3.27.2 2019-02-25 16:06:06
Enter ".help" for usage hints.
sqlite> .header on
sqlite> .mode column
sqlite> .tables
stocks
sqlite> select * from stocks;
date trans symbol qty price
---------- ---------- ---------- ---------- ----------
2006-01-05 BUY RHAT 100.0 35.14
sqlite>sqlite3.Connection.close()关闭数据库连接,在关闭数据库连接前,请确保所有的事务都被commit()提交,close()不会自动调用commit()提交事务
关闭数据库连接,可以发现在关闭数据库连接后,再去执行execute去查询数据库信息会报 ProgrammingError 异常:
In [11]: conn.close()
In [12]: conn
Out[12]: <sqlite3.Connection at 0x230e4801e30>
In [13]: curs
Out[13]: <sqlite3.Cursor at 0x230e4b39340>
In [14]: curs.execute("SELECT * FROM stocks")
---------------------------------------------------------------------------
ProgrammingError Traceback (most recent call last)
<ipython-input-14-9a842a1f84e1> in <module>
----> 1 curs.execute("SELECT * FROM stocks")
ProgrammingError: Cannot operate on a closed database.重新连接数据库:
In [15]: conn = sqlite3.connect('data.db')
In [16]: curs = conn.cursor()为防止数据库注入攻击,不要使用Python字符串操作:
# Never do this -- insecure! 这种方式不安全
In [17]: symbol = 'RHAT'
# ``SELECT`` 查询语句
In [18]: curs.execute("SELECT * FROM stocks WHERE symbol = '%s'" % symbol)
Out[18]: <sqlite3.Cursor at 0x230e4b392d0>sqlite3.Cursor.fetchone()获取查询结果集中的下一行数据,没有数据的话返回None
查询一行数据:
In [19]: print(curs.fetchone())
('2006-01-05', 'BUY', 'RHAT', 100.0, 35.14)应该使用?问号作为占位符,并使用tuple元组作为第二个参数:
# Do this instead 使用元组以及?问号占位符
In [20]: t = ('RHAT',)
In [21]: curs.execute('SELECT * FROM stocks WHERE symbol=?', t)
Out[21]: <sqlite3.Cursor at 0x230e4b392d0>
In [22]: print(curs.fetchone())
('2006-01-05', 'BUY', 'RHAT', 100.0, 35.14)
# Larger example that inserts many records at a time
In [23]: purchases = [('2006-03-28', 'BUY', 'IBM', 1000, 45.00), ('2006-04-05', 'BUY', 'MSFT', 1000, 72.00), ('2006-04-06', 'SELL', 'IBM', 500, 53.00),]sqlite3.Cursor.executemany(sql, seq_of_parameters)对seq_of_parameters中的所有参数进行映射生成SQL语句,并执行SQL命令
将purchases中的数据映射到 INSERT 插入语句中:
In [24]: curs.executemany('INSERT INTO stocks VALUES (?,?,?,?,?)', purchases)
Out[24]: <sqlite3.Cursor at 0x230e4b392d0>
In [25]: curs.execute('SELECT * FROM stocks')
Out[25]: <sqlite3.Cursor at 0x230e4b392d0>sqlite3.Cursor.fetchone()获取查询结果集中的下一行数据,没有数据的话返回None
查询一行数据:
In [26]: print(curs.fetchone())
('2006-01-05', 'BUY', 'RHAT', 100.0, 35.14)sqlite3.Cursor.fetchall()获取查询结果集中所有(剩余)的行,返回一个列表,没有数据的话返回None
查询剩余行的数据:
In [27]: print(curs.fetchall())
[('2006-03-28', 'BUY', 'IBM', 1000.0, 45.0), ('2006-04-05', 'BUY', 'MSFT', 1000.0, 72.0), ('2006-04-06', 'SELL', 'IBM', 500.0, 53.0)]- 要在执行
SELECT语句后检索数据,可以将游标视为iterator迭代器,调用游标的fetchone()方法以检索单个匹配行,或调用fetchall()以获取所有匹配行的列表。
下面将游标作为一个 iterator 迭代器:
In [28]: for row in curs.execute('SELECT * FROM stocks ORDER BY price'):
...: print(row)
...:
('2006-01-05', 'BUY', 'RHAT', 100.0, 35.14)
('2006-03-28', 'BUY', 'IBM', 1000.0, 45.0)
('2006-04-06', 'SELL', 'IBM', 500.0, 53.0)
('2006-04-05', 'BUY', 'MSFT', 1000.0, 72.0)提交事务,将新插入的三行数据保存到数据库中:
In [29]: conn.commit()sqlite3.Connection.total_changes返回自打开数据库连接以来已修改,插入或删除的数据库行的总数。
查询插入的数据行数:
In [30]: conn.total_changes
Out[30]: 3在SQLite3中查询数据:
sqlite> select * from stocks order by price;
date trans symbol qty price
---------- ---------- ---------- ---------- ----------
2006-01-05 BUY RHAT 100.0 35.14
2006-03-28 BUY IBM 1000.0 45.0
2006-04-06 SELL IBM 500.0 53.0
2006-04-05 BUY MSFT 1000.0 72.0
sqlite>sqlite3.Cursor.executescript(sql_script)将SQL语句写成脚本,并执行脚本,会直接COMMIT提交事务。它首先发出一个COMMIT语句,然后执行它作为参数获取的SQL脚本。
以下脚本先创建person表和book表,并向book表中插入一条数据:
In [31]: curs.executescript("""
...: create table person(
...: firstname,
...: lastname,
...: age
...: );
...:
...: create table book(
...: title,
...: author,
...: published
...: );
...:
...: insert into book(title, author, published)
...: values (
...: 'Dirk Gently''s Holistic Detective Agency',
...: 'Douglas Adams',
...: 1987
...: );
...: """)
Out[31]: <sqlite3.Cursor at 0x230e4b392d0>在SQLite3中查询数据:
sqlite> .tables
book person stocks
sqlite> select * from book;
title author published
--------------------------------------- ------------- ----------
Dirk Gently's Holistic Detective Agency Douglas Adams 1987
sqlite>说明执行 curs.executescript(sql_script) 脚本不需要另外手动提交事务。
Connection objects可以用作自动提交或回滚事务的with上下文管理器。 如果发生异常,则回滚事务; 否则,提交事务成功
使用with上下文管理器,自动提交事务
In [1]: import sqlite3
In [2]: auto_conn = sqlite3.connect(":memory:")
# 定义firstname unique唯一不能重复
In [3]: auto_conn.execute("create table person (id integer primary key, firstname varchar unique)")
Out[3]: <sqlite3.Cursor at 0x1ea33f65650>
# 第一次自动提交事务,并插入数据到数据库中
In [4]: with auto_conn:
...: auto_conn.execute("insert into person(firstname) values (?)", ("Joe",))
...:
In [5]: curs = auto_conn.cursor()
In [6]: curs.execute('select * from person')
Out[6]: <sqlite3.Cursor at 0x1ea33f65c00>
# 查询刚才的with上下文是否插入数据
In [7]: curs.fetchone()
Out[7]: (1, 'Joe')
# 再次使用上下文插入数据,会产生 ``sqlite3.IntegrityError`` 异常,使用try except捕获异常
In [8]: try:
...: with auto_conn:
...: auto_conn.execute("insert into person(firstname) values (?)", ("Joe",))
...: except sqlite3.IntegrityError:
...: print("couldn't add Joe twice")
...:
couldn't add Joe twice
# 关闭连接
In [9]: auto_conn.close()pymysql处理mysql数据库
安装
pymysql:pip install PyMySQL==0.7.5安装
MariaDB,MariaDB下载链接: https://downloads.mariadb.org/, 安装请参考 MariaDB安装与使用准备数据库数据表
创建数据库data和数据表users:
$ mysql -uroot -proot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.14-MariaDB mariadb.org binary distribution
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.001 sec)
MariaDB [(none)]> create database data;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| data |
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.001 sec)
MariaDB [(none)]> use data;
Database changed
MariaDB [data]> show tables;
Empty set (0.001 sec)
MariaDB [data]> CREATE TABLE `users` (
-> `id` int(11) NOT NULL AUTO_INCREMENT,
-> `email` varchar(255) COLLATE utf8_bin NOT NULL,
-> `password` varchar(255) COLLATE utf8_bin NOT NULL,
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
-> AUTO_INCREMENT=1 ;
Query OK, 0 rows affected (0.059 sec)
MariaDB [data]> show tables;
+----------------+
| Tables_in_data |
+----------------+
| users |
+----------------+
1 row in set (0.000 sec)
MariaDB [data]> select * from users;
Empty set (0.000 sec)pymysql.connect连接数据库
语法:
pymysql.connections.Connection(host=None, user=None, password='', database=None, port=0, unix_socket=None, charset='', sql_mode=None, read_default_file=None, conv=None, use_unicode=None, client_flag=0, cursorclass=<class 'pymysql.cursors.Cursor'>, init_command=None, connect_timeout=10, ssl=None, read_default_group=None, compress=None, named_pipe=None, autocommit=False, db=None, passwd=None, local_infile=False, max_allowed_packet=16777216, defer_connect=False, auth_plugin_map=None, read_timeout=None, write_timeout=None, bind_address=None, binary_prefix=False, program_name=None, server_public_key=None)
Parameters:
host – Host where the database server is located 数据库服务主机
user – Username to log in as 登陆用户名
password – Password to use. 登陆密码
database – Database to use, None to not use a particular one. 数据库名称
port – MySQL port to use, default is usually OK. (default: 3306) 端口号
bind_address – When the client has multiple network interfaces, specify the interface from which to connect to the host. Argument can be a hostname or an IP address.
unix_socket – Optionally, you can use a unix socket rather than TCP/IP.
read_timeout – The timeout for reading from the connection in seconds (default: None - no timeout)
write_timeout – The timeout for writing to the connection in seconds (default: None - no timeout)
charset – Charset you want to use. 编码格式
sql_mode – Default SQL_MODE to use.
read_default_file – Specifies my.cnf file to read these parameters from under the [client] section.
conv – Conversion dictionary to use instead of the default one. This is used to provide custom marshalling and unmarshalling of types. See converters.
use_unicode – Whether or not to default to unicode strings. This option defaults to true for Py3k.
client_flag – Custom flags to send to MySQL. Find potential values in constants.CLIENT.
cursorclass – Custom cursor class to use.
init_command – Initial SQL statement to run when connection is established.
connect_timeout – Timeout before throwing an exception when connecting. (default: 10, min: 1, max: 31536000)
ssl – A dict of arguments similar to mysql_ssl_set()’s parameters.
read_default_group – Group to read from in the configuration file.
compress – Not supported
named_pipe – Not supported
autocommit – Autocommit mode. None means use server default. (default: False) 自动提交事务
local_infile – Boolean to enable the use of LOAD DATA LOCAL command. (default: False)
max_allowed_packet – Max size of packet sent to server in bytes. (default: 16MB) Only used to limit size of “LOAD LOCAL INFILE” data packet smaller than default (16KB).
defer_connect – Don’t explicitly connect on construction - wait for connect call. (default: False)
auth_plugin_map – A dict of plugin names to a class that processes that plugin. The class will take the Connection object as the argument to the constructor. The class needs an authenticate method taking an authentication packet as an argument. For the dialog plugin, a prompt(echo, prompt) method can be used (if no authenticate method) for returning a string from the user. (experimental)
server_public_key – SHA256 authentication plugin public key value. (default: None)
db – Alias for database. (for compatibility to MySQLdb) 数据库名称
passwd – Alias for password. (for compatibility to MySQLdb) 登陆密码
binary_prefix – Add _binary prefix on bytes and bytearray. (default: False)连接MariaDB服务,使用data数据库:
In [1]: import pymysql
In [2]: connection = pymysql.connect(host='localhost',
...: user='root',
...: password='root',
...: db='data',
...: charset='utf8',
...: cursorclass=pymysql.cursors.DictCursor)
In [3]: connection
Out[3]: <pymysql.connections.Connection at 0x15759136518>connection.cursor(cursor=None)创建游标对象connection.commit()提交事务connection.close()关闭连接
创建游标,并执行SQL语句:
In [4]: try:
...: with connection.cursor() as cursor: # 创建游标
...: sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)" # 构建SQL插入语句
...: cursor.execute(sql, ('webmaster@python.org', 'very-secret')) # 执行SQL语句
...:
...: connection.commit() # 提交事务
...: finally:
...: connection.close() # 关闭连接
...:在MariaDB中查询数据:
MariaDB [data]> select * from users;
+----+----------------------+-------------+
| id | email | password |
+----+----------------------+-------------+
| 1 | webmaster@python.org | very-secret |
+----+----------------------+-------------+
1 row in set (0.000 sec)
MariaDB [data]>pymysql.cursors.Cursor.fetchone()查询一行数据
查询刚才插入的数据:
In [5]: with connection.cursor() as cursor:
...: sql = "SELECT id, password FROM users WHERE email= %s "
...: cursor.execute(sql, ('webmaster@python.org'))
...: print(cursor.fetchone())
...:
{'id': 1, 'password': 'very-secret'}connection.select_db(db)修改当前正在处理的数据库pymysql.cursors.Cursor.fetchall()查询剩余行的所有数据
修改数据表为mysql,并查询数据库中的表:
In [6]: connection
Out[6]: <pymysql.connections.Connection at 0x157594142e8>
In [7]: connection.select_db('mysql')
In [8]: cursor = connection.cursor()
In [9]: cursor.execute('show tables')
Out[9]: 31
In [10]: cursor.fetchone()
Out[10]: ('column_stats',)
In [11]: cursor.fetchall()
Out[11]:
(('columns_priv',),
('db',),
('event',),
('func',),
('general_log',),
('gtid_slave_pos',),
('help_category',),
('help_keyword',),
('help_relation',),
('help_topic',),
('host',),
('index_stats',),
('innodb_index_stats',),
('innodb_table_stats',),
('plugin',),
('proc',),
('procs_priv',),
('proxies_priv',),
('roles_mapping',),
('servers',),
('slow_log',),
('table_stats',),
('tables_priv',),
('time_zone',),
('time_zone_leap_second',),
('time_zone_name',),
('time_zone_transition',),
('time_zone_transition_type',),
('transaction_registry',),
('user',))在MariaDB中查询数据:
MariaDB [data]> use mysql;
Database changed
MariaDB [mysql]> show tables;
+---------------------------+
| Tables_in_mysql |
+---------------------------+
| column_stats |
| columns_priv |
| db |
| event |
| func |
| general_log |
| gtid_slave_pos |
| help_category |
| help_keyword |
| help_relation |
| help_topic |
| host |
| index_stats |
| innodb_index_stats |
| innodb_table_stats |
| plugin |
| proc |
| procs_priv |
| proxies_priv |
| roles_mapping |
| servers |
| slow_log |
| table_stats |
| tables_priv |
| time_zone |
| time_zone_leap_second |
| time_zone_name |
| time_zone_transition |
| time_zone_transition_type |
| transaction_registry |
| user |
+---------------------------+
31 rows in set (0.001 sec)
MariaDB [mysql]>SQLAlchemy ORM对象关系映射处理数据库
Object Relational Mapper对象关系映射,ORM将数据库中的表与面向对象语言中的类建立了一种对应关系。这样,我们要操作数据库,数据库中的表或者表中的一条记录就可以直接通过操作类或者类实例来完成。
查看SQLAlchemy的版本
通过sqlalchemy.__version__查看SQLAlchemy的版本:
In [1]: import sqlalchemy
In [2]: sqlalchemy.__version__
Out[2]: '1.3.2'使用create_engine()连接数据库
echo=True参数表明开启SQLAlchemy日志记录,启用后会生成所有SQL语句。create_engine()的返回值是Engine的一个实例,它表示数据库的核心接口,使用不同的数据库处理模块处理的dialect最后生成的Engine实例不同。- 当第一次使用
create_engine()连接时,引擎实际上还没有尝试连接到数据库(Lazy Connecting懒惰连接)。只有在第一次要求它对数据库执行任务时才会连接数据库。 - 第一次调用
Engine.execute()或Engine.connect()这样的方法时,Engine会建立与数据库的真实DBAPI连接,然后用于发出SQL。 - 通常不会直接使用
Engine,而是通过使用ORM来间接使用Engine。
使用 create_engine() 连接数据库。以下是连接内存数据库SQLite:
In [3]: from sqlalchemy import create_engine
In [4]: engine = create_engine('sqlite:///:memory:', echo=True)
In [5]: engine
Out[5]: Engine(sqlite:///:memory:)引擎Engine的方法和属性:
engine.
begin() dialect drop execution_options logging_name run_callable transaction
connect dispatch echo get_execution_options name scalar update_execution_options
contextual_connect dispose engine has_table pool schema_for_object url
create driver execute logger raw_connection table_names查看engine的一些属性:
In [6]: engine.url
Out[6]: sqlite:///:memory:
In [7]: engine.driver
Out[7]: 'pysqlite'
In [8]: engine.engine
Out[8]: Engine(sqlite:///:memory:)
In [9]: engine.logger
Out[9]: <sqlalchemy.log.InstanceLogger at 0x225a2ac98d0>
In [10]: engine.name
Out[10]: 'sqlite'
In [11]: engine.logging_name
In [12]: engine.echo
Out[12]: True
In [13]: engine.pool
Out[13]: <sqlalchemy.pool.impl.SingletonThreadPool at 0x225a2ac3eb8>
In [14]: engine.dialect
Out[14]: <sqlalchemy.dialects.sqlite.pysqlite.SQLiteDialect_pysqlite at 0x225a27b1f60>Engine是任何SQLAlchemy应用程序的起点。 它是实际数据库及其DBAPI的基础,通过Pool连接池和Dialect方言传递给SQLAlchemy应用程序,该Dialect方言描述了如何与特定类型的数据库DBAPI组合进行通信。
SQLAlchemy Engine的架构如下:
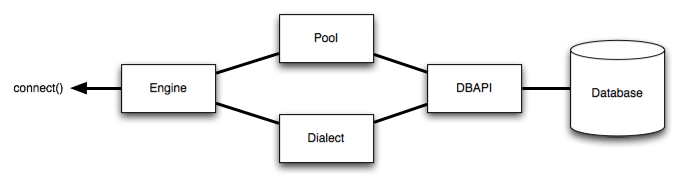
- SQLAlchemy
create_engine()函数基于数据库URL(Database Url)来生成Engine对象,URL通常包含username用户名,password密码,hostname主机名,database name数据库名称以及用于其他配置的可选关键字参数。
数据库URL的典型形式是:
dialect+driver://username:password@host:port/databasedialect方言是SQLAlchemy方言的标识名称,如sqlite,mysql,postgresql,oracle,或mssql。driver是使用全小写字母连接到数据库的DBAPI的名称。URL中特殊的字符需要使用URL编码。
可以使用urllib模块生成字符的URL编码:
In [1]: import urllib
In [2]: urllib.parse.quote_plus('kx%jj5/g')
Out[2]: 'kx%25jj5%2Fg'MYSQL dialect方言示例:
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# PyMySQL
engine = create_engine('mysql+pymysql://scott:tiger@localhost/foo')SQlite dialect方言示例:
# 相对路径
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine('sqlite:///foo.db')
# 绝对路径
# Unix/Mac - 4 initial slashes in total
engine = create_engine('sqlite:////absolute/path/to/foo.db')
# Windows
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
# Windows alternative using raw string
engine = create_engine(r'sqlite:///C:\path\to\foo.db')
# 在内存中创建数据库
engine = create_engine('sqlite://')
engine = create_engine('sqlite:///:memory:')其他数据库如PostgreSQL 、 Oracle 、 Microsoft SQL Server等请参考Database Urls 。
- 声明映射。使用
ORM时,配置过程首先描述我们将要处理的数据库表,然后定义我们自己的类,这些类将映射到这些表。在现代SQLAlchemy中,这两个任务通常使用称为Declarative的系统一起执行,这允许我们创建包含指令的类,以描述它们将映射到的实际数据库表。 - 使用
declarative_base()函数创建基类。
创建基类:
>>> from sqlalchemy.ext.declarative import declarative_base
>>> Base = declarative_base()
>>> Base
sqlalchemy.ext.declarative.api.Base- 基于
Base基类可以定义任意多的映射类。 - 定义映射类时,需要指定表的名称(table name),列名(names of columns)以及数据类型(datatypes of columns)。
- 类定义时需要定义
__tablename__属性,表明表的名称。 - 类定义时需要至少一个
Column列,用于定义表的主键,SQLAlchemy不会自动确认哪列是主键,并使用primary_key=True表明该字段是主键。 __repr__()方法是可选的(optional),用于改善打印实例输出。- 通过声明系统构建的映射类定义的有关表的信息,称为表元数据。
- 映射类是一个
Table对象,可以通过检查__table__属性来看到这个对象。
定义一个User类,并映射到user表中去:
>>> from sqlalchemy import Column, Integer, String
>>> class User(Base):
... __tablename__ = 'users'
...
... id = Column(Integer, primary_key=True)
... name = Column(String)
... fullname = Column(String)
... nickname = Column(String)
...
... def __repr__(self):
... return "<User(name='%s', fullname='%s', nickname='%s')>" % (
... self.name, self.fullname, self.nickname)
...
>>> User
__main__.User
>>> User.__table__
Table('users', MetaData(bind=None), Column('id', Integer(), table=<users>, primary_key=True, nullable=False), Column('name', String(), table=<users>), Column('fullname', String(), table=<users>), Column('nickname', String(), table=<users>), schema=None)Table对象是一个名为MetaData的较大集合的成员。使用Declarative声明时,可以使用声明性基类的.metadata属性来使用此对象。- 调用
MetaData.create_all()方法来创建数据表。
使用MetaData.create_all()方法来创建数据表:
>>> Base.metadata
MetaData(bind=None)
>>> Base.metadata.create_all(engine)
2019-04-16 22:20:12,488 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2019-04-16 22:20:12,489 INFO sqlalchemy.engine.base.Engine ()
2019-04-16 22:20:12,490 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2019-04-16 22:20:12,490 INFO sqlalchemy.engine.base.Engine ()
2019-04-16 22:20:12,491 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("users")
2019-04-16 22:20:12,492 INFO sqlalchemy.engine.base.Engine ()
2019-04-16 22:20:12,493 INFO sqlalchemy.engine.base.Engine
CREATE TABLE users (
id INTEGER NOT NULL,
name VARCHAR,
fullname VARCHAR,
nickname VARCHAR,
PRIMARY KEY (id)
)
2019-04-16 22:20:12,494 INFO sqlalchemy.engine.base.Engine ()
2019-04-16 22:20:12,495 INFO sqlalchemy.engine.base.Engine COMMIT
>>>由于在定义engine时,开启了echo=True功能,因此在创建表时会显示生成的日志信息。
- 实例化映射类就可以创建一个表对象。
创建User实例:
>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
>>> ed_user
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>
>>> ed_user.name
'ed'
>>> ed_user.fullname
'Ed Jones'
>>> ed_user.nickname
'edsnickname'
>>> str(ed_user.id)
'None'虽然在构建函数中未指定id的值,但是当我们访问它时,id属性仍然会产生None值。SQLAlchemy的检测通常在首次访问时为列映射属性生成此默认值。
- 创建
Session会话,通过Session处理数据库。 - 使用
sessionmaker创建Session会话。 - 如果创建了
Engine对象engine,在创建Session时可以指定Engine对象。
创建Session会话:
>>> from sqlalchemy.orm import sessionmaker
>>> Session = sessionmaker(bind=engine)
>>> session = Session()
>>> Session
sessionmaker(class_='Session', bind=Engine(sqlite:///:memory:), autoflush=True, autocommit=False, expire_on_commit=True)
>>> session
<sqlalchemy.orm.session.Session at 0x12ede8477b8>- 万一之前没有定义
Engine对象engine,可以分步定义Session会话。
分步定义Session会话:
>>> Session = sessionmaker()
>>> Session.configure(bind=engine) # once engine is available
>>> session = Session()- 将实例数据写入到
Session会话中,此时Session实例处于挂起(pending)状态,尚未发起任何SQL,并且该对象尚未由数据库中的行表示。 - 在未使用
session.commit()方法前数据不会提交到数据库。 - 使用
session.add(instance)方法添加一条数据。 - 使用
session.add_all(instances)方法添加多条数据。
将一条数据写入到Session会话中:
>>> session.add(ed_user)上面分写入1条数据。
- 使用
Query对象查询数据。
查询数据:
>>> our_user = session.query(User).filter_by(name='ed').first()
2019-04-16 22:55:04,858 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2019-04-16 22:55:04,861 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-16 22:55:04,862 INFO sqlalchemy.engine.base.Engine ('ed', 'Ed Jones', 'eddie')
2019-04-16 22:55:04,863 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-16 22:55:04,864 INFO sqlalchemy.engine.base.Engine ('wendy', 'Wendy Williams', 'windy')
2019-04-16 22:55:04,866 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-16 22:55:04,867 INFO sqlalchemy.engine.base.Engine ('mary', 'Mary Contrary', 'mary')
2019-04-16 22:55:04,868 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-16 22:55:04,870 INFO sqlalchemy.engine.base.Engine ('fred', 'Fred Flintstone', 'freddy')
2019-04-16 22:55:04,872 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name = ?
LIMIT ? OFFSET ?
2019-04-16 22:55:04,872 INFO sqlalchemy.engine.base.Engine ('ed', 1, 0)
>>> our_user
<User(name='ed', fullname='Ed Jones', nickname='eddie')>
>>> ed_user is our_user
True- 使用
session.new获取挂起的数据。 - 使用
session.dirty获取脏数据。
获取挂起数据或脏数据:
>>> session.dirty
IdentitySet([])
>>> session.new
IdentitySet([])再添加多条数据:
>>> session.add_all([
... User(name='wendy', fullname='Wendy Williams', nickname='windy'),
... User(name='mary', fullname='Mary Contrary', nickname='mary'),
... User(name='fred', fullname='Fred Flintstone', nickname='freddy')])上面写入3条数据。
再获取挂起数据或脏数据:
>>> session.dirty
IdentitySet([])
>>> session.new
IdentitySet([<User(name='wendy', fullname='Wendy Williams', nickname='windy')>, <User(name='mary', fullname='Mary Contrary', nickname='mary')>, <User(name='fred', fullname='Fred Flintstone', nickname='freddy')>])修改Ed’s nickname:
>>> ed_user.nickname = 'eddie'再获取挂起数据或脏数据:
>>> session.dirty
IdentitySet([<User(name='ed', fullname='Ed Jones', nickname='eddie')>])
>>> session.new
IdentitySet([<User(name='wendy', fullname='Wendy Williams', nickname='windy')>, <User(name='mary', fullname='Mary Contrary', nickname='mary')>, <User(name='fred', fullname='Fred Flintstone', nickname='freddy')>])- 使用
session.commit()方法将数据提交到数据库。
提交数据,并查询数据:
>>> session.commit()
2019-04-17 20:04:58,364 INFO sqlalchemy.engine.base.Engine UPDATE users SET nickname=? WHERE users.id = ?
2019-04-17 20:04:58,365 INFO sqlalchemy.engine.base.Engine ('eddie', 1)
2019-04-17 20:04:58,365 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-17 20:04:58,365 INFO sqlalchemy.engine.base.Engine ('wendy', 'Wendy Williams', 'windy')
2019-04-17 20:04:58,365 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-17 20:04:58,365 INFO sqlalchemy.engine.base.Engine ('mary', 'Mary Contrary', 'mary')
2019-04-17 20:04:58,366 INFO sqlalchemy.engine.base.Engine INSERT INTO users (name, fullname, nickname) VALUES (?, ?, ?)
2019-04-17 20:04:58,367 INFO sqlalchemy.engine.base.Engine ('fred', 'Fred Flintstone', 'freddy')
2019-04-17 20:04:58,367 INFO sqlalchemy.engine.base.Engine COMMIT
>>> ed_user.id
2019-04-16 22:58:59,226 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2019-04-16 22:58:59,227 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.id = ?
2019-04-16 22:58:59,227 INFO sqlalchemy.engine.base.Engine (1,)
1- 查询数据库数据信息
- 通过
Session的query()方法创建一个Query对象。 - Query对象的常用方法见示例,详细可参考官网Query API
查询users表中的name和fullname相关的数据:
>>> users = session.query(User.name, User.fullname)
>>> users
<sqlalchemy.orm.query.Query at 0x17a37ee4048>
>>> users.column_descriptions # 返回有关此Query将返回的列的元数据
[{'name': 'name',
'type': String(),
'aliased': False,
'expr': <sqlalchemy.orm.attributes.InstrumentedAttribute at 0x17a37ddb570>,
'entity': __main__.User},
{'name': 'fullname',
'type': String(),
'aliased': False,
'expr': <sqlalchemy.orm.attributes.InstrumentedAttribute at 0x17a37ddb620>,
'entity': __main__.User}]
>>> users.count() # 返回此Query将返回的行数
2019-04-18 20:55:52,252 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1
FROM (SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users) AS anon_1
2019-04-18 20:55:52,252 INFO sqlalchemy.engine.base.Engine ()
4
>>> users.all() # 查询所有的数据
2019-04-18 20:56:30,732 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users
2019-04-18 20:56:30,733 INFO sqlalchemy.engine.base.Engine ()
[('ed', 'Ed Jones'),
('wendy', 'Wendy Williams'),
('mary', 'Mary Contrary'),
('fred', 'Fred Flintstone')]
>>> users.first() # 返回第一个查询结果
2019-04-18 21:00:58,964 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users
LIMIT ? OFFSET ?
2019-04-18 21:00:58,967 INFO sqlalchemy.engine.base.Engine (1, 0)
('ed', 'Ed Jones')
>>> users.limit(2) # 限制查询个数
<sqlalchemy.orm.query.Query at 0x17a39d407b8>
>>> users.limit(2).all()
2019-04-18 21:03:01,424 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users
LIMIT ? OFFSET ?
2019-04-18 21:03:01,425 INFO sqlalchemy.engine.base.Engine (2, 0)
[('ed', 'Ed Jones'), ('wendy', 'Wendy Williams')]
>>> users.order_by(User.name) # 按User.name排序
<sqlalchemy.orm.query.Query at 0x17a37e10470>
>>> users.order_by(User.name).all()
2019-04-18 21:06:00,393 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users ORDER BY users.name
2019-04-18 21:06:00,394 INFO sqlalchemy.engine.base.Engine ()
[('ed', 'Ed Jones'),
('fred', 'Fred Flintstone'),
('mary', 'Mary Contrary'),
('wendy', 'Wendy Williams')]
>>> users.filter(User.name == 'mary') # 过滤数据
<sqlalchemy.orm.query.Query at 0x17a37e04898>
>>> users.filter(User.name == 'mary').first()
2019-04-18 21:24:54,028 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users
WHERE users.name = ?
LIMIT ? OFFSET ?
2019-04-18 21:24:54,029 INFO sqlalchemy.engine.base.Engine ('mary', 1, 0)
('mary', 'Mary Contrary')
>>> users.filter_by(name='mary') # 通过key关键字过滤数据
<sqlalchemy.orm.query.Query at 0x17a3a0567f0>
>>> users.filter_by(name='mary').first()
2019-04-18 21:25:55,339 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users
WHERE users.name = ?
LIMIT ? OFFSET ?
2019-04-18 21:25:55,340 INFO sqlalchemy.engine.base.Engine ('mary', 1, 0)
('mary', 'Mary Contrary')
>>> first_user = session.query(User).get(1) # 通过primary key主键返回对象实例
>>> first_user
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>
>>> for name, fullname in session.query(User.name, User.fullname):
... print(name, fullname)
...
2019-04-18 21:40:18,566 INFO sqlalchemy.engine.base.Engine SELECT users.name AS users_name, users.fullname AS users_fullname
FROM users
2019-04-18 21:40:18,567 INFO sqlalchemy.engine.base.Engine ()
ed Ed Jones
wendy Wendy Williams
mary Mary Contrary
fred Fred Flintstone
>>> for row in session.query(User, User.name).all():
... print(row.User, row.name) # 查询到的对象可以像普通Python对象对待
...
2019-04-18 21:42:28,394 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
2019-04-18 21:42:28,395 INFO sqlalchemy.engine.base.Engine ()
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')> ed
<User(name='wendy', fullname='Wendy Williams', nickname='windy')> wendy
<User(name='mary', fullname='Mary Contrary', nickname='mary')> mary
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')> fred
>>> for row in session.query(User.name.label('name_label')).all(): # 可以为查询的column列设置标签名
... print(row.name_label) # 使用标签名
...
2019-04-18 21:43:22,465 INFO sqlalchemy.engine.base.Engine SELECT users.name AS name_label
FROM users
2019-04-18 21:43:22,466 INFO sqlalchemy.engine.base.Engine ()
ed
wendy
mary
fred
>>> from sqlalchemy.orm import aliased
>>> user_alias = aliased(User, name='aliasuser') # 定义别名,即将User类设置别名为aliasuser
>>> user_alias
<AliasedClass at 0x17a37e04c88; User>
>>> for row in session.query(user_alias, user_alias.name).all():
... print(row.aliasuser)
...
2019-04-18 21:50:09,776 INFO sqlalchemy.engine.base.Engine SELECT aliasuser.id AS aliasuser_id, aliasuser.name AS aliasuser_name, aliasuser.fullname AS aliasuser_fullname, aliasuser.nickname AS aliasuser_nickname
FROM users AS aliasuser
2019-04-18 21:50:09,776 INFO sqlalchemy.engine.base.Engine ()
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>
<User(name='mary', fullname='Mary Contrary', nickname='mary')>
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
>>> for u in session.query(User).order_by(User.id)[1:3]: # 使用LIMIT和OFFSET偏移量
... print(u)
...
2019-04-18 21:52:48,402 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users ORDER BY users.id
LIMIT ? OFFSET ?
2019-04-18 21:52:48,403 INFO sqlalchemy.engine.base.Engine (2, 1)
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>
<User(name='mary', fullname='Mary Contrary', nickname='mary')>
>>> for user in session.query(User).filter(User.name=='ed').filter(User.fullname=='Ed Jones'): # 多次过滤
... print(user)
...
2019-04-18 21:55:14,653 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name = ? AND users.fullname = ?
2019-04-18 21:55:14,654 INFO sqlalchemy.engine.base.Engine ('ed', 'Ed Jones')
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>常用过滤运算符
equals==相等not equals!=不相等LIKElike(大小写敏感)像ILIKEilike(大小写不敏感)像INin_在其中NOT IN~ in_不在其中IS NULL== None为空IS NOT NULL!= None不为空AND多级过滤或使用and_()OR多级过滤或使用or_()MATCHmatch匹配,match()使用特定于数据库的MATCH或CONTAINS函数; 它的行为会因后端而异,并且在某些后端(例如SQLite)上不可用。
过滤运算示例:
>>> myquery = session.query(User)
>>> myquery
<sqlalchemy.orm.query.Query at 0x17a39b57908>
>>> myquery.filter(User.name == 'ed')
<sqlalchemy.orm.query.Query at 0x17a39d59dd8>
>>> myquery.filter(User.name == 'ed').all() # 相等
2019-04-18 22:05:45,169 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name = ?
2019-04-18 22:05:45,172 INFO sqlalchemy.engine.base.Engine ('ed',)
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>]
>>> myquery.filter(User.name != 'ed').all() # 不相等
2019-04-18 22:06:37,084 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name != ?
2019-04-18 22:06:37,085 INFO sqlalchemy.engine.base.Engine ('ed',)
[<User(name='wendy', fullname='Wendy Williams', nickname='windy')>,
<User(name='mary', fullname='Mary Contrary', nickname='mary')>,
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>]
>>> myquery.filter(User.name.like('%ed%')).all() # (区分大小写)像
2019-04-18 22:07:11,593 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name LIKE ?
2019-04-18 22:07:11,594 INFO sqlalchemy.engine.base.Engine ('%ed%',)
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>,
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>]
>>> myquery.filter(User.name.ilike('%ed%')).all() # (不区分大小写)像
2019-04-18 22:07:49,114 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE lower(users.name) LIKE lower(?)
2019-04-18 22:07:49,115 INFO sqlalchemy.engine.base.Engine ('%ed%',)
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>,
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>]
>>> myquery.filter(User.name.in_(['ed', 'wendy', 'jack'])).all() # 在其中
2019-04-18 22:09:00,462 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name IN (?, ?, ?)
2019-04-18 22:09:00,463 INFO sqlalchemy.engine.base.Engine ('ed', 'wendy', 'jack')
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>,
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>]
>>> myquery.filter(~User.name.in_(['ed', 'wendy', 'jack'])).all() # 不在其中
2019-04-18 22:10:06,110 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name NOT IN (?, ?, ?)
2019-04-18 22:10:06,111 INFO sqlalchemy.engine.base.Engine ('ed', 'wendy', 'jack')
[<User(name='mary', fullname='Mary Contrary', nickname='mary')>,
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>]
>>> myquery.filter(User.name == None).all() # 是空
2019-04-18 22:11:13,807 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name IS NULL
2019-04-18 22:11:13,808 INFO sqlalchemy.engine.base.Engine ()
[]
>>> myquery.filter(User.name != None).all() # 非空
2019-04-18 22:11:19,570 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name IS NOT NULL
2019-04-18 22:11:19,571 INFO sqlalchemy.engine.base.Engine ()
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>,
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>,
<User(name='mary', fullname='Mary Contrary', nickname='mary')>,
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>]
>>> from sqlalchemy import and_
>>> myquery.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones'))
<sqlalchemy.orm.query.Query at 0x17a39d54f98>
>>> myquery.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones')).all() # AND且操作
2019-04-18 22:12:24,261 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name = ? AND users.fullname = ?
2019-04-18 22:12:24,261 INFO sqlalchemy.engine.base.Engine ('ed', 'Ed Jones')
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>]
>>> myquery.filter(User.name == 'ed', User.fullname == 'Ed Jones').all()
2019-04-18 22:13:35,250 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name = ? AND users.fullname = ?
2019-04-18 22:13:35,251 INFO sqlalchemy.engine.base.Engine ('ed', 'Ed Jones')
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>]
>>> from sqlalchemy import or_
>>> myquery.filter(or_(User.name == 'ed', User.name == 'wendy'))
<sqlalchemy.orm.query.Query at 0x17a39d4ac88>
>>> myquery.filter(or_(User.name == 'ed', User.name == 'wendy')).all() # OR或操作
2019-04-18 22:14:16,643 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE users.name = ? OR users.name = ?
2019-04-18 22:14:16,645 INFO sqlalchemy.engine.base.Engine ('ed', 'wendy')
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>,
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>]使用文本SQL
- 可以使用
text()来构建文本SQL
使用文本SQL:
>>> myquery.filter(text("id<3")).order_by(text('id')).all()
2019-04-18 22:22:06,749 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE id<3 ORDER BY id
2019-04-18 22:22:06,750 INFO sqlalchemy.engine.base.Engine ()
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>,
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>]
>>> for user in myquery.filter(text("id<3")).order_by(text('id')).all():
... print(user.id, user.name)
...
2019-04-18 22:22:54,586 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE id<3 ORDER BY id
2019-04-18 22:22:54,587 INFO sqlalchemy.engine.base.Engine ()
1 ed
2 wendy- 可以在字符串的SQL中使用冒号来指定绑定参数,需要使用
params()方法。
使用冒号绑定参数:
>>> myquery.filter(text("id<:value and name=:name")).params(value=224, name='fred').order_by(User.id).one()
2019-04-18 22:25:20,752 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.nickname AS users_nickname
FROM users
WHERE id<? and name=? ORDER BY users.id
2019-04-18 22:25:20,752 INFO sqlalchemy.engine.base.Engine (224, 'fred')
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>- 要使用完全基于字符串的语句,需要将完整语句的
text()传递给from_statement()函数。 - 如果没有其他说明符,字符串SQL中的列将根据名称与模型列匹配。
例如下面我们只使用星号表示加载所有列:
>>> myquery.from_statement(text("SELECT * FROM users where name=:name")).params(name='ed').all()
2019-04-18 22:30:43,455 INFO sqlalchemy.engine.base.Engine SELECT * FROM users where name=?
2019-04-18 22:30:43,455 INFO sqlalchemy.engine.base.Engine ('ed',)
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>]- 匹配名称上的列适用于简单的情况,但在处理包含重复列名的复杂语句或使用不易与特定名称匹配的匿名ORM构造时可能会变得难以处理。
查询指定列的数据:
>>> stmt = text("SELECT name, id, fullname, nickname FROM users where name=:name")
>>> stmt = stmt.columns(User.name, User.id, User.fullname, User.nickname)
>>> myquery.from_statement(stmt).params(name='ed').all()
2019-04-18 22:34:44,974 INFO sqlalchemy.engine.base.Engine SELECT name, id, fullname, nickname FROM users where name=?
2019-04-18 22:34:44,975 INFO sqlalchemy.engine.base.Engine ('ed',)
[<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>]通过将SQLite数据保存到本地文件sqlalchemy.db中,创建数据库信息:
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///sqlalchemy.db')
>>> from sqlalchemy.ext.declarative import declarative_base
>>> Base = declarative_base()
>>> from sqlalchemy import Column, Integer, String
>>> class User(Base):
... __tablename__ = 'users'
...
... id = Column(Integer, primary_key=True)
... name = Column(String)
... fullname = Column(String)
... nickname = Column(String)
...
... def __repr__(self):
... return "<User(name='%s', fullname='%s', nickname='%s')>" % (
... self.name, self.fullname, self.nickname)
...
>>> User
__main__.User
>>> Base.metadata.create_all(engine)
>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
>>> from sqlalchemy.orm import sessionmaker
>>> Session = sessionmaker(bind=engine)
>>> session = Session()
>>> session.add(ed_user)
>>> session.add_all([
... User(name='wendy', fullname='Wendy Williams', nickname='windy'),
... User(name='mary', fullname='Mary Contrary', nickname='mary'),
... User(name='fred', fullname='Fred Flintstone', nickname='freddy')])
>>> session.commit()
>>> users = session.query(User.name, User.fullname)
>>> users.all()
[('ed', 'Ed Jones'),
('wendy', 'Wendy Williams'),
('mary', 'Mary Contrary'),
('fred', 'Fred Flintstone')]统计数量
- 使用
Query对象的count()方法。 - 使用
sqlalchemy的func构造器的count()方法,这种方法对子查询更方便。
统计查询数据的数量:
>>> session.query(User).filter(User.name.like('%ed')).count()
2
>>> from sqlalchemy import func
>>> session.query(func.count(User.name), User.name).group_by(User.name).all()
[(1, 'ed'), (1, 'fred'), (1, 'mary'), (1, 'wendy')]
>>> session.query(func.count('*')).select_from(User).scalar() # 使用select_from方法计数,等价于在数据库中执行"SELECT count(*) FROM table"
4
>>> session.query(func.count(User.id)).scalar() # 如果我们直接用User主键表示计数,则可以删除select_from()的用法
4建立相对关系(Relationship)
- 建立双向关系:在
relationship()指令中,参数relationship.back_populates被指定为引用补充属性名称,通过这样做,每个relationship()可以建立两个类之间的双向关系。 - 使用双向关系时,在一个方向上添加的元素会自动在另一个方向上可见。
考虑添加第二张表address,用于存储用户的邮件地址,定义一个Address类,建立一个one to many一对多的关系模型:
>>> from sqlalchemy import ForeignKey
>>> from sqlalchemy.orm import relationship
>>> class Address(Base):
... __tablename__ = 'addresses'
... id = Column(Integer, primary_key=True) # 设置id为主键
... email_address = Column(String, nullable=False) # 设置email地址为String类型,非空
... user_id = Column(Integer, ForeignKey('users.id')) # 设置user_id,外键是users表中的id
...
... user = relationship("User", back_populates="addresses") # 建立相对关系,告诉ORM使用Address.user属性将Address类本身链接到User类,使用Address.user则可以访问到地址对应的User类
...
... def __repr__(self):
... return "<Address(email_address='%s')>" % self.email_address
...
>>> User.addresses = relationship("Address", order_by=Address.id, back_populates="user") # 将User.addresses映射到Address类的id属性上,通过User.addresses可以获取到用户所有的邮件地址的id列表
>>> Address
__main__.Address
>>> User
__main__.User
>>> Base.metadata.create_all(engine)创建表了后,在SQLite3中查看已经新建了addresses表:
sqlite> .table
addresses users
sqlite>使用相关对象,创建一个新的User实例,并添加邮件地址:
>>> jack = User(name='jack', fullname='Jack Bean', nickname='gjffdd')
>>> jack.addresses
[]
>>> jack.addresses = [Address(email_address='jack@google.com'), Address(email_address='j25@yahoo.com')]
>>> jack.addresses[0]
<Address(email_address='jack@google.com')>
>>> jack.addresses[1]
<Address(email_address='j25@yahoo.com')>
>>> jack.addresses[0].user
<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>
>>> jack.addresses[1].user
<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>- 添加数据到数据库时,会使用
cascading级联会话同时添加对象到数据库。
将用户jack添加到数据库中,由于级联操作,会自动将Address地址相关数据添加到数据库:
>>> session.add(jack)
>>> session.commit()在SQLite3中查看users表和addresses表信息:
sqlite> select * from addresses;
1|jack@google.com|5
2|j25@yahoo.com|5
sqlite> select * from users;
1|ed|Ed Jones|edsnickname
2|wendy|Wendy Williams|windy
3|mary|Mary Contrary|mary
4|fred|Fred Flintstone|freddy
5|jack|Jack Bean|gjffdd
sqlite>使用join进行联合查询
- 使用
Query.join()方法最容易实现实际的SQL JOIN语法。
使用 Query.filter() 在User和Address之间构造一个简单的隐式连接,并使用 Query.join() 方法实现连接:
>>> for u, a in session.query(User, Address).\
... filter(User.id==Address.user_id).\
... filter(Address.email_address=='jack@google.com').\
... all():
... print(u)
... print(a)
...
<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>
<Address(email_address='jack@google.com')>
>>> session.query(User).join(Address).\
... filter(Address.email_address=='jack@google.com').\
... all()
[<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>]Query.join()知道如何在User和Address之间进行连接,因为它们之间只有一个外键。
如果没有外键或有多个外键时,使用以下方式来进行连接:
query.join(Address, User.id==Address.user_id) # explicit condition [ 明确的条件]
query.join(User.addresses) # specify relationship from left to right [ 从左到右指定关系]
query.join(Address, User.addresses) # same, with explicit target [ 同样,有明确的目标]
query.join('addresses') # same, using a string [ 同样,使用字符串]使用aliased对表名进行重命名
使用aliased对表名进行重命名,这样可以对表名使用一次或多次。
对Address表进行重命名:
>>> for username, email1, email2 in \
... session.query(User.name, adalias1.email_address, adalias2.email_address). \
... join(adalias1, User.addresses).join(adalias2, User.addresses). \
... filter(adalias1.email_address=='jack@google.com'). \
... filter(adalias2.email_address=='j25@yahoo.com'):
... print(username, email1, email2)
...
jack jack@google.com j25@yahoo.com使用session.delete(instance)删除instance实例数据
SQLAlchemy不会自动级联删除(SQLAlchemy doesn’t assume that deletes cascade),必须要明确指定才会cascade级联删除。- 级联操作相关请参考官网说明 SQLAlchemy 1.3 Documentation:Cascades
删除用户jack:
>>> jack
<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>
>>> session.delete(jack)
>>> session.query(User).filter_by(name='jack').count()
0
>>> session.query(Address).filter(Address.email_address.in_(['jack@google.com', 'j25@yahoo.com'])).count()
2在SQLite3中查看users表和addresses表信息:
sqlite> select * from addresses;
1|jack@google.com|5
2|j25@yahoo.com|5
sqlite> select * from users;
1|ed|Ed Jones|edsnickname
2|wendy|Wendy Williams|windy
3|mary|Mary Contrary|mary
4|fred|Fred Flintstone|freddy
5|jack|Jack Bean|gjffdd
sqlite>说明此时jack并没有被删除掉。
使用session.commit()提交事务
>>> session.commit()再在SQLite3中查看users表和addresses表信息:
sqlite> select * from addresses;
1|jack@google.com|5
2|j25@yahoo.com|5
sqlite> select * from users;
1|ed|Ed Jones|edsnickname
2|wendy|Wendy Williams|windy
3|mary|Mary Contrary|mary
4|fred|Fred Flintstone|freddy
sqlite>说明jack用户已经从数据库中删除掉,但其email邮箱信息并不会自动删除。
懒人包dataset处理数据库
在Python中,数据库并不是存储大量结构化数据的最简单的解决方案。dataset提供了一个简单的抽象层(可以删除大多数直接的SQL语句而无需完整的ORM模型),本质上,数据库可以像JSON文件或NoSQL存储一样使用。
dataset的安装
使用pip安装:
$ pip install dataset
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Collecting dataset
Downloading http://mirrors.aliyun.com/pypi/packages/d5/02/a4c77a15d004f1307a579e577974fa9292a63e93abff3e40ad993cf597c7/dataset-1.1.2-py2.py3-none-any.whl
Collecting alembic>=0.6.2 (from dataset)
Downloading http://mirrors.aliyun.com/pypi/packages/fc/42/8729e2491fa9b8eae160d1cbb429f61712bfc2d779816488c25cfdabf7b8/alembic-1.0.9.tar.gz (1.0MB)
100% |████████████████████████████████| 1.0MB 3.9MB/s
Requirement already satisfied: six>=1.11.0 in d:\programfiles\python362\lib\site-packages (from dataset) (1.12.0)
Requirement already satisfied: sqlalchemy>=1.1.2 in d:\programfiles\python362\lib\site-packages (from dataset) (1.3.2)
Collecting Mako (from alembic>=0.6.2->dataset)
Downloading http://mirrors.aliyun.com/pypi/packages/a1/bb/f4e5c056e883915c37bb5fb6fab7f00a923c395674f83bfb45c9ecf836b6/Mako-1.0.9.tar.gz (459kB)
100% |████████████████████████████████| 460kB 10.3MB/s
Collecting python-editor>=0.3 (from alembic>=0.6.2->dataset)
Downloading http://mirrors.aliyun.com/pypi/packages/c6/d3/201fc3abe391bbae6606e6f1d598c15d367033332bd54352b12f35513717/python_editor-1.0.4-py3-none-any.whl
Requirement already satisfied: python-dateutil in d:\programfiles\python362\lib\site-packages (from alembic>=0.6.2->dataset) (2.8.0)
Requirement already satisfied: MarkupSafe>=0.9.2 in d:\programfiles\python362\lib\site-packages (from Mako->alembic>=0.6.2->dataset) (1.1.1)
Installing collected packages: Mako, python-editor, alembic, dataset
Running setup.py install for Mako ... done
Running setup.py install for alembic ... done
Successfully installed Mako-1.0.9 alembic-1.0.9 dataset-1.1.2 python-editor-1.0.4使用dataset
导入dataset包:
>>> import dataset- 使用
dataset.connect创建数据库连接。 dataset__init__文件中只有一个方法connect。
__init__文件内容:
import os
import warnings
from dataset.database import Database
from dataset.table import Table
from dataset.util import row_type
# shut up useless SA warning:
warnings.filterwarnings(
'ignore', 'Unicode type received non-unicode bind param value.')
warnings.filterwarnings(
'ignore', 'Skipping unsupported ALTER for creation of implicit constraint')
__all__ = ['Database', 'Table', 'freeze', 'connect']
__version__ = '1.1.2'
def connect(url=None, schema=None, reflect_metadata=True, engine_kwargs=None,
reflect_views=True, ensure_schema=True, row_type=row_type):
""" Opens a new connection to a database.
*url* can be any valid `SQLAlchemy engine URL`_. If *url* is not defined
it will try to use *DATABASE_URL* from environment variable. Returns an
instance of :py:class:`Database <dataset.Database>`. Set *reflect_metadata*
to False if you don't want the entire database schema to be pre-loaded.
This significantly speeds up connecting to large databases with lots of
tables. *reflect_views* can be set to False if you don't want views to be
loaded. Additionally, *engine_kwargs* will be directly passed to
SQLAlchemy, e.g. set *engine_kwargs={'pool_recycle': 3600}* will avoid `DB
connection timeout`_. Set *row_type* to an alternate dict-like class to
change the type of container rows are stored in.:
db = dataset.connect('sqlite:///factbook.db')
.. _SQLAlchemy Engine URL: http://docs.sqlalchemy.org/en/latest/core/engines.html#sqlalchemy.create_engine
.. _DB connection timeout: http://docs.sqlalchemy.org/en/latest/core/pooling.html#setting-pool-recycle
"""
if url is None:
url = os.environ.get('DATABASE_URL', 'sqlite://')
return Database(url, schema=schema, reflect_metadata=reflect_metadata,
engine_kwargs=engine_kwargs, reflect_views=reflect_views,
ensure_schema=ensure_schema, row_type=row_type)datasetconnecturl需要按SQLAlchemy engine URL方式定义database_url。- 可以定义一个环境变量
DATABASE_URL来设置url。
数据库URL的典型形式是:
dialect+driver://username:password@host:port/databasedialect方言是SQLAlchemy方言的标识名称,如sqlite,mysql,postgresql,oracle或mssql。driver是使用全小写字母连接到数据库的DBAPI的名称。URL中特殊的字符需要使用URL编码。
使用
dataset.connect(url)来连接数据库引擎。
我们使用SQLite3将数据库保存到dataset.db文件中:
>>> db = dataset.connect('sqlite:///dataset.db')
>>> db
<Database(sqlite:///dataset.db)>- 使用
get_table(table_name, primary_id=None, primary_type=None)或create_table(table_name, primary_id=None, primary_type=None)加载表或创建表,如果表不存在则会创建表。 - 使用
db[table_name]也可以加载或创建表。
指定数据库中的表时,可以使用类似于字典的语法,当表不存在时,会默认建表:
>>> table = db.get_table('user')
>>> table
<Table(user)>
>>> table1 = db['user']
>>> table1
<Table(user)>
>>> id(table) == id(table1)
True
>>> db['population']
<Table(population)>
>>> table2 = db['population']
>>> table2
<Table(population)>在SQLite3中查看user表和population表信息:
sqlite> .table
population user
sqlite> .schema user
CREATE TABLE user (
id INTEGER NOT NULL,
PRIMARY KEY (id)
);
sqlite> .schema population
CREATE TABLE population (
id INTEGER NOT NULL,
PRIMARY KEY (id)
);
sqlite>创建表时指主键和主键类型:
>>> table_population2 = db.create_table('population2', 'age') # 指定age为主键
>>> table_population2
<Table(population2)>
>>> table_population3 = db.create_table('population3', primary_id='city', primary_type=db.types.text) # 指定city为主键,主键类型为text类型
>>> table_population3
<Table(population3)>
>>> table_population4 = db.create_table('population4', primary_id='city', primary_type=db.types.string(25)) # 指定city为主键,主键类型为string类型(对应varchar(25))
>>> table_population4
<Table(population4)>再在SQLite3中查看表信息:
sqlite> .table
population population2 population3 population4 user
sqlite> .schema population2
CREATE TABLE population2 (
age INTEGER NOT NULL,
PRIMARY KEY (age)
);
sqlite> .schema population3
CREATE TABLE population3 (
city TEXT NOT NULL,
PRIMARY KEY (city)
);
sqlite> .schema population4
CREATE TABLE population4 (
city VARCHAR(25) NOT NULL,
PRIMARY KEY (city)
);
sqlite>- 对
Table对象使用insert(row, ensure=None, types=None)插入数据,row为字典数据,返回插入行的primary key号。 - 如果row字典中的键不在表中,则会自动创建相应的column列。
插入一行数据:
>>> table.insert(dict(name='John Doe', age=46, country='China'))
1再在SQLite3中查看user表信息,使用.headers on打开表头header,并使用.mode column打开column列模式:
sqlite> .headers on
sqlite> .mode column
sqlite> select * from user;
id name age country
---------- ---------- ---------- ----------
1 John Doe 46 China
sqlite> .schema user
CREATE TABLE user (
id INTEGER NOT NULL, name TEXT, age INTEGER, country TEXT,
PRIMARY KEY (id)
);
sqlite>可以发现列name和country被自动加入到表中。
再插入一行数据:
>>> table.insert(dict(name='Edmond Dantes', age=37, country='France', gender='male'))
2再在SQLite3中查看user表信息:
sqlite> .schema user
CREATE TABLE user (
id INTEGER NOT NULL, name TEXT, age INTEGER, country TEXT, gender TEXT,
PRIMARY KEY (id)
);
sqlite> select * from user; --在默认的情况下,每列至少10个字符宽。太宽的数据将被截取。你可以用“.width”命令来调整列宽。
id name age country gender
---------- ---------- ---------- ---------- ----------
1 John Doe 46 China
2 Edmond Dan 37 France male
sqlite> .width 12 20 -- 改变第一列的宽度为12字符,改变第二列的宽度为20字符
sqlite> select * from user;
id name age country gender
------------ -------------------- ---------- ---------- ----------
1 John Doe 46 China
2 Edmond Dantes 37 France male
sqlite> select * from user where name="Edmond Dantes";
id name age country gender
------------ -------------------- ---------- ---------- ----------
2 Edmond Dantes 37 France male可以发现新列gender被自动添加进数据库。
- 对
Table对象使用update(row, keys, ensure=None, types=None, return_count=False)更新数据,row为字典数据,返回更新行的总行数。 - 如果row字典中的键不在表中,则会自动创建相应的column列。
更新John的年龄为47岁:
>>> table.update(dict(name='John Doe', age=47), ['name'])
1再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender
------------ -------------------- ---------- ---------- ----------
1 John Doe 47 China
2 Edmond Dantes 37 France male
sqlite>可以发现John Doe的年龄已经从46岁变成47岁了。
发现John Doe的性别没有指定,更新一下:
>>> table.update(dict(name='John Doe', gender='famale'), ['name'])
1再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender
------------ -------------------- ---------- ---------- ----------
1 John Doe 47 China famale
2 Edmond Dantes 37 France male
sqlite>性别补充好了,又发现可以补充一个email邮箱的字段:
>>> table.update(dict(id=1, email='john@python.org'),['id'])
1
>>> table.update(dict(id=2, email='edmond@python.org'),['id'])
1再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender email
------------ -------------------- ---------- ---------- ---------- ---------------
1 John Doe 47 China famale john@python.org
2 Edmond Dantes 37 France male edmond@python.o
sqlite>说明在update时如果列不存在的时候也可以自动加入到数据库中。
不指定具体对哪一行进行更新:
>>> table.update(dict(age=30),['id'])
2再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender email
------------ -------------------- ---------- ---------- ---------- ---------------
1 John Doe 30 China famale john@python.org
2 Edmond Dantes 30 France male edmond@python.o
sqlite>说明此时对所有的行进行更新,将age全部设置为30岁。
使用Transactions事务上下文管理器
使用with上下文管理器:
>>> with db:
... db['user'].insert(dict(name='John Doe', age=46, country='China'))
...再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender email
---------- ---------- ---------- ---------- ---------- ---------------
1 John Doe 32 China famale john@python.org
2 Edmond Dan 32 France male edmond@python.o
3 John Doe 46 China- 通过调用
begin()、commit()、rollback()以及使用try..except捕获异常。
使用 try..except 捕获异常:
>>> db = dataset.connect('sqlite:///dataset.db')
>>> db.begin()
>>> try:
... db['user'].update(dict(id=3,name='John King', gender='male', email='king@python.org'), ['id'])
... db.commit()
... except:
... db.rollback()
...再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender email
---------- ---------- ---------- ---------- ---------- ---------------
1 John Doe 32 China famale john@python.org
2 Edmond Dan 32 France male edmond@python.o
3 John King 46 China male king@python.org
sqlite>可以看到第三行数据已经更新。
检索数据库和表
db.tables查看数据库中所有的表信息。db[table_name].columns查看数据库表中所有字段信息。len(db[table_name])统计表中的数据行数。
查看表信息和表字段信息:
>>> db.tables
['population', 'population2', 'population3', 'population4', 'user']
>>> db['user'].columns
['id', 'name', 'age', 'country', 'gender', 'email']
>>> db['population'].columns
['id']
>>> len(db['user'])
3
>>> len(db['population'])
0Table.all()获取所有数据。- 如果我们只想迭代表中的所有行,我们可以省略
all()。
获取表中的所有数据:
>>> table
<Table(user)>
>>> table.all()
<dataset.util.ResultIter at 0x251a25e9d30>
>>> users = table.all()
>>> users
<dataset.util.ResultIter at 0x251a2643c88>
>>> for user in users:
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
>>> for user in table:
... print(user['name'], user['age'], user['country'])
...
John Doe 32 China
Edmond Dantes 32 France
John King 46 ChinaTable.find()查找所有特定条件的数据。Table.find_one()查找所有特定条件的数据,但仅返回一条数据。- 使用
_limit关键字参数可以限定返回的数据个数。 - 使用
order_by关键字参数可以对查找的结果进行排序。
通过 find 或 find_one 获取数据:
>>> chinese_users = table.find(country='China')
>>> chinese_users
<dataset.util.ResultIter at 0x251a2bd97b8>
>>> for user in chinese_users:
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
>>> table.find_one(country='China')
OrderedDict([('id', 1),
('name', 'John Doe'),
('age', 32),
('country', 'China'),
('gender', 'famale'),
('email', 'john@python.org')])
>>> for user in table.find(country='China', _limit=1): # 限定输出1条结果
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
>>> for user in table.find(country='China', _limit=2): # 限定输出2条结果
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
>>> for user in table.find(country='China', order_by='age'): # 按age年龄进行升序排列
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
>>> for user in table.find(country='China', order_by='-age'): # 按age年龄进行降序排列
... print(user)
...
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
>>> for user in table.find(country='France', age=32):
... print(user)
...
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])
>>> table.find(id=[1, 3])
<dataset.util.ResultIter at 0x251a2bf82b0>
>>> for user in table.find(id=[1, 3]):
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])- 在
find或find_one中使用比较运算符(comparison operators)。
可使用的运算符包括:
gt, >
lt, <
gte, >=
lte, <=
!=, <>, not
between, ..使用比较运算符:
>>> for user in table.find(age={'>=': 40}):
... print(user)
...
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
>>> for user in table.find(age={'gt': 40}):
... print(user)
...
OrderedDict([('id', 3), ('name', 'John King'), ('age', 46), ('country', 'China'), ('gender', 'male'), ('email', 'king@python.org')])
>>> for user in table.find(age={'lt': 40}):
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])
>>> for user in table.find(age={'<': 40}):
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])
>>> for user in table.find(age={'between':[30,40]}):
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])
>>> for user in table.find(age={'..':[30,40]}):
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])Table.distinct()获取一列或多列的唯一行。
如获取所有的国家信息:
>>> table.distinct('country')
<dataset.util.ResultIter at 0x251a2df57f0>
>>> for country in table.distinct('country'):
... print(country)
...
OrderedDict([('country', 'China')])
OrderedDict([('country', 'France')])
>>> for age in table.distinct('age'):
... print(age)
...
OrderedDict([('age', 32)])
OrderedDict([('age', 46)])
>>> for age_country in table.distinct('age','country'):
... print(age_country)
...
OrderedDict([('age', 32), ('country', 'China')])
OrderedDict([('age', 32), ('country', 'France')])
OrderedDict([('age', 46), ('country', 'China')])
>>> for age in table.distinct('age',country='China'):
... print(age)
...
OrderedDict([('age', 32)])
OrderedDict([('age', 46)])- 使用
db.query(SQL_STRING)运行自定义SQL字符串SQL_STRING。
统计每个国家的用户数量:
>>> result = db.query('SELECT country, COUNT(*) c FROM user GROUP BY country')
... for row in result:
... print(row['country'], row['c'])
...
China 2
France 1
>>> result = db.query('SELECT country, COUNT(*) AS count FROM user GROUP BY country')
... for row in result:
... print(row['country'], row['count'])
...
China 2
France 1Table.delete(*clauses, **filters)从表中删除行数据。If no arguments are given, all records are deleted.即如果没指定参数,所有的行数据都会会删除!!!
在表中删除行数据:
>>> user_king = table.find_one(name='John King')
>>> user_king
OrderedDict([('id', 3),
('name', 'John King'),
('age', 46),
('country', 'China'),
('gender', 'male'),
('email', 'king@python.org')])
>>> table.delete(name='John King')
True
>>> for user in table.all():
... print(user)
...
OrderedDict([('id', 1), ('name', 'John Doe'), ('age', 32), ('country', 'China'), ('gender', 'famale'), ('email', 'john@python.org')])
OrderedDict([('id', 2), ('name', 'Edmond Dantes'), ('age', 32), ('country', 'France'), ('gender', 'male'), ('email', 'edmond@python.org')])再在SQLite3中查看user表信息:
sqlite> select * from user;
id name age country gender email
---------- ---------- ---------- ---------- ---------- ---------------
1 John Doe 32 China famale john@python.org
2 Edmond Dan 32 France male edmond@python.o
sqlite>不设置参数,使用delete删除:
>>> table.delete()
True
>>> for user in table.all():
... print(user)
...再在SQLite3中查看user表信息:
sqlite> select * from user;
sqlite>已经查询不到数据,说明user表已经被清空了。
Table.drop_column(name)从表中删除指定列。- SQLite不支持删除列。
尝试删除列:
>>> table.columns
['id', 'name', 'age', 'country', 'gender', 'email']
>>> table.drop_column('email')
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-79-1932daeb597f> in <module>
----> 1 table.drop_column('email')
RuntimeError: SQLite does not support dropping columns.提示RuntimeError异常。
memcached的使用
Memcached是一个自由开源的,高性能,分布式内存对象缓存系统。Memcached是一种基于内存的key-value存储,用来存储小块的任意数据(字符串、对象)。这些数据可以是数据库调用、API调用或者是页面渲染的结果。
linux下安装Memcached 参见https://www.runoob.com/memcached/window-install-memcached.html 。
安装依赖包:
[root@localhost ~]# yum install libevent libevent-devel -y安装Memcached:
[root@localhost ~]# yum install memcached -y查看memcached的帮助信息:
[root@localhost ~]# memcached -h
memcached 1.4.15
-p <num> TCP port number to listen on (default: 11211)
-U <num> UDP port number to listen on (default: 11211, 0 is off)
-s <file> UNIX socket path to listen on (disables network support)
-a <mask> access mask for UNIX socket, in octal (default: 0700)
-l <addr> interface to listen on (default: INADDR_ANY, all addresses)
<addr> may be specified as host:port. If you don't specify
a port number, the value you specified with -p or -U is
used. You may specify multiple addresses separated by comma
or by using -l multiple times
-d run as a daemon
-r maximize core file limit
-u <username> assume identity of <username> (only when run as root)
-m <num> max memory to use for items in megabytes (default: 64 MB)
-M return error on memory exhausted (rather than removing items)
-c <num> max simultaneous connections (default: 1024)
-k lock down all paged memory. Note that there is a
limit on how much memory you may lock. Trying to
allocate more than that would fail, so be sure you
set the limit correctly for the user you started
the daemon with (not for -u <username> user;
under sh this is done with 'ulimit -S -l NUM_KB').
-v verbose (print errors/warnings while in event loop)
-vv very verbose (also print client commands/reponses)
-vvv extremely verbose (also print internal state transitions)
-h print this help and exit
-i print memcached and libevent license
-P <file> save PID in <file>, only used with -d option
-f <factor> chunk size growth factor (default: 1.25)
-n <bytes> minimum space allocated for key+value+flags (default: 48)
-L Try to use large memory pages (if available). Increasing
the memory page size could reduce the number of TLB misses
and improve the performance. In order to get large pages
from the OS, memcached will allocate the total item-cache
in one large chunk.
-D <char> Use <char> as the delimiter between key prefixes and IDs.
This is used for per-prefix stats reporting. The default is
":" (colon). If this option is specified, stats collection
is turned on automatically; if not, then it may be turned on
by sending the "stats detail on" command to the server.
-t <num> number of threads to use (default: 4)
-R Maximum number of requests per event, limits the number of
requests process for a given connection to prevent
starvation (default: 20)
-C Disable use of CAS
-b <num> Set the backlog queue limit (default: 1024)
-B Binding protocol - one of ascii, binary, or auto (default)
-I Override the size of each slab page. Adjusts max item size
(default: 1mb, min: 1k, max: 128m)
-S Turn on Sasl authentication
-o Comma separated list of extended or experimental options
- (EXPERIMENTAL) maxconns_fast: immediately close new
connections if over maxconns limit
- hashpower: An integer multiplier for how large the hash
table should be. Can be grown at runtime if not big enough.
Set this based on "STAT hash_power_level" before a
restart.
[root@localhost ~]#启动memcached:
[root@localhost ~]# memcached -u root -p 11211 -m 64m -d启动选项说明:
-u root 以root用户运行Memcache(如果不使用此选项,则会提示can't run as root without the -u switch)
-p 11211 是设置Memcache监听的端口为11211
-m 64m 是分配给Memcache使用的内存数量,单位是64MB
-d 是启动一个守护进程安装telnet工具:
[root@localhost ~]# yum install telnet-server telnet -y使用 telnet HOST PORT 连接memcached服务,HOST、PORT是运行memcached的主机和端口。
连接memcached服务:
[root@localhost ~]# telnet 127.0.0.1 11211
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.说明已经连接上memcached服务。
或者HOST使用localhost也可以:
[root@localhost ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.在连接上memcached服务后,就可以执行memcached命令了。
memcached的存储命令set、add、replace、 append、prepend、cas
set命令,用于将value值存储到key键中,如果key已经存在,则会更新key的value值。
语法如下:
set key flags exptime bytes [noreply]
value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
flags: 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息。
exptime: 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)。
bytes: 在缓存中存储的字节数。
noreply: 可选参数,该参数告诉服务器不需要返回数据。
value: 键值 key-value 结构中的 value,存储的值,始终位于第二行。设置一个键值对:
set firstkey 0 900 15
hello,memcached
STORED
get firstkey
VALUE firstkey 0 15
hello,memcached
END
set firstkey 0 900 16 <-- 说明:此处是对firstkey键的value值进行更新
hello,memcached!
STORED
get firstkey
VALUE firstkey 0 16
hello,memcached!
END
其中:
key键为firstkey
flags为0
exptime过期时间900s
bytes存储字节数15
value存储的值为hello,memcached设置过期时间:
set secondkey 0 30 6 <-- 说明:设置过期时间为30秒
hello!
STORED
get secondkey <-- 说明:在30s内能够获取到secondkey的值
VALUE secondkey 0 6
hello!
END
get secondkey <-- 说明:在30s内能够获取到secondkey的值
VALUE secondkey 0 6
hello!
END
get secondkey <-- 说明:在30s内能够获取到secondkey的值
VALUE secondkey 0 6
hello!
END
get secondkey <-- 说明:在30s内能够获取到secondkey的值
VALUE secondkey 0 6
hello!
END
get secondkey <-- 说明:超过30s后,获取不到secondkey的值,说明secondkey已经过期
END设置无返回数据:
set noreplykey 0 900 6 noreply
123456 <-- 说明:设置成功后,并没有返回STORED
get noreplykey
VALUE noreplykey 0 6
123456
END- 存储正确时,输出信息为
STORED,表示已经存储成功。 - 存储失败时,输出信息为
ERROR,表示存储失败。
键值设置错误时的输出:
set test 0 900 6
1234567890 <-- 说明:此处输入的值是10byte,而缓存存储只指定存储字节数是6byte,超过允许的范围
CLIENT_ERROR bad data chunk
ERROR
set test 0 900 6
1234
56 <-- 说明:此处指定存储字节数是6byte,但存储值分两行写,也导致存储错误
CLIENT_ERROR bad data chunk
ERRORadd命令,将value存储在指定的key键中。- 如果key存在,且未过期,则不会更新数据,并返回响应
NOT_STORED。 - 如果key存在,且已经过期,则会更新数据。
- 如果key不存在,则会添加数据,作用同
set。
语法如下:
add key flags exptime bytes [noreply]
value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
flags: 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息。
exptime: 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)。
bytes: 在缓存中存储的字节数。
noreply: 可选参数,该参数告诉服务器不需要返回数据。
value: 键值 key-value 结构中的 value,存储的值,始终位于第二行。设置一个键值对:
get firstkey <-- 说明:能够获取到firstkey的值
VALUE firstkey 0 16
hello,memcached!
END
get seondkey <-- 说明:不能够获取到secondkey的值,因为secondkey键已经过期
END
add firstkey 0 900 5 <-- 说明:尝试对firstkey键进行更新,未能成功
hello
NOT_STORED <-- 说明:返回NOT_STORED
add secondkey 0 900 5 <-- 说明:尝试对secondkey键进行更新,成功
hello
STORED <-- 说明:返回STORED
add thirdkey 0 900 5 <-- 说明:尝试对thirdkey键进行更新,成功,因为thirdkey键不存在,所以相当于设置键值对
hello
STORED <-- 说明:返回STORED
get firstkey <-- 说明:获取到firstkey的值,但值未更新
VALUE firstkey 0 16
hello,memcached!
END
get secondkey <-- 说明:获取到secondkey的值,但值已经更新
VALUE secondkey 0 5
hello
END
get thirdkey <-- 说明:获取到thirdkey的值,但值已经更新
VALUE thirdkey 0 5
hello
ENDreplace命令,将已经存在的key键的的值为value。- 如果key存在,且未过期,则替换数据,并返回响应
STORED。 - 如果key存在,且已经过期,则替换失败, 并返回响应
NOT_STORED。 - 如果key不存在,则替换失败,并返回响应
NOT_STORED。
语法如下:
replace key flags exptime bytes [noreply]
value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
flags: 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息。
exptime: 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)。
bytes: 在缓存中存储的字节数。
noreply: 可选参数,该参数告诉服务器不需要返回数据。
value: 键值 key-value 结构中的 value,存储的值,始终位于第二行。对键的值进行替换:
get firstkey
VALUE firstkey 0 16
hello,memcached!
END
get secondkey
VALUE secondkey 0 5
hello
END
get thirdkey
VALUE thirdkey 0 5
hello
END
set fourthkey 0 30 5
hello
STORED
get fourthkey
VALUE fourthkey 0 5
hello
END
get fourthkey
VALUE fourthkey 0 5
hello
END
get fourthkey
VALUE fourthkey 0 5
hello
END
get fourthkey <-- 说明:获取不到fourthkey的值,说明其已经过期
END
replace secondkey 0 900 6 <-- 说明:替换secondkey的值,替换成功返回"STORED"
hello!
STORED
get secondkey <-- 说明:获取secondkey的值,已经从"hello"变成了"hello!"
VALUE secondkey 0 6
hello!
END
replace thirdkey 0 900 3 <-- 说明:替换thirdkey的值,替换成功返回"STORED"
hi!
STORED
get thirdkey <-- 说明:获取thirdkey的值,已经从"hello"变成了"hi!"
VALUE thirdkey 0 3
hi!
END
replace fourthkey 0 900 16 <-- 说明:替换fourthkey的值,因为fourthkey已经过期,替换失败返回"NOT_STORED"
hello,memcached!
NOT_STORED
replace notexist 0 900 5 <-- 说明:替换notexist的值,因为notexist这个键不存在,不进行替换
hello
NOT_STOREDappend命令,在已经存在的key键的的值为value后面追加数据。- 如果key存在,且未过期,则追加数据,并返回响应
STORED。 - 如果key存在,且已经过期,则追加失败, 并返回响应
NOT_STORED。 - 如果key不存在,则追加失败,并返回响应
NOT_STORED。
语法如下:
append key flags exptime bytes [noreply]
value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
flags: 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息。
exptime: 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)。
bytes: 在缓存中存储的字节数,即追加多少字节数。
noreply: 可选参数,该参数告诉服务器不需要返回数据。
value: 键值 key-value 结构中的 value,存储的值,始终位于第二行。在键的值的后面进行追加数据:
get firstkey
END
get secondkey
END
get thirdkey
END
get fourthkey
END
set firstkey 0 12 5 <-- 说明:设置firstkey的值,12秒后过期
first
STORED
set secondkey 0 900 6
second
STORED
get firstkey <-- 说明:获取firstkey的值,因为已经过期,获取不到数据
END
append firstkey 0 12 1 <-- 说明:向firstkey的值后面追加1个字节的数据,追加失败,返回"NOT_STORED"
!
NOT_STORED
append secondkey 0 900 4 <-- 说明:向secondkey的值后面追加4个字节的数据,追加成功,返回"STORED"
line
STORED
get secondkey <-- 说明:获取secondkey的值,已经是追加后的数据"secondline"了
VALUE secondkey 0 10
secondline
END
append thirdkey 0 900 5 <-- 说明: 向不存在的thirdkey中追加数据,追加失败,返回"NOT_STORED"
hello
NOT_STORED
get thirdkey
ENDprepend命令,在已经存在的key键的的值为value前面追加数据。- 如果key存在,且未过期,则追加数据,并返回响应
STORED。 - 如果key存在,且已经过期,则追加失败, 并返回响应
NOT_STORED。 - 如果key不存在,则追加失败,并返回响应
NOT_STORED。
语法如下:
prepend key flags exptime bytes [noreply]
value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
flags: 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息。
exptime: 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)。
bytes: 在缓存中存储的字节数,即追加多少字节数。
noreply: 可选参数,该参数告诉服务器不需要返回数据。
value: 键值 key-value 结构中的 value,存储的值,始终位于第二行。在键的值的前面进行追加数据:
set firstkey 0 12 5
first
STORED
get firstkey
VALUE firstkey 0 5
first
END
get firstkey <-- 说明:键firstkey过期
END
set secondkey 0 900 5
hello
STORED
prepend firstkey 0 900 5 <-- 说明:向过期的键firstkey的值前面追加5个字节的数据,追加失败,返回"NOT_STORED"
befor
NOT_STORED
prepend secondkey 0 900 6 <-- 说明:向secondkey的值前面追加6个字节的数据,追加成功,返回"STORED"
before
STORED
prepend thirdkey 0 900 6 <-- 说明: 向不存在的thirdkey中追加数据,追加失败,返回"NOT_STORED"
before
NOT_STORED- Memcached于1.2.4版本新增CAS(Check and Set)协议,处理同一item被多个线程更改过程的并发问题。
- 在Memcached中,每个key关联有一个64-bit长度的long型惟一数值,表示该key对应value的版本号。这个数值由Memcached server产生,从1开始,且同一Memcached server不会重复。在两种情况下这个版本数值会加1:1、新增一个key-value对;2、对某已有key对应的value值更新成功。删除item版本值不会减小。
cas命令,用于将value值存储到key键中,如果key已经存在,且未被其他用户更新,则会更新key的value值,并返回"STORED"。cas命令,用于将value值存储到key键中,如果key已经存在,且被其他用户更新,则不会更新key的value值,并返回"EXISTS"。cas命令,用于将value值存储到key键中,如果key不存在,则不会更新key的value值,并返回"NOT_FOUND"。cas命令,用于将value值存储到key键中,如果cas命令的语法错误,则返回"ERROR"。
语法如下:
cas key flags exptime bytes unique_cas_token [noreply]
value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
flags: 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息。
exptime: 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)。
bytes: 在缓存中存储的字节数。
unique_cas_token:通过gets命令获取到的一个唯一的64位的CAS值。
noreply: 可选参数,该参数告诉服务器不需要返回数据。
value: 键值 key-value 结构中的 value,存储的值,始终位于第二行。我使用以下三台服务器演示并发操作:
server 192.168.56.11
node1 192.168.56.12
node2 192.168.56.13
首先在server端防火墙放行11211端口:
[root@server ~]# firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3 enp0s8
sources:
services: ssh dhcpv6-client
ports: 8140/tcp 53/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
[root@server ~]# firewall-cmd --permanent --add-port=11211/tcp
success
[root@server ~]# firewall-cmd --reload
success
[root@server ~]# firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3 enp0s8
sources:
services: ssh dhcpv6-client
ports: 8140/tcp 53/tcp 11211/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:在server端使用telnet连接memcached服务器,并设置一个firstkey键,值为"hello,memcached":
[root@server ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
set firstkey 0 900 15
hello,memcached
STORED
get firstkey
VALUE firstkey 0 15
hello,memcached
END在node1节点使用telnet连接memcached服务器,并获取firstkey键值:
[root@node1 ~]# telnet 192.168.56.11 11211
Trying 192.168.56.11...
Connected to 192.168.56.11.
Escape character is '^]'.
get firstkey
VALUE firstkey 0 15
hello,memcached
END在node2节点使用telnet连接memcached服务器,并获取firstkey键值:
[root@node2 ~]# telnet 192.168.56.11 11211
Trying 192.168.56.11...
Connected to 192.168.56.11.
Escape character is '^]'.
get firstkey
VALUE firstkey 0 15
hello,memcached
END可以发现在node1节点和node2节点上面都能够正常的获取firstkey键的值。
如果我们要在node1节点给firstkey追加一个字符"!",期望追加后的firstkey变成"hello,memcached!"。要在node2节点上给firstkey追加12个字符"How are you?",期望追加后的firstkey变成"hello,memcachedHow are you?"。
先在node1节点上面追加:
append firstkey 0 900 1
!
STORED
get firstkey
VALUE firstkey 0 16
hello,memcached!
END再在node2节点上面追加:
append firstkey 0 900 12
How are you?
STORED
get firstkey
VALUE firstkey 0 28
hello,memcached!How are you?
END对比发现在node2上面获取的firstkey的值是"hello,memcached!How are you?",并不是"hello,memcachedHow are you?",原因是node2在更新firstkey前,node1已经将firstkey键进行了更新,并增加了一个字符"!",而node2并不知道这件事,导致node2获取的数据并不是自己预期的那样!!!
说明
可以发现,这样并不能保证多个节点上修改firstkey的初始值是同一个值,也不能保证firstkey不会多个节点修改**。
- Memcached自1.2.4版本新增CAS协议用于解决并发修改问题,即给每个KEY关键一个CAS值,表示该KEY对应的value的版本号。
- 使用
gets key可以查询key的CAS值。
在server端使用telnet连接memcached服务器,并设置一个firstkey键,值为"Hello",设置secondkey键,值为"hi":
[root@server ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
set firstkey 0 3600 5
Hello
STORED
gets firstkey
VALUE firstkey 0 5 22
Hello
END
set secondkey 0 3600 2
hi
STORED
gets secondkey
VALUE secondkey 0 2 23
hi
END在node1节点使用telnet连接memcached服务器,并获取firstkey键和secondkey键的cas值:
[root@node1 ~]# telnet 192.168.56.11 11211
Trying 192.168.56.11...
Connected to 192.168.56.11.
Escape character is '^]'.
gets firstkey secondkey
VALUE firstkey 0 5 22
Hello
VALUE secondkey 0 2 23
hi
END在node2节点使用telnet连接memcached服务器,并获取firstkey键和secondkey键的cas值:
[root@node2 ~]# telnet 192.168.56.11 11211
Trying 192.168.56.11...
Connected to 192.168.56.11.
Escape character is '^]'.
gets firstkey secondkey
VALUE firstkey 0 5 22
Hello
VALUE secondkey 0 2 23
hi
END在node1节点更新firstkey键的值,增加一个"!",并获取firstkey键的cas值:
set firstkey 0 3600 6
Hello!
STORED
gets firstkey
VALUE firstkey 0 6 24
Hello!
END可以发现firstkey键的cas值已经变成24,并且其值已经是"Hello!"。
若此时,要在node2节点更新firstkey键的值,增加". Memcached!",并得到更新后的值为"Hello. Memcached!", 并获取firstkey键的cas值,使用cas命令检查在最后一次取值后,是否有别的用户对数据进行了更新操作:
cas firstkey 0 3600 17 22
hello. Memcached!
EXISTS可以发现,未能正常存储,返回"EXISTS",说明在最后一次取值后另外一个用户也在更新该数据。
仍然在node2上面操作,再获取最新的CAS值,对firstkey进行更新:
gets firstkey
VALUE firstkey 0 6 24
Hello!
END
cas firstkey 0 3600 17 24 <-- 说明: 对firstkey键CAS值为24(也就是版本)进行修改
Hello! Memcached!
STORED
gets firstkey
VALUE firstkey 0 17 25 <-- 说明: 更新完成后,CAS版本号新增1,变成了25
Hello! Memcached!
END此次能够正常的更新firstkey键的值,原因是firstkey键的CAS值为24后,并没有其他的用户对该键进行修改,也就可以避免多用户同时对一个键进行修改。
仍然在node2上面操作,返回ERROR或NOT_FOUND的情况:
cas thirdkey 0 3600 5 <-- 说明: 语法错误,未指定CAS版本号,返回"ERROR"
ERROR
cas thirdkey 0 3600 5 25 <-- 说明: thirdkey不存在,找不到CAS版本号是25的thirdkey,返回"NOT_FOUND"
hello
NOT_FOUNDmemcached的查找命令 get、gets、delete、incr、decr、flush_all
get命令,获取存储到key键中的value值,如果key不存在,则返回空。
语法如下:
get key <-- 说明: 获取单个key的value值
get key1 key2 key3 <-- 说明: 获取多个key的value值
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。获取键的值:
set firstkey 0 12 5 <-- 说明:设置firstkey键12秒后过期
first
STORED
get firstkey <-- 说明:获取firstkey键的值,因为未过期,获取到值"first"
VALUE firstkey 0 5
first
END
get firstkey <-- 说明:获取firstkey键的值,因为已经过期,获取不到值
END
get firstkey
END
set secondkey 0 900 6 <-- 说明:设置secondkey键900秒后过期
second
STORED
set thirdkey 0 900 5 <-- 说明:设置thirdkey键900秒后过期
third
STORED
get firstkey secondkey thirdkey <-- 说明:同时获取多个键的值
VALUE secondkey 0 6
second
VALUE thirdkey 0 5
third
ENDgets命令,获取存储到key键中带有CAS令牌的value值,如果key不存在,则返回空。
语法如下:
gets key <-- 说明: 获取单个key的value值
gets key1 key2 key3 <-- 说明: 获取多个key的value值
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。接上例,获取带CAS令牌的键的值:
gets firstkey
END
gets secondkey
VALUE secondkey 0 6 16 <-- 说明:secondkey键的CAS令牌是16
second
END
gets thirdkey
VALUE thirdkey 0 5 17 <-- 说明:thirdkey键的CAS令牌是17
third
END
set fourthkey 0 900 6
fourth
STORED
get fourthkey
VALUE fourthkey 0 6
fourth
END
gets fourthkey
VALUE fourthkey 0 6 18 <-- 说明:fourthkey键的CAS令牌是18
fourth
ENDdelete命令,删除已经存在的键。
语法如下:
delete key [noreply] <-- 说明: 删除key键
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
noreply: 告诉服务器不需要返回数据。
输出信息如下:
DELETED:删除成功。
ERROR:删除失败或语法错误。
NOT_FOUND:键不存在。删除memcached中的键:
[root@server ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
set willdeletedkey 0 3600 5 <-- 说明: 设置键,存储成功
hello
STORED
get willdeletedkey
VALUE willdeletedkey 0 5
hello
END
delete willdeletedkey <-- 说明: 删除键,删除成功,返回"DELETED"
DELETED
get willdeletedkey
END
delete willdeletedkey <-- 说明: 删除键,删除失败,返回"NOT_FOUND",因为键已经被删除了,系统中已经找不到该键
NOT_FOUNDincr命令,对已经存在的键进行自增操作,操作的数据必须是十进制的32位无符号整数。decr命令,对已经存在的键进行自减操作,操作的数据必须是十进制的32位无符号整数。- 如果自增或自减成功,则返回自增或自减后的value值。
语法如下:
incr key increment_value <-- 说明: 对key的value进行自增操作,即value = value + increment_value
decr key decrement_value <-- 说明: 对key的value进行自减操作,即value = value + decrement_value
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
increment_value或decrement_value:增量值或减量值,必须是无符号整数。
输出信息如下:
CLIENT_ERROR:自增或自减的数据不是数字。
ERROR:自增或自减失败或语法错误。
NOT_FOUND:键不存在。删除memcached中的键:
set num 0 3600 2 <-- 说明: 设置num键的值为55
55
STORED
gets num <-- 说明: 设置num键的值
VALUE num 0 2 27
55
END
incr num 50 <-- 说明: num键的值自增50,变成105
105
get num
VALUE num 0 3
105
END
decr num 100 <-- 说明: num键的值自减100,变成5
5
get num
VALUE num 0 1
5
END异常输出:
incr num_notexist 1
NOT_FOUND
incr num abc
CLIENT_ERROR invalid numeric delta argument
incr num -7
CLIENT_ERROR invalid numeric delta argument
incr num 5.5
CLIENT_ERROR invalid numeric delta argument
incr num2abc
ERROR
incr num
ERRORflush_all命令,清除缓存中所有的key-value键值对。
语法如下:
flush_all [time] [noreply]
参数说明:
key:键值 key-value 结构中的 key,用于查找缓存值。
time: 用于在制定的时间后执行清理缓存操作。
noreply: 提示服务器端不需要返回数据。清除所有键值对:
[root@server ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
stats sizes
END
stats items
END
set firstkey 0 3600 5 <-- 说明: 设置firstkey键的值为"hello"
hello
STORED
set secondkey 0 3600 6 <-- 说明: 设置secondkey键的值为"hello!"
hello!
STORED
gets firstkey secondkey <-- 说明: 获取firstkey键和secondkey键的信息
VALUE firstkey 0 5 1
hello
VALUE secondkey 0 6 2
hello!
END
flush_all <-- 说明: 清除缓存中所有的键值对,清除成功,返回"OK"
OK
gets firstkey secondkey <-- 说明: 获取firstkey键和secondkey键的信息,已经没有相关信息
ENDmemcached的统计命令stats、stats items、stats slabs、stats sizes
stats命令,返回如PID、版本号、连接数、存储占用字节数等等统计信息。
语法如下:
stats获取统计信息:
[root@server ~]# telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
stats <-- 说明: 获取统计信息
STAT pid 13486 <-- 说明: Memcached服务端的PID
STAT uptime 35516 <-- 说明: 服务启动时间
STAT time 1559380900 <-- 说明: 服务端的Unix时间戳
STAT version 1.4.15 <-- 说明: Memcached的版本号
STAT libevent 2.0.21-stable <-- 说明:
STAT pointer_size 64 <-- 说明: 操作系统指针大小
STAT rusage_user 0.775030 <-- 说明: 进程累计用户时间
STAT rusage_system 1.469022 <-- 说明: 进程累计系统时间
STAT curr_connections 11 <-- 说明: 当前连接数量
STAT total_connections 26 <-- 说明: Memecached运行以来连接总数
STAT connection_structures 13 <-- 说明: Memcached分配的连接结构数量
STAT reserved_fds 20 <-- 说明:
STAT cmd_get 79 <-- 说明: get命令请求次数
STAT cmd_set 43 <-- 说明: set命令请求次数
STAT cmd_flush 0 <-- 说明: flush命令请求次数
STAT cmd_touch 0 <-- 说明: touch命令请求次数
STAT get_hits 50 <-- 说明: get命令命中次数
STAT get_misses 29 <-- 说明: get命令未命中次数
STAT delete_misses 1 <-- 说明: delete命令未命中次数
STAT delete_hits 1 <-- 说明: delete命令命中次数
STAT incr_misses 1 <-- 说明: incr命令未命中次数
STAT incr_hits 3 <-- 说明: incr命令命中次数
STAT decr_misses 0 <-- 说明: decr命令未命中次数
STAT decr_hits 1 <-- 说明: decr命令命中次数
STAT cas_misses 1 <-- 说明: cas命令未命中次数
STAT cas_hits 1 <-- 说明: cas命令命中次数
STAT cas_badval 2 <-- 说明: 使用擦拭次数
STAT touch_hits 0 <-- 说明: touch命令命中次数
STAT touch_misses 0 <-- 说明: touch命令未命中次数
STAT auth_cmds 0 <-- 说明: 认证命令处理的次数
STAT auth_errors 0 <-- 说明: 认证失败的次数
STAT bytes_read 4426 <-- 说明: 读取总字节数
STAT bytes_written 9572 <-- 说明: 写总字节数
STAT limit_maxbytes 67108864 <-- 说明: 分配的内存总字节大小
STAT accepting_conns 1 <-- 说明: 服务器是否达到过最大连接
STAT listen_disabled_num 0 <-- 说明: 失败的监听数
STAT threads 4 <-- 说明: 当前线程数
STAT conn_yields 0 <-- 说明: 连接操作主动放弃数目
STAT hash_power_level 16 <-- 说明: hashpower的level,可以在启动的时候设置
STAT hash_bytes 524288 <-- 说明: 内存使用总量单位为byte
STAT hash_is_expanding 0 <-- 说明: 是否正在扩大hash表
STAT bytes 161 <-- 说明: 当前存储占用的字节数
STAT curr_items 2 <-- 说明: 当前存储的数据总数
STAT total_items 31 <-- 说明: 启动以来存储的数据总数
STAT expired_unfetched 2 <-- 说明: item过期之前没有被touch过,也就是放进去之后就没更新过过期时间
STAT evicted_unfetched 0 <-- 说明: item替换覆盖之前没有被touch过,也就是放进去之后就没更新过过期时间
STAT evictions 0 <-- 说明: LRU释放的对象数目
STAT reclaimed 6 <-- 说明: 已过期的数据条目来存储新数据的数目
END其他统计命令:
stats items
STAT items:1:number 2
STAT items:1:age 3182
STAT items:1:evicted 0
STAT items:1:evicted_nonzero 0
STAT items:1:evicted_time 0
STAT items:1:outofmemory 0
STAT items:1:tailrepairs 0
STAT items:1:reclaimed 6
STAT items:1:expired_unfetched 2
STAT items:1:evicted_unfetched 0
END
stats slabs
STAT 1:chunk_size 96
STAT 1:chunks_per_page 10922
STAT 1:total_pages 1
STAT 1:total_chunks 10922
STAT 1:used_chunks 2
STAT 1:free_chunks 10920
STAT 1:free_chunks_end 0
STAT 1:mem_requested 161
STAT 1:get_hits 49
STAT 1:cmd_set 43
STAT 1:delete_hits 1
STAT 1:incr_hits 3
STAT 1:decr_hits 1
STAT 1:cas_hits 1
STAT 1:cas_badval 2
STAT 1:touch_hits 0
STAT 2:chunk_size 120
STAT 2:chunks_per_page 8738
STAT 2:total_pages 1
STAT 2:total_chunks 8738
STAT 2:used_chunks 0
STAT 2:free_chunks 8738
STAT 2:free_chunks_end 0
STAT 2:mem_requested 0
STAT 2:get_hits 1
STAT 2:cmd_set 0
STAT 2:delete_hits 0
STAT 2:incr_hits 0
STAT 2:decr_hits 0
STAT 2:cas_hits 0
STAT 2:cas_badval 0
STAT 2:touch_hits 0
STAT active_slabs 2
STAT total_malloced 2097072
END
stats sizes
STAT 96 2
ENDpython-memcached处理NoSQL非关系型数据库memcached
安装python-memcached包:
[root@server ~]# pip install python-memcached
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Collecting python-memcached
Downloading https://mirrors.aliyun.com/pypi/packages/f5/90/19d3908048f70c120ec66a39e61b92c253e834e6e895cd104ce5e46cbe53/python_memcached-1.59-py2.py3-none-any.whl
Requirement already satisfied: six>=1.4.0 in /usr/lib/python3.6/site-packages (from python-memcached) (1.12.0)
Installing collected packages: python-memcached
Successfully installed python-memcached-1.59启动ipython,导入memcache模块,并查看相关帮助信息:
[root@server ~]# ipython
Python 3.6.7 (default, Dec 5 2018, 15:02:05)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.5.0 -- An enhanced Interactive Python. Type '?' for help.
>>> import memcache
>>> memcache?
Type: module
String form: <module 'memcache' from '/usr/lib/python3.6/site-packages/memcache.py'>
File: /usr/lib/python3.6/site-packages/memcache.py
Docstring:
client module for memcached (memory cache daemon)
Overview
========
See U{the MemCached homepage<http://www.danga.com/memcached>} for more
about memcached.
Usage summary
=============
This should give you a feel for how this module operates:
import memcache
mc = memcache.Client(['127.0.0.1:11211'], debug=0)
mc.set("some_key", "Some value")
value = mc.get("some_key")
mc.set("another_key", 3)
mc.delete("another_key")
mc.set("key", "1") # note that the key used for incr/decr must be
# a string.
mc.incr("key")
mc.decr("key")
The standard way to use memcache with a database is like this:
key = derive_key(obj)
obj = mc.get(key)
if not obj:
obj = backend_api.get(...)
mc.set(key, obj)
# we now have obj, and future passes through this code
# will use the object from the cache.
Detailed Documentation
======================
More detailed documentation is available in the L{Client} class.基本操作:
#!/usr/bin/python3
"""
@Time : 2019/6/2 19:58
@Author : Mei Zhaohui
@Email : mzh.whut@gmail.com
@File : usememcached.py
@Software: PyCharm
"""
import memcache
import time
def main():
"""main function"""
# 单节点memecached, debug=True表示运行出现错误时,显示错误信息,上线后需要移除该参数
mc = memcache.Client(['192.168.56.11:11211'], debug=True)
print('Memcached client:', mc)
result = mc.set('first_key', 'hello,memcached!') # set设置键值,如果键不存在则创建,键存在则修改
print('result: ', result) # 成功,则返回True
print("mc.get('first_key') = ", mc.get('first_key'))
print("mc.gets('first_key') = ", mc.gets('first_key'))
mc.set_multi({'second_key': 'hi', 'third_key': 'hi!'}) # 一次设置多个键
print("mc.get_multi(['second_key', 'third_key']) = ", mc.get_multi(['second_key', 'third_key']))
mc.replace('second_key', 'Hi!') # 替换
mc.append('third_key', 'Memcached!') # 尾部追加
mc.prepend('third_key', 'I am Python!') # 首部追加
print("mc.get_multi(['second_key', 'third_key']) = ", mc.get_multi(['second_key', 'third_key']))
# third_result = mc.add('third_key', 'add again') # add添加,如果键已经存在,则添加失败,返回False
mc.delete('fourth_key') # 删除键
print(mc.add('fourth_key', 'for you', time=2)) # add添加,如果键不存在,则添加成功,返回True,设置超时2秒
time.sleep(1) # 等待1秒
print("mc.get('fourth_key') = ", mc.get('fourth_key'))
time.sleep(1) # 等待1秒
print("mc.get('fourth_key') = ", mc.get('fourth_key'))
mc.set('num', 55)
print("mc.get('num') = ", mc.get('num'))
mc.incr('num', 50) # 自增
print("mc.get('num') = ", mc.get('num'))
mc.decr('num', 100) # 自减
print("mc.get('num') = ", mc.get('num'))
if __name__ == '__main__':
main()运行usememcached.py显示结果如下:
Memcached client: <memcache.Client object at 0x000001D76186AB88>
result: True
mc.get('first_key') = hello,memcached!
mc.gets('first_key') = hello,memcached!
mc.get_multi(['second_key', 'third_key']) = {'second_key': 'hi', 'third_key': 'hi!'}
mc.get_multi(['second_key', 'third_key']) = {'second_key': 'Hi!', 'third_key': 'I am Python!hi!Memcached!'}
True
mc.get('fourth_key') = for you
mc.get('fourth_key') = None
mc.get('num') = 55
mc.get('num') = 105
mc.get('num') = 5
Process finished with exit code 0使用memcached集群
使用memcached集群:
#!/usr/bin/python3
"""
@Time : 2019/6/2 21:15
@Author : Mei Zhaohui
@Email : mzh.whut@gmail.com
@File : use_memcached_cluster.py
@Software: PyCharm
"""
import memcache
import time
def main():
"""使用memcached集群,不设置权重"""
mc = memcache.Client(
[
'192.168.56.11:11211',
'192.168.56.12:11211',
'192.168.56.13:11211',
],
debug=True)
for num in range(30):
mc.set('num' + str(num), pow(num, 2))
for num in range(30):
print("mc.get('num' + str(num)) = ", mc.get('num' + str(num)))
if __name__ == '__main__':
main()运行use_memcached_cluster.py,结果如下:
mc.get('num0') = 0
mc.get('num1') = 1
mc.get('num2') = 4
mc.get('num3') = 9
mc.get('num4') = 16
mc.get('num5') = 25
mc.get('num6') = 36
mc.get('num7') = 49
mc.get('num8') = 64
mc.get('num9') = 81
mc.get('num10') = 100
mc.get('num11') = 121
mc.get('num12') = 144
mc.get('num13') = 169
mc.get('num14') = 196
mc.get('num15') = 225
mc.get('num16') = 256
mc.get('num17') = 289
mc.get('num18') = 324
mc.get('num19') = 361
mc.get('num20') = 400
mc.get('num21') = 441
mc.get('num22') = 484
mc.get('num23') = 529
mc.get('num24') = 576
mc.get('num25') = 625
mc.get('num26') = 676
mc.get('num27') = 729
mc.get('num28') = 784
mc.get('num29') = 841
Process finished with exit code 0在三个节点上面查看键值对信息:
node1 '192.168.56.11:11211':
gets num0 num1 num2 num3 num4 num5 num6 num7 num8 num9 num10 num11 num12 num13 num14 num15 num16 num17 num18 num19 num20 num21 num22 num23 num24 num25 num26 num27 num28 num29
VALUE num1 2 1 283
1
VALUE num2 2 1 284
4
VALUE num3 2 1 285
9
VALUE num6 2 2 286
36
VALUE num8 2 2 287
64
VALUE num10 2 3 288
100
VALUE num13 2 3 289
169
VALUE num14 2 3 290
196
VALUE num17 2 3 291
289
VALUE num23 2 3 292
529
VALUE num25 2 3 293
625
END可以发现在node1上存储了11个键值对
node2 '192.168.56.12:11211':
gets num0 num1 num2 num3 num4 num5 num6 num7 num8 num9 num10 num11 num12 num13 num14 num15 num16 num17 num18 num19 num20 num21 num22 num23 num24 num25 num26 num27 num28 num29
VALUE num7 2 2 130
49
VALUE num11 2 3 131
121
VALUE num18 2 3 132
324
VALUE num21 2 3 133
441
VALUE num24 2 3 134
576
VALUE num29 2 3 135
841
END可以发现在node2上存储了6个键值对
node3 '192.168.56.13:11211'
gets num0 num1 num2 num3 num4 num5 num6 num7 num8 num9 num10 num11 num12 num13 num14 num15 num16 num17 num18 num19 num20 num21 num22 num23 num24 num25 num26 num27 num28 num29
VALUE num0 2 1 142
0
VALUE num4 2 2 143
16
VALUE num5 2 2 144
25
VALUE num9 2 2 145
81
VALUE num12 2 3 146
144
VALUE num15 2 3 147
225
VALUE num16 2 3 148
256
VALUE num19 2 3 149
361
VALUE num20 2 3 150
400
VALUE num22 2 3 151
484
VALUE num26 2 3 152
676
VALUE num27 2 3 153
729
VALUE num28 2 3 154
784
END可以发现在node3上存储了13个键值对
可以发现在3个节点上存储键值对的比例为11:6:13,三个节点上面存储的键值对数量差不多。
设置memcached集群的权重:
#!/usr/bin/python3
"""
@Time : 2019/6/2 21:15
@Author : Mei Zhaohui
@Email : mzh.whut@gmail.com
@File : use_memcached_cluster.py
@Software: PyCharm
"""
import memcache
import time
def main():
"""使用memcached集群,设置权重,按7:2:1权重保存数据"""
mc = memcache.Client(
[
('192.168.56.11:11211', 7),
('192.168.56.12:11211', 2),
('192.168.56.13:11211', 1)
],
debug=True)
mc.flush_all()
for num in range(30):
mc.set('num' + str(num), pow(num, 2))
for num in range(30):
print("mc.get('num{}') = {}".format(num, mc.get('num' + str(num))))
if __name__ == '__main__':
main()在三个节点上面查看键值对信息:
node1 '192.168.56.11:11211':
gets num0 num1 num2 num3 num4 num5 num6 num7 num8 num9 num10 num11 num12 num13 num14 num15 num16 num17 num18 num19 num20 num21 num22 num23 num24 num25 num26 num27 num28 num29
VALUE num1 2 1 305
1
VALUE num2 2 1 306
4
VALUE num3 2 1 307
9
VALUE num4 2 2 308
16
VALUE num6 2 2 309
36
VALUE num8 2 2 310
64
VALUE num9 2 2 311
81
VALUE num10 2 3 312
100
VALUE num12 2 3 313
144
VALUE num14 2 3 314
196
VALUE num15 2 3 315
225
VALUE num16 2 3 316
256
VALUE num18 2 3 317
324
VALUE num19 2 3 318
361
VALUE num20 2 3 319
400
VALUE num21 2 3 320
441
VALUE num23 2 3 321
529
VALUE num28 2 3 322
784
VALUE num29 2 3 323
841
END可以发现在node1上存储了19个键值对
node2 '192.168.56.12:11211':
gets num0 num1 num2 num3 num4 num5 num6 num7 num8 num9 num10 num11 num12 num13 num14 num15 num16 num17 num18 num19 num20 num21 num22 num23 num24 num25 num26 num27 num28 num29
VALUE num0 2 1 142
0
VALUE num13 2 3 143
169
VALUE num17 2 3 144
289
VALUE num24 2 3 145
576
VALUE num26 2 3 146
676
END可以发现在node2上存储了5个键值对
node3 '192.168.56.13:11211':
gets num0 num1 num2 num3 num4 num5 num6 num7 num8 num9 num10 num11 num12 num13 num14 num15 num16 num17 num18 num19 num20 num21 num22 num23 num24 num25 num26 num27 num28 num29
VALUE num5 2 2 168
25
VALUE num7 2 2 169
49
VALUE num11 2 3 170
121
VALUE num22 2 3 171
484
VALUE num25 2 3 172
625
VALUE num27 2 3 173
729
END可以发现在node3上存储了6个键值对
可以发现在3个节点上存储键值对的比例为19:5:6,明显在节点node1上面存储的数据多一些。
redis模块处理NoSQL非关系型数据库Redis
- MySQL是关系型数据库,是持久化存储的,查询检索的话,会涉及到磁盘IO操作,为了提高性能,可以使用缓存技术,Redis和memcached都是缓存数据库,可以大大提升高数据量的web访问速度。
- memcached仅仅支持简单的key-value数据结构,而Redis支持的数据类型更多,如String、Hash、List、Set和Sorted Set。
- web应用中一般采用MySQL+Redis的方式,web应用每次先访问Redis,如果没有找到数据,才去访问MySQL。
- Redis性能极高: Redis读的速度是110000次/s,写的速度是81000次/s。
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis的安装
参考 Redis Quick Start ,可知官方提供使用源码安装,因为Redis除了需要GCC和libc的支持外,没有别有依赖。
下载:
[root@server ~]# wget http://download.redis.io/redis-stable.tar.gz
--2019-06-18 22:20:19-- http://download.redis.io/redis-stable.tar.gz
Resolving download.redis.io (download.redis.io)... 109.74.203.151
Connecting to download.redis.io (download.redis.io)|109.74.203.151|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 2014657 (1.9M) [application/x-gzip]
Saving to: ‘redis-stable.tar.gz.1’
15% [=============> ] 320,584 25.8KB/s eta 63s
[root@server ~]# ls -lah redis-stable.tar.gz
-rw-r--r--. 1 root root 2.0M May 16 00:26 redis-stable.tar.gz解压:
[root@server ~]# tar -zxvf redis-stable.tar.gz切换目录:
[root@server ~]# cd redis-stable编译:
[root@server redis-stable]# make
[root@server redis-stable]# echo $?
0安装:
[root@server redis-stable]# make install
[root@server redis-stable]# echo $?
0说明安装成功!
检查redis命令:
[root@server redis-stable]# redis- 连按两次tab
redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server
[root@server redis-stable]# whereis redis-server
redis-server: /usr/local/bin/redis-server
[root@server redis-stable]# whereis redis-*
redis-*:[root@server redis-stable]# ls -lah /usr/local/bin/redis*
-rwxr-xr-x. 1 root root 4.2M Jun 18 22:28 /usr/local/bin/redis-benchmark
-rwxr-xr-x. 1 root root 7.8M Jun 18 22:28 /usr/local/bin/redis-check-aof
-rwxr-xr-x. 1 root root 7.8M Jun 18 22:28 /usr/local/bin/redis-check-rdb
-rwxr-xr-x. 1 root root 4.6M Jun 18 22:28 /usr/local/bin/redis-cli
lrwxrwxrwx. 1 root root 12 Jun 18 22:28 /usr/local/bin/redis-sentinel -> redis-server
-rwxr-xr-x. 1 root root 7.8M Jun 18 22:28 /usr/local/bin/redis-serverredis-server是Redis Server本身。redis-sentinel是Redis Sentinel可执行文件(监视和故障转移)。redis-cli是与Redis交互的命令行界面实用程序。redis-benchmark用于检查Redis的性能。redis-check-aof和redis-check-dump在极少数损坏的数据文件中很有用。
启动Redis
最简单的启动Redis的方式是直接运行redis-server命令:
[root@server ~]# redis-server
17608:C 18 Jun 2019 22:38:37.232 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
17608:C 18 Jun 2019 22:38:37.232 # Redis version=5.0.5, bits=64, commit=00000000, modified=0, pid=17608, just started
17608:C 18 Jun 2019 22:38:37.232 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
17608:M 18 Jun 2019 22:38:37.233 * Increased maximum number of open files to 10032 (it was originally set to 1024).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.5 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 17608
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
17608:M 18 Jun 2019 22:38:37.233 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
17608:M 18 Jun 2019 22:38:37.233 # Server initialized
17608:M 18 Jun 2019 22:38:37.233 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
17608:M 18 Jun 2019 22:38:37.233 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
17608:M 18 Jun 2019 22:38:37.233 * Ready to accept connections能够正常看到上面的输出则说明Redis安装成功啦!!
检查Redis是否正常工作
在SecureCRT克隆一个Redis-server的新的窗口,并使用redis-cli命令与Redis通信,简单的运行 ping 看是否能ping通:
[root@server ~]# redis-cli ping
PONG
[root@server ~]#
[root@server ~]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> ping
PONG
127.0.0.1:6379>查看redis-cli帮助信息:
127.0.0.1:6379> help
redis-cli 5.0.5
To get help about Redis commands type:
"help @<group>" to get a list of commands in <group>
"help <command>" for help on <command>
"help <tab>" to get a list of possible help topics
"quit" to exit
To set redis-cli preferences:
":set hints" enable online hints
":set nohints" disable online hints
Set your preferences in ~/.redisclirc关闭远程的Redis服务器:
127.0.0.1:6379> help shutdown
SHUTDOWN [NOSAVE|SAVE]
summary: Synchronously save the dataset to disk and then shut down the server
since: 1.0.0
group: server
127.0.0.1:6379> shutdown SAVE
not connected> quit
[root@server ~]#在Redis服务器端的前台可以看到打印的消息如下:
17608:M 18 Jun 2019 22:51:39.238 # User requested shutdown...
17608:M 18 Jun 2019 22:51:39.238 * Saving the final RDB snapshot before exiting.
17608:M 18 Jun 2019 22:51:39.576 * DB saved on disk
17608:M 18 Jun 2019 22:51:39.576 # Redis is now ready to exit, bye bye...说明通信正常,redis-cli能够正常的控制redis-server端工作。
Redis配置
在上面的示例中,Redis在没有任何显式配置文件的情况下启动,因此所有参数都将使用内部默认值。 如果你正在使用它来开发Redis或者用于开发,那么这是完全正常的,但对于生产环境,你应该使用配置文件。
我们使用Redis配置文件。
将源文件中的redis.conf复制到/etc目录下:
[root@server ~]# cp ~/redis-stable/redis.conf /etc/redis.conf
[root@server ~]# ls -lah /etc/redis.conf
-rw-r--r--. 1 root root 61K Jun 18 22:57 /etc/redis.conf前面在启动redis服务器后,都是在前台启动的,需要重新启动一个客户端来进行登陆操作。这样非常不方便,所以我们需要设置后台启动。
修改配置文件,将daemonize no修改为daemonize yes:
[root@server ~]# sed -i '136s/daemonize no/daemonize yes/g' /etc/redis.conf
[root@server ~]# cat -n /etc/redis.conf|sed -n '134,136p'
134 # By default Redis does not run as a daemon. Use 'yes' if you need it.
135 # Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
136 daemonize yes
[root@server ~]#启动Redis时指定配置文件:
[root@server ~]# redis-server /etc/redis.conf
17750:C 18 Jun 2019 23:03:37.223 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
17750:C 18 Jun 2019 23:03:37.223 # Redis version=5.0.5, bits=64, commit=00000000, modified=0, pid=17750, just started
17750:C 18 Jun 2019 23:03:37.223 # Configuration loaded
[root@server ~]# ps -ef|grep redis
root 17751 1 0 23:03 ? 00:00:00 redis-server 127.0.0.1:6379
root 17756 13228 0 23:03 pts/0 00:00:00 grep --color=auto redis
[root@server ~]#
[root@server ~]# redis-cli ping
PONG
[root@server ~]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> shutdown SAVE
not connected>
not connected>
not connected> quit
[root@server ~]# ps -ef|grep redis
root 17766 13228 0 23:07 pts/0 00:00:00 grep --color=auto redis可以发现Redis已经在后台运行了!不需要另外开窗口就可以运行redis-cli命令了!
将Redis配置为系统服务
配置Redis为系统服务实质是在/usr/lib/systemd/system/目录下创建一下redis.service文件。
我们配置一下/usr/lib/systemd/system/redis.service,其内容如下:
[root@server ~]# cat /usr/lib/systemd/system/redis.service
[Unit]
Description=Redis Server Manager
After=network.target
[Service]
Type=forking
PIDFile=/var/run/redis_6379.pid
ExecStartPre=/usr/local/bin/redis-server -v
ExecStartPost=/usr/bin/echo "Done!!!"
ExecStart=/usr/local/bin/redis-server /etc/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/usr/local/bin/redis-cli shutdown
KillSignal=SIGQUIT
TimeoutStopSec=5
KillMode=process
PrivateTmp=true
[Install]
WantedBy=multi-user.target
[root@server ~]#配置一下 /etc/redis.conf 设置一下 logfile 目录,并且创建目录 /var/log/redis/ :
[root@server ~]# cat -n /etc/redis.conf|sed -n '168,172p'
168 # Specify the log file name. Also the empty string can be used to force
169 # Redis to log on the standard output. Note that if you use standard
170 # output for logging but daemonize, logs will be sent to /dev/null
171 logfile "/var/log/redis/redis.log"
172
[root@server ~]# mkdir -p /var/log/redis/重新启动systemctl:
[root@server ~]# systemctl daemon-reload测试Redis的启动、查看状态、停止、重启等:
[root@server ~]# systemctl daemon-reload
# 说明:启动Redis服务
[root@server ~]# systemctl start redis
[root@server ~]# systemctl status redis
● redis.service - Redis Server Manager
Loaded: loaded (/usr/lib/systemd/system/redis.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2019-06-19 22:11:42 CST; 7s ago
Process: 13906 ExecStartPost=/usr/bin/echo Done!!! (code=exited, status=0/SUCCESS)
Process: 13903 ExecStart=/usr/local/bin/redis-server /etc/redis.conf (code=exited, status=0/SUCCESS)
Process: 13901 ExecStartPre=/usr/local/bin/redis-server -v (code=exited, status=0/SUCCESS)
Main PID: 13905 (redis-server)
Tasks: 4
Memory: 6.3M
CGroup: /system.slice/redis.service
└─13905 /usr/local/bin/redis-server 127.0.0.1:6379
Jun 19 22:11:42 server.hopewait systemd[1]: Starting Redis Server Manager...
Jun 19 22:11:42 server.hopewait redis-server[13901]: Redis server v=5.0.5 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=a...9cfcb5
Jun 19 22:11:42 server.hopewait systemd[1]: Started Redis Server Manager.
Jun 19 22:11:42 server.hopewait echo[13906]: Done!!!
Hint: Some lines were ellipsized, use -l to show in full.
[root@server ~]# ps -ef|grep redis
root 13905 1 0 22:11 ? 00:00:00 /usr/local/bin/redis-server 127.0.0.1:6379
root 13914 13280 0 22:12 pts/0 00:00:00 grep --color=auto redis
[root@server ~]# netstat -tunlp|grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 13905/redis-server
# 说明:重启Redis服务
[root@server ~]# systemctl restart redis
[root@server ~]# systemctl status redis
● redis.service - Redis Server Manager
Loaded: loaded (/usr/lib/systemd/system/redis.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2019-06-19 22:13:45 CST; 7s ago
Process: 13928 ExecStop=/usr/local/bin/redis-cli shutdown (code=exited, status=0/SUCCESS)
Process: 13936 ExecStartPost=/usr/bin/echo Done!!! (code=exited, status=0/SUCCESS)
Process: 13933 ExecStart=/usr/local/bin/redis-server /etc/redis.conf (code=exited, status=0/SUCCESS)
Process: 13932 ExecStartPre=/usr/local/bin/redis-server -v (code=exited, status=0/SUCCESS)
Main PID: 13935 (redis-server)
Tasks: 4
Memory: 6.3M
CGroup: /system.slice/redis.service
└─13935 /usr/local/bin/redis-server 127.0.0.1:6379
Jun 19 22:13:45 server.hopewait systemd[1]: Stopped Redis Server Manager.
Jun 19 22:13:45 server.hopewait systemd[1]: Starting Redis Server Manager...
Jun 19 22:13:45 server.hopewait redis-server[13932]: Redis server v=5.0.5 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=a...9cfcb5
Jun 19 22:13:45 server.hopewait systemd[1]: Started Redis Server Manager.
Jun 19 22:13:45 server.hopewait echo[13936]: Done!!!
Hint: Some lines were ellipsized, use -l to show in full.
# 说明:停止Redis服务
[root@server ~]# systemctl stop redis
[root@server ~]# systemctl status redis
● redis.service - Redis Server Manager
Loaded: loaded (/usr/lib/systemd/system/redis.service; disabled; vendor preset: disabled)
Active: inactive (dead)
Jun 19 22:11:42 server.hopewait systemd[1]: Started Redis Server Manager.
Jun 19 22:11:42 server.hopewait echo[13906]: Done!!!
Jun 19 22:13:44 server.hopewait systemd[1]: Stopping Redis Server Manager...
Jun 19 22:13:45 server.hopewait systemd[1]: Stopped Redis Server Manager.
Jun 19 22:13:45 server.hopewait systemd[1]: Starting Redis Server Manager...
Jun 19 22:13:45 server.hopewait redis-server[13932]: Redis server v=5.0.5 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=a...9cfcb5
Jun 19 22:13:45 server.hopewait systemd[1]: Started Redis Server Manager.
Jun 19 22:13:45 server.hopewait echo[13936]: Done!!!
Jun 19 22:15:54 server.hopewait systemd[1]: Stopping Redis Server Manager...
Jun 19 22:15:54 server.hopewait systemd[1]: Stopped Redis Server Manager.
Hint: Some lines were ellipsized, use -l to show in full.
[root@server ~]# ps -ef|grep redis
root 13956 13280 0 22:16 pts/0 00:00:00 grep --color=auto redis将Redis服务加入开机启动:
[root@server ~]# systemctl enable redis
Created symlink from /etc/systemd/system/multi-user.target.wants/redis.service to /usr/lib/systemd/system/redis.service.是否开机自启:
[root@server ~]# systemctl is-enabled redis
enabled修改Redis配置
创建Redis缓存文件目录 /var/redis-data :
[root@server ~]# mkdir -p /var/redis-data
[root@server ~]# ls -lah /var/redis-data/下面介绍几个比较重要的配置:
# 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
# Close the connection after a client is idle for N seconds (0 to disable)
timeout 300
# 后台启动Redis
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
daemonize yes
# 设置PID文件
# If a pid file is specified, Redis writes it where specified at startup
# and removes it at exit.
#
# When the server runs non daemonized, no pid file is created if none is
# specified in the configuration. When the server is daemonized, the pid file
# is used even if not specified, defaulting to "/var/run/redis.pid".
#
# Creating a pid file is best effort: if Redis is not able to create it
# nothing bad happens, the server will start and run normally.
pidfile /var/run/redis_6379.pid
# 指定日志级别
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice
# 指定日志文件,默认值为stdout,标准输出,若后台模式会输出到/dev/null
# Specify the log file name. Also the empty string can be used to force
# Redis to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile "/var/log/redis/redis.log"
# 可用数据库数量
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
# 保存到磁盘,指出在多长时间内,有多少次更新操作,就将数据同步到数据文件rdb
# 默认配置文件中的设置,就设置了三个条件:
# save 900 1 900秒内至少有1个key被改变
# save 300 10 300秒内至少有300个key被改变
# save 60 10000 60秒内至少有10000个key被改变
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
# 本地持久化数据库文件名,默认值为 dump.rdb
# The filename where to dump the DB
dbfilename dump.rdb
# 缓存目录,默认为当前目录./
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /var/redis-data
# 设置最大客户端连接数,默认为10000
# Set the max number of connected clients at the same time. By default
# this limit is set to 10000 clients, however if the Redis server is not
# able to configure the process file limit to allow for the specified limit
# the max number of allowed clients is set to the current file limit
# minus 32 (as Redis reserves a few file descriptors for internal uses).
#
# Once the limit is reached Redis will close all the new connections sending
# an error 'max number of clients reached'.
#
maxclients 128
# 客户端连接密码设置,官方推荐使用防火墙禁止外部连接到Redis,因为是本机访问,可以不设置密码
################################## SECURITY ###################################
# Require clients to issue AUTH <PASSWORD> before processing any other
# commands. This might be useful in environments in which you do not trust
# others with access to the host running redis-server.
#
# This should stay commented out for backward compatibility and because most
# people do not need auth (e.g. they run their own servers).
#
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
# requirepass foobared警告
注意,需要检查上面的 /var/redis-data/ 目录是否创建成功,否则下面的redis重启无法启动!
测试Redis是否保存数据到磁盘,先重启一下Redis服务,再写入数据:
[root@server ~]# systemctl restart redis
[root@server ~]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set firstkey Hello,Redis
OK
127.0.0.1:6379> get firstkey
"Hello,Redis"
127.0.0.1:6379>
127.0.0.1:6379> SAVE
OK
127.0.0.1:6379> quit查看 /var/redis-data/ 目录,发现已经写入数据:
[root@server ~]# ls -lah /var/redis-data/
total 8.0K
drwxr-xr-x. 2 root root 22 Jun 19 23:27 .
drwxr-xr-x. 21 root root 4.0K Jun 19 22:36 ..
-rw-r--r--. 1 root root 119 Jun 19 23:27 dump.rdb为了让远程能够访问Redis服务器,可以防火墙开放6379端口:
[root@server ~]# firewall-cmd --permanent --add-port=6379/tcp
success
[root@server ~]# firewall-cmd --reload
success
[root@server ~]# firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3 enp0s8
sources:
services: ssh dhcpv6-client ftp
ports: 21/tcp 6379/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:redis命令的使用
Redis的命令非常多,如下图所示:


详细可参考 Redis 命令参考
Python处理Redis
- Python的Redis驱动程序
redis-py在GitHub托管代码和测试用例。 - 在线文档https://redis-py.readthedocs.io/en/latest/genindex.html
- 安装
pip install redis
Redis字符串
- 具有单一值的一个键被称作Redis的字符串。简单的Python数据类型可以自动转换成Redis字符串。
下面连接远程主机上指定端口的Redis服务器:
$ ipython
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.
>>> import redis
>>> conn = redis.Redis('192.168.56.103', 6379)
>>> conn
Redis<ConnectionPool<Connection<host=192.168.56.103,port=6379,db=0>>>列出所有的键(目前为空):
>>> conn.keys('*')
... 省略
ConnectionError: Error 10061 connecting to 192.168.56.103:6379. 由于目标计算机积极拒绝,无法连接。.可以发现无法连接到远程Redis服务器,这是由于Redis默认禁止远程访问。
由于Redis增加了 protected-mode 保护机制,并且通过 bind 127.0.0.1 来限制了ip访问,默认为127.0.0.1, 查看 /ect/redis.conf 配置文件内容:
66 # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES
67 # JUST COMMENT THE FOLLOWING LINE.
68 # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
69 bind 127.0.0.1
84 # By default protected mode is enabled. You should disable it only if
85 # you are sure you want clients from other hosts to connect to Redis
86 # even if no authentication is configured, nor a specific set of interfaces
87 # are explicitly listed using the "bind" directive.
88 protected-mode yes
503 # Warning: since Redis is pretty fast an outside user can try up to
504 # 150k passwords per second against a good box. This means that you should
505 # use a very strong password otherwise it will be very easy to break.
506 #
507 # requirepass foobared为了保证Redis服务器的安全,我们给远程访问设置一个访问密码,通过requirepass设置,建议设置一个非常强壮的密码,我这边测试,使用密码123456:
[root@hellolinux ~]# cp /etc/redis.conf /etc/redis.conf.bak
[root@hellolinux ~]# sed -i 's/^# requirepass foobared/requirepass 123456/g' /etc/redis.conf
[root@hellolinux ~]# sed -i 's/^bind 127.0.0.1/#bind 127.0.0.1/g' /etc/redis.conf
[root@hellolinux ~]# diff /etc/redis.conf /etc/redis.conf.bak
69c69
< #bind 127.0.0.1
---
> bind 127.0.0.1
507c507
< requirepass 123456
---
> # requirepass foobared
[root@hellolinux ~]# cat -n /etc/redis.conf|sed -n '69p;507p'
69 #bind 127.0.0.1
507 requirepass 123456重启Redis服务:
[root@hellolinux ~]# systemctl restart redis
[root@hellolinux ~]# systemctl status redis
● redis.service - Redis Server Manager
Loaded: loaded (/usr/lib/systemd/system/redis.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-08-24 23:28:39 CST; 7s ago
Process: 13839 ExecStop=/usr/local/bin/redis-cli shutdown (code=exited, status=0/SUCCESS)
Process: 13847 ExecStartPost=/usr/bin/echo Done!!! (code=exited, status=0/SUCCESS)
Process: 13843 ExecStart=/usr/local/bin/redis-server /etc/redis.conf (code=exited, status=0/SUCCESS)
Process: 13842 ExecStartPre=/usr/local/bin/redis-server -v (code=exited, status=0/SUCCESS)
Main PID: 13846 (redis-server)
CGroup: /system.slice/redis.service
└─13846 /usr/local/bin/redis-server 127.0.0.1:6379
Aug 24 23:28:39 hellolinux.com systemd[1]: Stopped Redis Server Manager.
Aug 24 23:28:39 hellolinux.com systemd[1]: Starting Redis Server Manager...
Aug 24 23:28:39 hellolinux.com redis-server[13842]: Redis server v=5.0.5 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=f7b5a960d4c13390
Aug 24 23:28:39 hellolinux.com echo[13847]: Done!!!
Aug 24 23:28:39 hellolinux.com systemd[1]: Started Redis Server Manager.再次连接远程服务器:
下面连接远程主机上指定端口的Redis服务器:
$ ipython
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.
>>> import redis
>>> conn = redis.Redis(host='192.168.56.103', port=6379,password='123456')
>>> conn
Redis<ConnectionPool<Connection<host=192.168.56.103,port=6379,db=0>>>列出所有的键(目前为空):
>>> conn.keys?
Signature: conn.keys(pattern='*')
Docstring: Returns a list of keys matching ``pattern``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.keys('*')
[]说明已经可以正常取出远程Redis服务器的数据了!
设置和获取数据:
>>> conn.set?
Signature: conn.set(name, value, ex=None, px=None, nx=False, xx=False)
Docstring:
Set the value at key ``name`` to ``value``
``ex`` sets an expire flag on key ``name`` for ``ex`` seconds.
``px`` sets an expire flag on key ``name`` for ``px`` milliseconds.
``nx`` if set to True, set the value at key ``name`` to ``value`` if it
does not already exist.
``xx`` if set to True, set the value at key ``name`` to ``value`` if it
already exists.
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.set('secret','nil')
True
>>> conn.get?
Signature: conn.get(name)
Docstring: Return the value at key ``name``, or None if the key doesn't exist
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.get('secret')
b'nil'
>>> conn.keys('*')
[b'secret']删除键:
>>> conn.delete?
Signature: conn.delete(*names)
Docstring: Delete one or more keys specified by ``names``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.delete('secret')
1
>>> conn.keys('*')
[]依次设置多个值,并获取相应的值:
>>> conn.set('first', 'hello')
True
>>> conn.set('second', 2)
True
>>> conn.set('third', 3.14)
True
>>> conn.get('first')
b'hello'
>>> conn.get('second')
b'2'
>>> conn.get('third')
b'3.14'setnx() 方法 只有当键不存在时 才设定值:
>>> conn.setnx?
Signature: conn.setnx(name, value)
Docstring: Set the value of key ``name`` to ``value`` if key doesn't exist
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.setnx('notexist', 'no')
True
>>> conn.setnx('first', 'hello,redis')
False
>>> conn.get('notexist')
b'no'
>>> conn.get('first')
b'hello'设置'notexist'成功,因为'notexist'不存在;而设置'first'失败,因为之前已经设置了'first'这个键。
getset() 方法会给键设置新值,并返回旧的键值:
>>> conn.getset?
Signature: conn.getset(name, value)
Docstring:
Sets the value at key ``name`` to ``value``
and returns the old value at key ``name`` atomically.
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.getset('first', 'hello,redis')
b'hello'
>>> conn.get('first')
b'hello,redis'getrange() 方法获取键值的子串,start 和 end 都会包含在内:
>>> conn.getrange?
Signature: conn.getrange(key, start, end)
Docstring:
Returns the substring of the string value stored at ``key``,
determined by the offsets ``start`` and ``end`` (both are inclusive)
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.getrange('first', 7, -1)
b'edis'
>>> conn.getrange('first', 6, -1)
b'redis'
>>> conn.getrange('first', 0, 4)
b'hello'
>>> conn.getrange('first', 0,-1)
b'hello,redis'偏移量offset中,0代表开始,-1代表结束。
setrange() 方法对键值的子串进行替换,并返回替换后键值的长度,如果偏移量超过了原来键值的长度,则会使用空值补空占位:
>>> conn.setrange?
Signature: conn.setrange(name, offset, value)
Docstring:
Overwrite bytes in the value of ``name`` starting at ``offset`` with
``value``. If ``offset`` plus the length of ``value`` exceeds the
length of the original value, the new value will be larger than before.
If ``offset`` exceeds the length of the original value, null bytes
will be used to pad between the end of the previous value and the start
of what's being injected.
Returns the length of the new string.
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.setrange('first',6,'Redis')
11
>>> conn.get('first')
b'hello,Redis'
>>> conn.setrange('first', 12, '!!!')
15
>>> conn.get('first')
b'hello,Redis\x00!!!'mset() 一次设置多个键值对,可使用字典或关键字参数创建多个键值对:
>>> conn.mset?
Signature: conn.mset(*args, **kwargs)
Docstring:
Sets key/values based on a mapping. Mapping can be supplied as a single
dictionary argument or as kwargs.
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.keys()
[b'notexist', b'first', b'second', b'third']
# 通过字典创建多个键值对
>>> conn.mset({'four': '4', 'five': 5})
True
>>> conn.keys()
[b'five', b'first', b'third', b'four', b'notexist', b'second']
# 通过关键字参数创建多个键值对
>>> conn.mset(name="Redis",version="5.0.5")
True
>>> conn.keys()
[b'five',
b'first',
b'name',
b'third',
b'four',
b'notexist',
b'version',
b'second']
>>> conn.get('four')
b'4'
>>> conn.get('five')
b'5'
>>> conn.get('name')
b'Redis'
>>> conn.get('version')
b'5.0.5'mget() 一次获取多个键的值:
>>> conn.mget?
Signature: conn.mget(keys, *args)
Docstring: Returns a list of values ordered identically to ``keys``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.mget(['four', 'five', 'name', 'version'])
[b'4', b'5', b'Redis', b'5.0.5']
>>> conn.mget('four', 'five', 'name', 'version')
[b'4', b'5', b'Redis', b'5.0.5']使用 incr() 或 incrbyfloat() 增加值,decr() 减少值, 没有 decrbyfloat() 函数,可以用增加负数代替:
>>> conn.incr?
Signature: conn.incr(name, amount=1)
Docstring:
Increments the value of ``key`` by ``amount``. If no key exists,
the value will be initialized as ``amount``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.incrbyfloat?
Signature: conn.incrbyfloat(name, amount=1.0)
Docstring:
Increments the value at key ``name`` by floating ``amount``.
If no key exists, the value will be initialized as ``amount``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.decr?
Signature: conn.decr(name, amount=1)
Docstring:
Decrements the value of ``key`` by ``amount``. If no key exists,
the value will be initialized as 0 - ``amount``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.incr('four')
5
>>> conn.get('four')
b'5'
>>> conn.incr('four', 2)
7
>>> conn.get('four')
b'7'
>>> conn.incrbyfloat('third')
4.14
>>> conn.get('third')
b'4.14'
>>> conn.incrbyfloat('third', '3')
7.14
>>> conn.get('third')
b'7.14'
>>> conn.decr('four')
6
>>> conn.decr('four', '2')
4
>>> conn.get('four')
b'4'
>>> conn.incrbyfloat('third', '-3')
4.14
>>> conn.get('third')
b'4.14'
>>> conn.incr('four', -2)
2
>>> conn.get('four')
b'2'
>>> conn.incr('four', -2)
0
>>> conn.get('four')
b'0'Redis列表
Redis列表仅能包含字符串。
lpush()朝列表头部插入数据。
向列表'rlist'头部(left)插入数据:
>>> conn.lpush?
Signature: conn.lpush(name, *values)
Docstring: Push ``values`` onto the head of the list ``name``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.lpush('rlist', 'one')
1lrange()获取列表给定偏移量的所有值,start和end不能省略,偏移量0到-1表示获取所有的数据。
获取列表'rlist'刚才插入的数据:
>>> conn.lrange?
Signature: conn.lrange(name, start, end)
Docstring:
Return a slice of the list ``name`` between
position ``start`` and ``end``
``start`` and ``end`` can be negative numbers just like
Python slicing notation
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.lrange('rlist', 0, -1)
[b'one']向列表'rlist'头部(left)一次插入多条数据:
>>> conn.lpush('rlist', 'two', 'three')
3
>>> conn.lrange('rlist', 0, -1)
[b'three', b'two', b'one']可以看到在前的数据会先插入到列表头部,靠后的数据后插入列表头部,如先插入'two',后插入'three'。
linsert()在一个值的前或者后插入数据。
获取列表'rlist'刚才插入的数据:
>>> conn.linsert?
Signature: conn.linsert(name, where, refvalue, value)
Docstring:
Insert ``value`` in list ``name`` either immediately before or after
[``where``] ``refvalue``
Returns the new length of the list on success or -1 if ``refvalue``
is not in the list.
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.linsert('rlist', 'before', 'two', 'before_2')
4
>>> conn.linsert('rlist', 'after', 'two', 'after_2')
5
>>> conn.lrange('rlist', 0, -1)
[b'three', b'before_2', b'two', b'after_2', b'one']可以看出插入数据的前后相对 refvalue 就是列表的前后顺序,我们在Redis服务器上面也可以看到列表数据:
[root@hellolinux ~]# redis-cli -a 123456 2>/dev/null
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> LRANGE rlist 0 -1
1) "three"
2) "before_2"
3) "two"
4) "after_2"
5) "one"
127.0.0.1:6379>lset()替换列表指定索引处的值,index索引必须真实存在,否则会提示"ResponseError: index out of range"异常。
替换列表'rlist'指定索引处的数据:
>>> conn.lset?
Signature: conn.lset(name, index, value)
Docstring: Set ``position`` of list ``name`` to ``value``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
# 先将索引1处的"before_2"替换成了"lset"
>>> conn.lset('rlist', 1, 'lset')
True
>>> conn.lrange('rlist', 0, -1)
[b'three', b'lset', b'two', b'after_2', b'one']
# 再将索引为-1,也就是列表尾部数据替换成"tail"
>>> conn.lset('rlist', -1, 'tail')
True
>>> conn.lrange('rlist', 0, -1)
[b'three', b'lset', b'two', b'after_2', b'tail']此时在Redis服务器上面也可以通过 LRANGE 看到列表数据:
127.0.0.1:6379> LRANGE rlist 0 -1
1) "three"
2) "lset"
3) "two"
4) "after_2"
5) "taillindex()获取列表指定索引处的值,index索引不存在时,返回None。
获取列表'rlist'指定索引处的数据:
>>> conn.lindex?
Signature: conn.lindex(name, index)
Docstring:
Return the item from list ``name`` at position ``index``
Negative indexes are supported and will return an item at the
end of the list
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
# 获取索引1处的值
>>> conn.lindex('rlist', 1)
b'lset'
# 获取索引0处的值,也就是列表头部
>>> conn.lindex('rlist', 0)
b'three'
# 获取索引-1处的值,也就是列表尾部
>>> conn.lindex('rlist', -1)
b'tail'
>>> conn.lindex('rlist', -2)
b'after_2'此时在Redis服务器上面也可以通过 LINDEX 看到列表数据:
127.0.0.1:6379> LINDEX rlist 1
"lset"
127.0.0.1:6379> LINDEX rlist 0
"three"
127.0.0.1:6379> LINDEX rlist -1
"tail"
127.0.0.1:6379> LINDEX rlist -2
"after_2"llen()获取列表的长度 。
获取列表'rlist'的长度:
>>> conn.llen?
Signature: conn.llen(name)
Docstring: Return the length of the list ``name``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.llen('rlist')
5此时在Redis服务器上面也可以通过 LLEN 看到列表的长度:
127.0.0.1:6379> LLEN rlist
(integer) 5lpop()将列表头部的第一个元素弹出。
获取列表'rlist'指定索引处的数据:
>>> conn.lpop?
Signature: conn.lpop(name)
Docstring: Remove and return the first item of the list ``name``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.lpop('rlist')
b'three'
>>> conn.lrange('rlist', 0, -1)
[b'lset', b'two', b'after_2', b'tail']此时在Redis服务器上面查看数据,可以发现头部的第一个元素"three"已经被弹出,即删除掉了:
127.0.0.1:6379> LRANGE rlist 0 -1
1) "lset"
2) "two"
3) "after_2"
4) "tail"lpushx()将列表(列表必须存在)头部的插入数据。
向不存在、存在的列表中插入数据:
>>> conn.lpushx?
Signature: conn.lpushx(name, value)
Docstring: Push ``value`` onto the head of the list ``name`` if ``name`` exists
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
# 列表"a"不存在,插入数据失败
>>> conn.lpushx('a', 'b')
0
# 获取到空列表
>>> conn.lrange('a', 0, -1)
[]
# 向已经存在的"rlist"插入数据,插入数据成功
>>> conn.lpushx('rlist', 'lpushx')
5
>>> conn.lrange('rlist', 0, -1)
[b'lpushx', b'lset', b'two', b'after_2', b'tail']lastsave()返回Redis数据库保存到磁盘的最后时间。
查看数据保存到磁盘的最后时间:
>>> conn.lastsave?
Signature: conn.lastsave()
Docstring:
Return a Python datetime object representing the last time the
Redis database was saved to disk
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.lastsave
<bound method StrictRedis.lastsave of Redis<ConnectionPool<Connection<host=192.168.56.103,port=6379,db=0>>>>
>>> conn.lastsave()
datetime.datetime(2019, 8, 25, 19, 59, 16)rpush()朝列表尾部插入数据。
向列表尾部和头部一次插入多个数据:
>>> conn.rpush?
Signature: conn.rpush(name, *values)
Docstring: Push ``values`` onto the tail of the list ``name``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.lrange('rlist', 0, -1)
[b'lpushx', b'lset', b'two', b'after_2', b'tail']
>>> conn.rpush('rlist', 'push', 'push','push','push')
9
>>> conn.lrange('rlist', 0, -1)
[b'lpushx',
b'lset',
b'two',
b'after_2',
b'tail',
b'push',
b'push',
b'push',
b'push']
>>> conn.lpush('rlist', 'push', 'push','push','push')
13
>>> conn.lrange('rlist', 0, -1)
[b'push',
b'push',
b'push',
b'push',
b'lpushx',
b'lset',
b'two',
b'after_2',
b'tail',
b'push',
b'push',
b'push',
b'push']lrem()移除列表中指定数量的值。
删除列表尾部和头部指定的数据:
>>> conn.lrem?
Signature: conn.lrem(name, value, num=0)
Docstring:
Remove the first ``num`` occurrences of elements equal to ``value``
from the list stored at ``name``.
The ``num`` argument influences the operation in the following ways:
num > 0: Remove elements equal to value moving from head to tail.
num < 0: Remove elements equal to value moving from tail to head.
num = 0: Remove all elements equal to value.
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
# 删除头部的1个"push",头部剩余3个"push"
>>> conn.lrem('rlist', 'push', 1)
1
>>> conn.lrange('rlist', 0, -1)
[b'push',
b'push',
b'push',
b'lpushx',
b'lset',
b'two',
b'after_2',
b'tail',
b'push',
b'push',
b'push',
b'push']
# 删除头部的2个"push" ,头部剩余1个"push"
>>> conn.lrem('rlist', 'push', 2)
2
>>> conn.lrange('rlist', 0, -1)
[b'push',
b'lpushx',
b'lset',
b'two',
b'after_2',
b'tail',
b'push',
b'push',
b'push',
b'push']
# 删除尾部的3个"push" ,尾部剩余1个"push"
>>> conn.lrem('rlist', 'push', -3)
3
>>> conn.lrange('rlist', 0, -1)
[b'push', b'lpushx', b'lset', b'two', b'after_2', b'tail', b'push']
# 删除剩余的所有的"push",最后没有"push"
>>> conn.lrem('rlist', 'push', 0)
2
>>> conn.lrange('rlist', 0, -1)
[b'lpushx', b'lset', b'two', b'after_2', b'tail']ltrim()仅保留列表中指定范围内的值。
仅保留指定范围内的值:
>>> conn.ltrim?
Signature: conn.ltrim(name, start, end)
Docstring:
Trim the list ``name``, removing all values not within the slice
between ``start`` and ``end``
``start`` and ``end`` can be negative numbers just like
Python slicing notation
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
# 仅保留索引1和索引2处的值,'lpushx','after_2','tail'被删除
>>> conn.ltrim('rlist', 1, 2)
True
>>> conn.lrange('rlist', 0, -1)
[b'lset', b'two']
>>> conn.ltrim('rlist', 0, 0)
True
>>> conn.lrange('rlist', 0, -1)
[b'lset']rpush()朝列表( 列表必须存在 )尾部插入数据。
向列表尾部插入一个数据:
>>> conn.rpushx?
Signature: conn.rpushx(name, value)
Docstring: Push ``value`` onto the tail of the list ``name`` if ``name`` exists
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.rpushx('rlist', 'push')
2
>>> conn.lrange('rlist', 0, -1)
[b'lset', b'push']rpop()从列表尾部弹出数据,即删除列表尾部的数据。
从列表尾部弹出数据:
>>> conn.rpop?
Signature: conn.rpop(name)
Docstring: Remove and return the last item of the list ``name``
File: d:\programfiles\python362\lib\site-packages\redis\client.py
Type: method
>>> conn.rpop('rlist')
b'push'
>>> conn.rpop('rlist')
b'lset'
>>> conn.lrange('rlist', 0, -1)
[]参考文献:
- sqlite3 — DB-API 2.0 interface for SQLite databases
- Welcome to PyMySQL’s documentation!
- SQLAlchemy 1.3 Documentation: Object Relational Tutorial
- SQLAlchemy 1.3 Documentation: Working with Engines and Connections
- SQLAlchemy 1.3 Documentation: Engine Configuration
- SQLAlchemy 1.3 Documentation: Database Urls
- SQLAlchemy 1.3 Documentation: Query API
- dataset: databases for lazy people
- dataset: databases for lazy people: API documentation
- dataset: databases for lazy people: Quickstart
- Python的"懒人"包DataSet解析
- Redis Quick Start
- Redis安装与卸载
- redis常用命令、常见错误、配置技巧等分享
- centos下部署redis服务环境及其配置说明
- Redis 命令参考