JSON解析工具-jq
jq 是一个轻量级而且灵活的命令行 JSON 解析器,类似用于 JSON 数据的 sed 工具。
- jq官网地址:https://stedolan.github.io/jq/
- 官方教程:https://stedolan.github.io/jq/tutorial/
- 官方手册:https://stedolan.github.io/jq/manual/
- 源码地址:https://github.com/stedolan/jq/
1. 安装
我们可以直接使用yum安装。
查看jq包的信息:
$ yum info jq
Loaded plugins: fastestmirror, langpacks
Repository epel is listed more than once in the configuration
Repository google-chrome is listed more than once in the configuration
Loading mirror speeds from cached hostfile
* webtatic: us-east.repo.webtatic.com
Installed Packages
Name : jq
Arch : x86_64
Version : 1.6
Release : 2.el7
Size : 381 k
Repo : installed
From repo : epel
Summary : Command-line JSON processor
URL : http://stedolan.github.io/jq/
License : MIT and ASL 2.0 and CC-BY and GPLv3
Description : lightweight and flexible command-line JSON processor
:
: jq is like sed for JSON data – you can use it to slice
: and filter and map and transform structured data with
: the same ease that sed, awk, grep and friends let you
: play with text.
:
: It is written in portable C, and it has zero runtime
: dependencies.
:
: jq can mangle the data format that you have into the
: one that you want with very little effort, and the
: program to do so is often shorter and simpler than
: you'd expect.
$安装:
$ sudo yum install -y jq
Loaded plugins: fastestmirror, langpacks
Repository epel is listed more than once in the configuration
Repository google-chrome is listed more than once in the configuration
Loading mirror speeds from cached hostfile
* webtatic: uk.repo.webtatic.com
Resolving Dependencies
--> Running transaction check
---> Package jq.x86_64 0:1.6-2.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
========================================================================================================================
Package Arch Version Repository Size
========================================================================================================================
Installing:
jq x86_64 1.6-2.el7 epel 167 k
Transaction Summary
========================================================================================================================
Install 1 Package
Total download size: 167 k
Installed size: 381 k
Downloading packages:
jq-1.6-2.el7.x86_64.rpm | 167 kB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : jq-1.6-2.el7.x86_64 1/1
Verifying : jq-1.6-2.el7.x86_64 1/1
Installed:
jq.x86_64 0:1.6-2.el7
Complete!
$2. 基本使用
查看jq的版本信息和帮助信息:
$ jq --version
jq-1.6
$ jq --help
jq - commandline JSON processor [version 1.6]
Usage: jq [options] <jq filter> [file...]
jq [options] --args <jq filter> [strings...]
jq [options] --jsonargs <jq filter> [JSON_TEXTS...]
jq is a tool for processing JSON inputs, applying the given filter to
its JSON text inputs and producing the filter's results as JSON on
standard output.
The simplest filter is ., which copies jq's input to its output
unmodified (except for formatting, but note that IEEE754 is used
for number representation internally, with all that that implies).
For more advanced filters see the jq(1) manpage ("man jq")
and/or https://stedolan.github.io/jq
Example:
$ echo '{"foo": 0}' | jq .
{
"foo": 0
}
Some of the options include:
-c compact instead of pretty-printed output;
-n use `null` as the single input value;
-e set the exit status code based on the output;
-s read (slurp) all inputs into an array; apply filter to it;
-r output raw strings, not JSON texts;
-R read raw strings, not JSON texts;
-C colorize JSON;
-M monochrome (don't colorize JSON);
-S sort keys of objects on output;
--tab use tabs for indentation;
--arg a v set variable $a to value <v>;
--argjson a v set variable $a to JSON value <v>;
--slurpfile a f set variable $a to an array of JSON texts read from <f>;
--rawfile a f set variable $a to a string consisting of the contents of <f>;
--args remaining arguments are string arguments, not files;
--jsonargs remaining arguments are JSON arguments, not files;
-- terminates argument processing;
Named arguments are also available as $ARGS.named[], while
positional arguments are available as $ARGS.positional[].
See the manpage for more options.
$2.1 按tutorial教程进行简单测试
2.1.1 获取原始数据
GitHub提供JSON API,我们从jq仓库获取最新的3个提交。
$ curl -s 'https://api.github.com/repos/stedolan/jq/commits?per_page=3'
[
{
"sha": "d18b2d078c2383d9472d0a0a226e07009025574f",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTpkMThiMmQwNzhjMjM4M2Q5NDcyZDBhMGEyMjZlMDcwMDkwMjU1NzRm",
"commit": {
"author": {
"name": "itchyny",
"email": "itchyny@hatena.ne.jp",
"date": "2020-10-08T06:20:11Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:34:26Z"
},
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"tree": {
"sha": "57806511d068cc7af6f857baf8d4b84b340f9990",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/57806511d068cc7af6f857baf8d4b84b340f9990"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"html_url": "https://github.com/stedolan/jq/commit/d18b2d078c2383d9472d0a0a226e07009025574f",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/d18b2d078c2383d9472d0a0a226e07009025574f/comments",
"author": {
"login": "itchyny",
"id": 375258,
"node_id": "MDQ6VXNlcjM3NTI1OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/375258?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/itchyny",
"html_url": "https://github.com/itchyny",
"followers_url": "https://api.github.com/users/itchyny/followers",
"following_url": "https://api.github.com/users/itchyny/following{/other_user}",
"gists_url": "https://api.github.com/users/itchyny/gists{/gist_id}",
"starred_url": "https://api.github.com/users/itchyny/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itchyny/subscriptions",
"organizations_url": "https://api.github.com/users/itchyny/orgs",
"repos_url": "https://api.github.com/users/itchyny/repos",
"events_url": "https://api.github.com/users/itchyny/events{/privacy}",
"received_events_url": "https://api.github.com/users/itchyny/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"html_url": "https://github.com/stedolan/jq/commit/cc4efc49e1eedb98289347bf264c50c5c8656e7c"
}
]
},
{
"sha": "cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTpjYzRlZmM0OWUxZWVkYjk4Mjg5MzQ3YmYyNjRjNTBjNWM4NjU2ZTdj",
"commit": {
"author": {
"name": "Mattias Wadman",
"email": "mattias.wadman@gmail.com",
"date": "2021-02-21T16:49:23Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:33:01Z"
},
"message": "Fix incorrect if empty string example",
"tree": {
"sha": "ed9619cf4d31a028a8dd60eb6d313f5c3057372a",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/ed9619cf4d31a028a8dd60eb6d313f5c3057372a"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"html_url": "https://github.com/stedolan/jq/commit/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c/comments",
"author": {
"login": "wader",
"id": 185566,
"node_id": "MDQ6VXNlcjE4NTU2Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/185566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wader",
"html_url": "https://github.com/wader",
"followers_url": "https://api.github.com/users/wader/followers",
"following_url": "https://api.github.com/users/wader/following{/other_user}",
"gists_url": "https://api.github.com/users/wader/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wader/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wader/subscriptions",
"organizations_url": "https://api.github.com/users/wader/orgs",
"repos_url": "https://api.github.com/users/wader/repos",
"events_url": "https://api.github.com/users/wader/events{/privacy}",
"received_events_url": "https://api.github.com/users/wader/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "e615bdc407ddcb82f1d78f1651464ad28e287954",
"url": "https://api.github.com/repos/stedolan/jq/commits/e615bdc407ddcb82f1d78f1651464ad28e287954",
"html_url": "https://github.com/stedolan/jq/commit/e615bdc407ddcb82f1d78f1651464ad28e287954"
}
]
},
{
"sha": "e615bdc407ddcb82f1d78f1651464ad28e287954",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTplNjE1YmRjNDA3ZGRjYjgyZjFkNzhmMTY1MTQ2NGFkMjhlMjg3OTU0",
"commit": {
"author": {
"name": "mjarosie",
"email": "mjarosie@users.noreply.github.com",
"date": "2021-02-01T21:09:22Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:32:38Z"
},
"message": "update the version available through Chocolatey",
"tree": {
"sha": "a90395af69a11ed29f935c651fa82125492e2697",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/a90395af69a11ed29f935c651fa82125492e2697"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/e615bdc407ddcb82f1d78f1651464ad28e287954",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/e615bdc407ddcb82f1d78f1651464ad28e287954",
"html_url": "https://github.com/stedolan/jq/commit/e615bdc407ddcb82f1d78f1651464ad28e287954",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/e615bdc407ddcb82f1d78f1651464ad28e287954/comments",
"author": {
"login": "mjarosie",
"id": 9082353,
"node_id": "MDQ6VXNlcjkwODIzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9082353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mjarosie",
"html_url": "https://github.com/mjarosie",
"followers_url": "https://api.github.com/users/mjarosie/followers",
"following_url": "https://api.github.com/users/mjarosie/following{/other_user}",
"gists_url": "https://api.github.com/users/mjarosie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mjarosie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mjarosie/subscriptions",
"organizations_url": "https://api.github.com/users/mjarosie/orgs",
"repos_url": "https://api.github.com/users/mjarosie/repos",
"events_url": "https://api.github.com/users/mjarosie/events{/privacy}",
"received_events_url": "https://api.github.com/users/mjarosie/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "9600a5c78141051adc08362b9c5446a15ae4d9a4",
"url": "https://api.github.com/repos/stedolan/jq/commits/9600a5c78141051adc08362b9c5446a15ae4d9a4",
"html_url": "https://github.com/stedolan/jq/commit/9600a5c78141051adc08362b9c5446a15ae4d9a4"
}
]
}
]
$此时,可以看到,GitHub返回格式化好的json。 对于不这样的服务器,通过jq将通过管道漂亮打印出结果。
2.1.2 美化json输出
最简单的jq程序是表达式.,它取得了输入,并将其与输出保持不变。
$ curl -s 'https://api.github.com/repos/stedolan/jq/commits?per_page=3'|jq '.'
[
{
"sha": "d18b2d078c2383d9472d0a0a226e07009025574f",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTpkMThiMmQwNzhjMjM4M2Q5NDcyZDBhMGEyMjZlMDcwMDkwMjU1NzRm",
"commit": {
"author": {
"name": "itchyny",
"email": "itchyny@hatena.ne.jp",
"date": "2020-10-08T06:20:11Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:34:26Z"
},
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"tree": {
"sha": "57806511d068cc7af6f857baf8d4b84b340f9990",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/57806511d068cc7af6f857baf8d4b84b340f9990"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"html_url": "https://github.com/stedolan/jq/commit/d18b2d078c2383d9472d0a0a226e07009025574f",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/d18b2d078c2383d9472d0a0a226e07009025574f/comments",
"author": {
"login": "itchyny",
"id": 375258,
"node_id": "MDQ6VXNlcjM3NTI1OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/375258?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/itchyny",
"html_url": "https://github.com/itchyny",
"followers_url": "https://api.github.com/users/itchyny/followers",
"following_url": "https://api.github.com/users/itchyny/following{/other_user}",
"gists_url": "https://api.github.com/users/itchyny/gists{/gist_id}",
"starred_url": "https://api.github.com/users/itchyny/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itchyny/subscriptions",
"organizations_url": "https://api.github.com/users/itchyny/orgs",
"repos_url": "https://api.github.com/users/itchyny/repos",
"events_url": "https://api.github.com/users/itchyny/events{/privacy}",
"received_events_url": "https://api.github.com/users/itchyny/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"html_url": "https://github.com/stedolan/jq/commit/cc4efc49e1eedb98289347bf264c50c5c8656e7c"
}
]
},
{
"sha": "cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTpjYzRlZmM0OWUxZWVkYjk4Mjg5MzQ3YmYyNjRjNTBjNWM4NjU2ZTdj",
"commit": {
"author": {
"name": "Mattias Wadman",
"email": "mattias.wadman@gmail.com",
"date": "2021-02-21T16:49:23Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:33:01Z"
},
"message": "Fix incorrect if empty string example",
"tree": {
"sha": "ed9619cf4d31a028a8dd60eb6d313f5c3057372a",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/ed9619cf4d31a028a8dd60eb6d313f5c3057372a"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"html_url": "https://github.com/stedolan/jq/commit/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c/comments",
"author": {
"login": "wader",
"id": 185566,
"node_id": "MDQ6VXNlcjE4NTU2Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/185566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wader",
"html_url": "https://github.com/wader",
"followers_url": "https://api.github.com/users/wader/followers",
"following_url": "https://api.github.com/users/wader/following{/other_user}",
"gists_url": "https://api.github.com/users/wader/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wader/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wader/subscriptions",
"organizations_url": "https://api.github.com/users/wader/orgs",
"repos_url": "https://api.github.com/users/wader/repos",
"events_url": "https://api.github.com/users/wader/events{/privacy}",
"received_events_url": "https://api.github.com/users/wader/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "e615bdc407ddcb82f1d78f1651464ad28e287954",
"url": "https://api.github.com/repos/stedolan/jq/commits/e615bdc407ddcb82f1d78f1651464ad28e287954",
"html_url": "https://github.com/stedolan/jq/commit/e615bdc407ddcb82f1d78f1651464ad28e287954"
}
]
},
{
"sha": "e615bdc407ddcb82f1d78f1651464ad28e287954",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTplNjE1YmRjNDA3ZGRjYjgyZjFkNzhmMTY1MTQ2NGFkMjhlMjg3OTU0",
"commit": {
"author": {
"name": "mjarosie",
"email": "mjarosie@users.noreply.github.com",
"date": "2021-02-01T21:09:22Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:32:38Z"
},
"message": "update the version available through Chocolatey",
"tree": {
"sha": "a90395af69a11ed29f935c651fa82125492e2697",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/a90395af69a11ed29f935c651fa82125492e2697"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/e615bdc407ddcb82f1d78f1651464ad28e287954",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/e615bdc407ddcb82f1d78f1651464ad28e287954",
"html_url": "https://github.com/stedolan/jq/commit/e615bdc407ddcb82f1d78f1651464ad28e287954",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/e615bdc407ddcb82f1d78f1651464ad28e287954/comments",
"author": {
"login": "mjarosie",
"id": 9082353,
"node_id": "MDQ6VXNlcjkwODIzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9082353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mjarosie",
"html_url": "https://github.com/mjarosie",
"followers_url": "https://api.github.com/users/mjarosie/followers",
"following_url": "https://api.github.com/users/mjarosie/following{/other_user}",
"gists_url": "https://api.github.com/users/mjarosie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mjarosie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mjarosie/subscriptions",
"organizations_url": "https://api.github.com/users/mjarosie/orgs",
"repos_url": "https://api.github.com/users/mjarosie/repos",
"events_url": "https://api.github.com/users/mjarosie/events{/privacy}",
"received_events_url": "https://api.github.com/users/mjarosie/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "9600a5c78141051adc08362b9c5446a15ae4d9a4",
"url": "https://api.github.com/repos/stedolan/jq/commits/9600a5c78141051adc08362b9c5446a15ae4d9a4",
"html_url": "https://github.com/stedolan/jq/commit/9600a5c78141051adc08362b9c5446a15ae4d9a4"
}
]
}
]
$此时,我们可以看到,虽然结果相同,但现在的输出结果中,已经美化过了,变得非常漂亮了。
为了加快我们测试,我先将curl请求的结果保存到本地文件中。
$ curl -s 'https://api.github.com/repos/stedolan/jq/commits?per_page=3' > data.json
$2.1.3 获取单一子元素
获取第一个提交。
$ cat data.json |jq '.[0]'
{
"sha": "d18b2d078c2383d9472d0a0a226e07009025574f",
"node_id": "MDY6Q29tbWl0NTEwMTE0MTpkMThiMmQwNzhjMjM4M2Q5NDcyZDBhMGEyMjZlMDcwMDkwMjU1NzRm",
"commit": {
"author": {
"name": "itchyny",
"email": "itchyny@hatena.ne.jp",
"date": "2020-10-08T06:20:11Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:34:26Z"
},
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"tree": {
"sha": "57806511d068cc7af6f857baf8d4b84b340f9990",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/57806511d068cc7af6f857baf8d4b84b340f9990"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
},
"url": "https://api.github.com/repos/stedolan/jq/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"html_url": "https://github.com/stedolan/jq/commit/d18b2d078c2383d9472d0a0a226e07009025574f",
"comments_url": "https://api.github.com/repos/stedolan/jq/commits/d18b2d078c2383d9472d0a0a226e07009025574f/comments",
"author": {
"login": "itchyny",
"id": 375258,
"node_id": "MDQ6VXNlcjM3NTI1OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/375258?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/itchyny",
"html_url": "https://github.com/itchyny",
"followers_url": "https://api.github.com/users/itchyny/followers",
"following_url": "https://api.github.com/users/itchyny/following{/other_user}",
"gists_url": "https://api.github.com/users/itchyny/gists{/gist_id}",
"starred_url": "https://api.github.com/users/itchyny/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/itchyny/subscriptions",
"organizations_url": "https://api.github.com/users/itchyny/orgs",
"repos_url": "https://api.github.com/users/itchyny/repos",
"events_url": "https://api.github.com/users/itchyny/events{/privacy}",
"received_events_url": "https://api.github.com/users/itchyny/received_events",
"type": "User",
"site_admin": false
},
"committer": {
"login": "wtlangford",
"id": 3422295,
"node_id": "MDQ6VXNlcjM0MjIyOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3422295?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wtlangford",
"html_url": "https://github.com/wtlangford",
"followers_url": "https://api.github.com/users/wtlangford/followers",
"following_url": "https://api.github.com/users/wtlangford/following{/other_user}",
"gists_url": "https://api.github.com/users/wtlangford/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wtlangford/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wtlangford/subscriptions",
"organizations_url": "https://api.github.com/users/wtlangford/orgs",
"repos_url": "https://api.github.com/users/wtlangford/repos",
"events_url": "https://api.github.com/users/wtlangford/events{/privacy}",
"received_events_url": "https://api.github.com/users/wtlangford/received_events",
"type": "User",
"site_admin": false
},
"parents": [
{
"sha": "cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"url": "https://api.github.com/repos/stedolan/jq/commits/cc4efc49e1eedb98289347bf264c50c5c8656e7c",
"html_url": "https://github.com/stedolan/jq/commit/cc4efc49e1eedb98289347bf264c50c5c8656e7c"
}
]
}
$2.1.4 元素过滤
有很多信息我们不关心,我们可以过滤出我们关心的字段。
如我们只关心commit信息:
$ cat data.json |jq '.[0].commit'
{
"author": {
"name": "itchyny",
"email": "itchyny@hatena.ne.jp",
"date": "2020-10-08T06:20:11Z"
},
"committer": {
"name": "William Langford",
"email": "wlangfor@gmail.com",
"date": "2021-05-01T18:34:26Z"
},
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"tree": {
"sha": "57806511d068cc7af6f857baf8d4b84b340f9990",
"url": "https://api.github.com/repos/stedolan/jq/git/trees/57806511d068cc7af6f857baf8d4b84b340f9990"
},
"url": "https://api.github.com/repos/stedolan/jq/git/commits/d18b2d078c2383d9472d0a0a226e07009025574f",
"comment_count": 0,
"verification": {
"verified": false,
"reason": "unsigned",
"signature": null,
"payload": null
}
}
$现在如果我们只关心第一个提交的message和提交人的name姓名信息,则可以这样:
$ cat data.json |jq '.[0] | {message: .commit.message, name: .commit.committer.name}'{ "message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers", "name": "William Langford"}$ cat data.json |jq '.[0] | {CommitMessage: .commit.message, CommitterName: .commit.committer.name}'{ "CommitMessage": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers", "CommitterName": "William Langford"}$效果如下图:
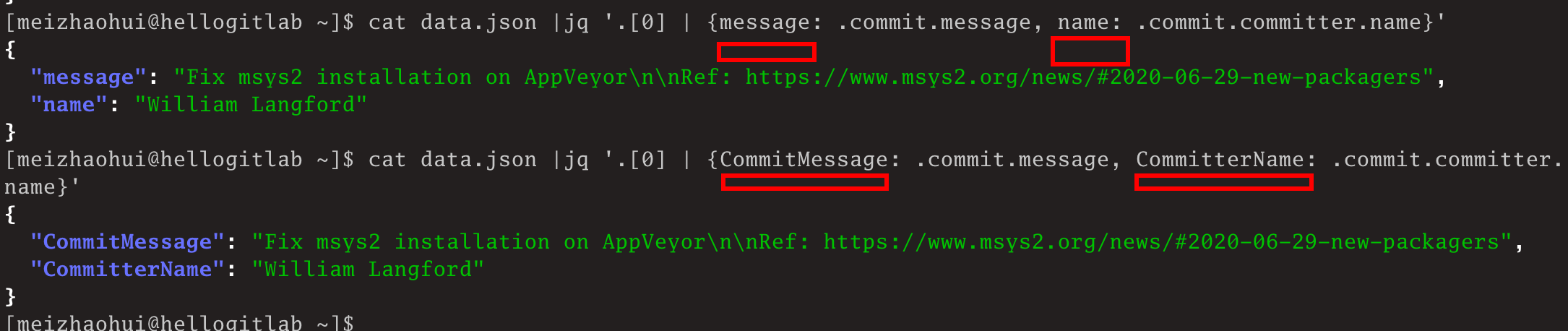
可以看到,我们在jq命令内部的管道中,通过类似message/name或CommitMessage/CommitterName等来定义最后要显示的字段的名称,而通过.commit.message或.commit.committer.name来获取json数据中的关键信息。你可以通过.点号来访问嵌套属性,如.commit.committer.name。
2.1.5 对所有元素进行过滤
对所有元素进行过滤。
获取所有的提交的提交消息和提交人信息。
$ cat data.json |jq '.[] | {message: .commit.message, name: .commit.committer.name}'
{
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"name": "William Langford"
}
{
"message": "Fix incorrect if empty string example",
"name": "William Langford"
}
{
"message": "update the version available through Chocolatey",
"name": "William Langford"
}
.[]returns each element of the array returned in the response, one at a time, which are all fed into{message: .commit.message, name: .commit.committer.name}.
.[]返回列表中的每一个元素,一次返回一个,并送入到后面的过滤器中。
在jq中数据是以流的形式进行传输的,每个jq表达式对其输入流的每个值进行操作,然后在输出流中可以生成任何数量的值。
只需要将json值与空格分开来序列化,这是一种cat友好的格式。你可以将两个json流合并到一起,并形成一个有效的json流。
2.1.6 生成单个数组
如果您想将输出作为单个数组,您可以通过将过滤器包装在方括号中来告诉 jq收集所有结果。
你可以像下面这样:
$ cat data.json |jq '[.[] | {message: .commit.message, name: .commit.committer.name}]'
[
{
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"name": "William Langford"
},
{
"message": "Fix incorrect if empty string example",
"name": "William Langford"
},
{
"message": "update the version available through Chocolatey",
"name": "William Langford"
}
]可以看到,已经将结果集中的三个对象放在数组中了。
2.1.7 获取子元素的列表
每一个提交都有可能有多个父提交。现在我们来获取每个提交的父提交的散列值。
$ cat data.json |jq '[.[] | {message: .commit.message, name: .commit.committer.name, parents: [.parents[].sha]}]'
[
{
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"name": "William Langford",
"parents": [
"cc4efc49e1eedb98289347bf264c50c5c8656e7c"
]
},
{
"message": "Fix incorrect if empty string example",
"name": "William Langford",
"parents": [
"e615bdc407ddcb82f1d78f1651464ad28e287954"
]
},
{
"message": "update the version available through Chocolatey",
"name": "William Langford",
"parents": [
"9600a5c78141051adc08362b9c5446a15ae4d9a4"
]
}
]3. jq手册页
你可以访问 https://stedolan.github.io/jq/manual/ 获取在线手册页,也可以使用man jq命令获取jq的手册页。
jq程序是一个过滤器,对输入流进入处理,然后返回输出流。jq有很多内置的过滤器。- 可以对过滤器进行多种方式的组合。
下面我们一点点的来了解jq手册页中的内容,从简单的开始入手。
3.1 调用jq
jq filters run on a stream of JSON data. The input to jq is parsed as a sequence of whitespace-separated JSON values which are passed through the provided filter one at a time. The output(s) of the filter are written to standard out, again as a sequence of whitespace-separated JSON data.
jq过滤器运行在JSON数据流上。输入流是以whitespace分隔的JSON序列,输出流是以whitespace分隔的JSON序列,并输出到标准输出。- 注意,在使用
jq时,请使用单引号'进行引用,不要使用双引号,如jq "foo"将被理解为jq foo,此时会提示foo未定义。
3.1.1 查看jq版本信息
$ jq --version
jq-1.63.1.2 查看帮助信息
可以通过man jq查看jq的手册页,也可以使用jq --help获取简单的帮助信息。
$ jq --help
jq - commandline JSON processor [version 1.6]
Usage: jq [options] <jq filter> [file...]
jq [options] --args <jq filter> [strings...]
jq [options] --jsonargs <jq filter> [JSON_TEXTS...]
jq is a tool for processing JSON inputs, applying the given filter to
its JSON text inputs and producing the filter's results as JSON on
standard output.
The simplest filter is ., which copies jq's input to its output
unmodified (except for formatting, but note that IEEE754 is used
for number representation internally, with all that that implies).
For more advanced filters see the jq(1) manpage ("man jq")
and/or https://stedolan.github.io/jq
Example:
$ echo '{"foo": 0}' | jq .
{
"foo": 0
}
Some of the options include:
-c compact instead of pretty-printed output;
-n use `null` as the single input value;
-e set the exit status code based on the output;
-s read (slurp) all inputs into an array; apply filter to it;
-r output raw strings, not JSON texts;
-R read raw strings, not JSON texts;
-C colorize JSON;
-M monochrome (don't colorize JSON);
-S sort keys of objects on output;
--tab use tabs for indentation;
--arg a v set variable $a to value <v>;
--argjson a v set variable $a to JSON value <v>;
--slurpfile a f set variable $a to an array of JSON texts read from <f>;
--rawfile a f set variable $a to a string consisting of the contents of <f>;
--args remaining arguments are string arguments, not files;
--jsonargs remaining arguments are JSON arguments, not files;
-- terminates argument processing;
Named arguments are also available as $ARGS.named[], while
positional arguments are available as $ARGS.positional[].
See the manpage for more options.
$3.1.3 忽略参数
现阶段有些参数不明白什么意思。此处记录一下。
--seq:使用 application/json-seq MIME 类型方案在 jq 的输入和输出中分隔 JSON 文本。--stream: 以流形式解析输入。--unbuffered: 如果有慢速数据源输入到jq的话,打印每个JSON对象后刷新输出。-Ldirectory/-L directory: 在指定目录搜索模块,此时将忽略内置模块。-e/--exit-status: 退出码设置。
3.1.4 将JSON数据一次读入到数组中
--slurp/-s参数可以一次将JSON数据读入到数组中。
请看以下示例。
我们先准备一个测试用的JSON文件test.json,文件内容如下:
{"name":"网站","num":3,"sites":["Google", "Runoob", "Taobao"]}测试数据来源: https://www.runoob.com/json/js-json-arrays.html
先不使用参数,直接输出,看看效果:
$ cat test.json |jq
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}使用-s或--slurp参数,查看输出结果:
$ cat test.json |jq -s
[
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
]可以看到,在输出结果中多出了第一行的[和最后一行的]。
使用-s参数一次将JSON数据加入到数组(array)中,形成一个大的数组(array)。
3.1.5 不解析JSON数据
--raw-input/-R: 可以使用该参数以字符串形式显示,不解析JSON数据。如果如-s参数一起使用,则输出一行长的字符串。
测试如下:
$ cat test.json |jq -R
"{"
"\"name\":\"网站\","
"\"num\":3,"
"\"sites\":[\"Google\", \"Runoob\", \"Taobao\"]"
"}"
""
$ cat test.json |jq --raw-input
"{"
"\"name\":\"网站\","
"\"num\":3,"
"\"sites\":[\"Google\", \"Runoob\", \"Taobao\"]"
"}"
""
$可以看到,数据没有当作JSON字符解析。
与-s参数一起使用:
$ cat test.json |jq -sR
"{\n\"name\":\"网站\",\n\"num\":3,\n\"sites\":[\"Google\", \"Runoob\", \"Taobao\"]\n}\n\n"此时仅显示了一个单行的长字符串。
3.1.6 不解析任何输入流
--null-input/-n: 不解析任何输入流,用null作为输入,当将jq作为简单的计算器的时候,这比较有用。
我们测试一下:
$ cat test.json|jq -n
null
$ echo ''|jq -n
null
# 加法
$ echo ''|jq -n '2+3'
5
# 减法
$ echo ''|jq -n '2-3'
-1
# 乘法
$ echo ''|jq -n '2 * 3'
6
$ echo ''|jq --null-input '2 * 3'
6
# 除法
$ echo ''|jq -n '2 / 3'
0.6666666666666666
# 取模
$ echo ''|jq -n '4 % 4'
0
$ echo ''|jq -n '5 % 4'
1
$ echo ''|jq -n '6 % 4'
2可以看到,使用jq进行了简单的加减乘除运算,取模运算。
3.1.7 输出紧凑的数据
--compact-output/-c:默认情况下,JQ漂亮打印JSON输出。 使用此选项将导致更紧凑的输出,而是将每个JSON对象放在一行输出。
$ cat test.json |jq
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq -c
{"name":"网站","num":3,"sites":["Google","Runoob","Taobao"]}
$ cat test.json |jq --compact-output
{"name":"网站","num":3,"sites":["Google","Runoob","Taobao"]}
$可以看到,使用-c参数输出的数据更加紧凑。而默认情况下,输出的JSON数据会更加漂亮。
3.1.8 使用Tab作为缩进
--tab: 默认情况下,使用2个空格作为缩进,可以使用--tab参数使用Tab作为缩进。
$ cat test.json |jq --tab
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}说明:由于markdown显示的问题,上面控制台输出是异常的。
请看以下图片中的效果:

3.1.9 设置缩进的空格数
--indent n: 默认情况下,使用2个空格作为缩进,你可以通过使用本参数,设置n的值,以n个空格作为缩进。注意n不能超过7。
$ cat test.json |jq --indent 1
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 2
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 3
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 4
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 5
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 6
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 7
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent 8
jq: --indent takes a number between -1 and 7
Use jq --help for help with command-line options,
or see the jq manpage, or online docs at https://stedolan.github.io/jq
$ cat test.json |jq --indent 0
{"name":"网站","num":3,"sites":["Google","Runoob","Taobao"]}
$ cat test.json |jq --indent -1
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --indent -1|cat -A
{$
^I"name": "M-gM-=M-^QM-gM-+M-^Y",$
^I"num": 3,$
^I"sites": [$
^I^I"Google",$
^I^I"Runoob",$
^I^I"Taobao"$
^I]$
}$
$可以看到:
- 当设置
--indent 0时,与参数-c作用相当,按紧凑形式输出。 - 当设置
--indent -1时,与参数--tab作用相当,按Tab形式输出。 - 当设置
--indent 2时,与默认设置相同。
我们可以设置--indent 4缩进为4个空格,这种更漂亮美观。
3.1.10 颜色开关设置
--color-output/-Cand--monochrome-output/-M: 默认情况下,jq会输出彩色的JSON数据到终端,你可以使用-C参数来强制使用彩色输出,即使你使用了管道或者输出到文件。也可以使用-M参数来关掉彩色输出,这样就是单色输出了。
$ cat test.json |jq
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq -M
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq --monochrome-output
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}在控制台看不出效果,请看以下效果图:
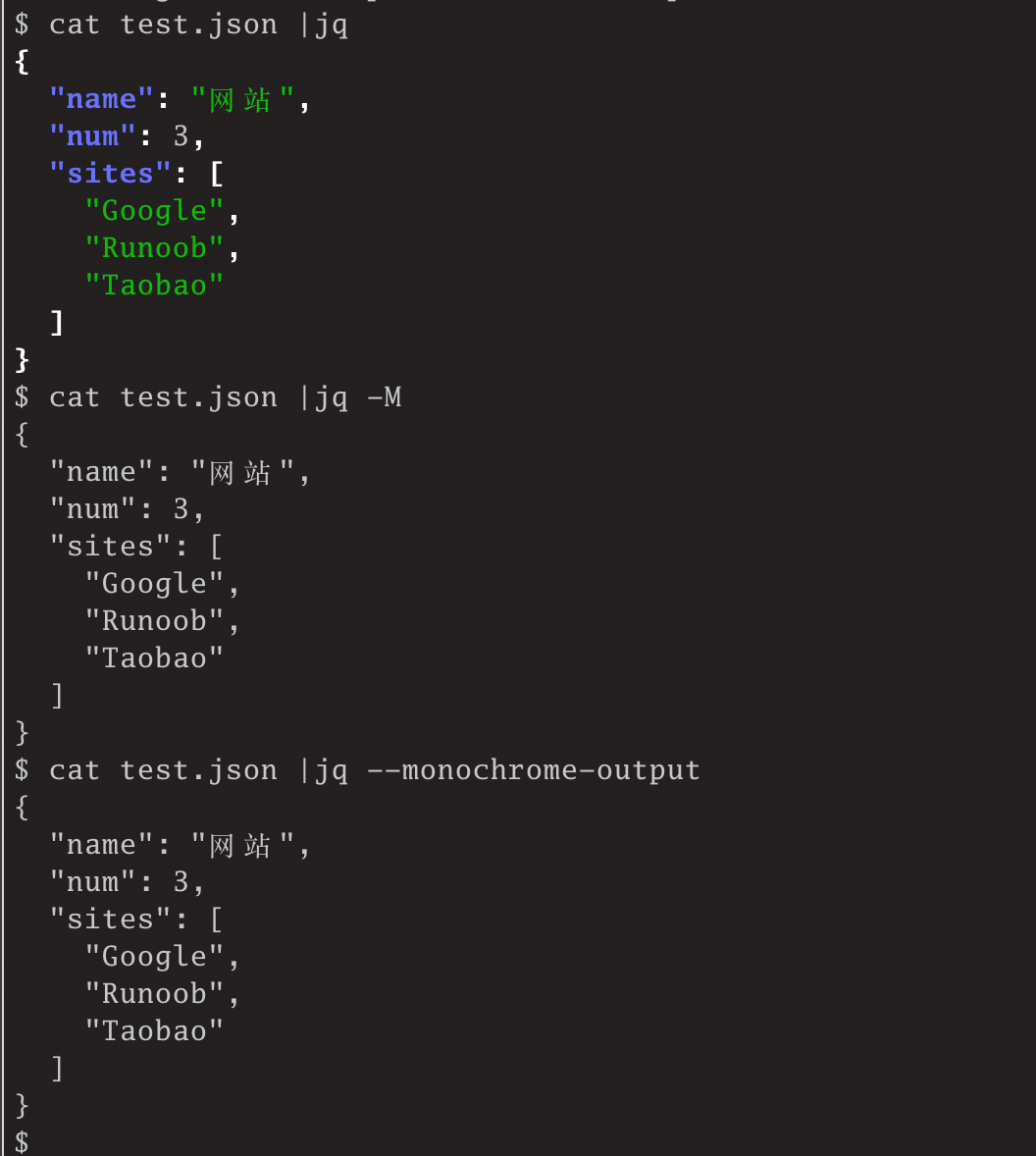
可以看到,使用-M参数已经关掉了彩色输出。
我们也可以使用-C参数,设置一直保持彩色输出。
$ cat test.json |jq
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
# 在jq输出后,再使用管道后,再次查看时没有彩色输出
$ cat test.json |jq|cat
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
# 在jq -C输出后,再使用管道后,再次查看时仍然有彩色输出
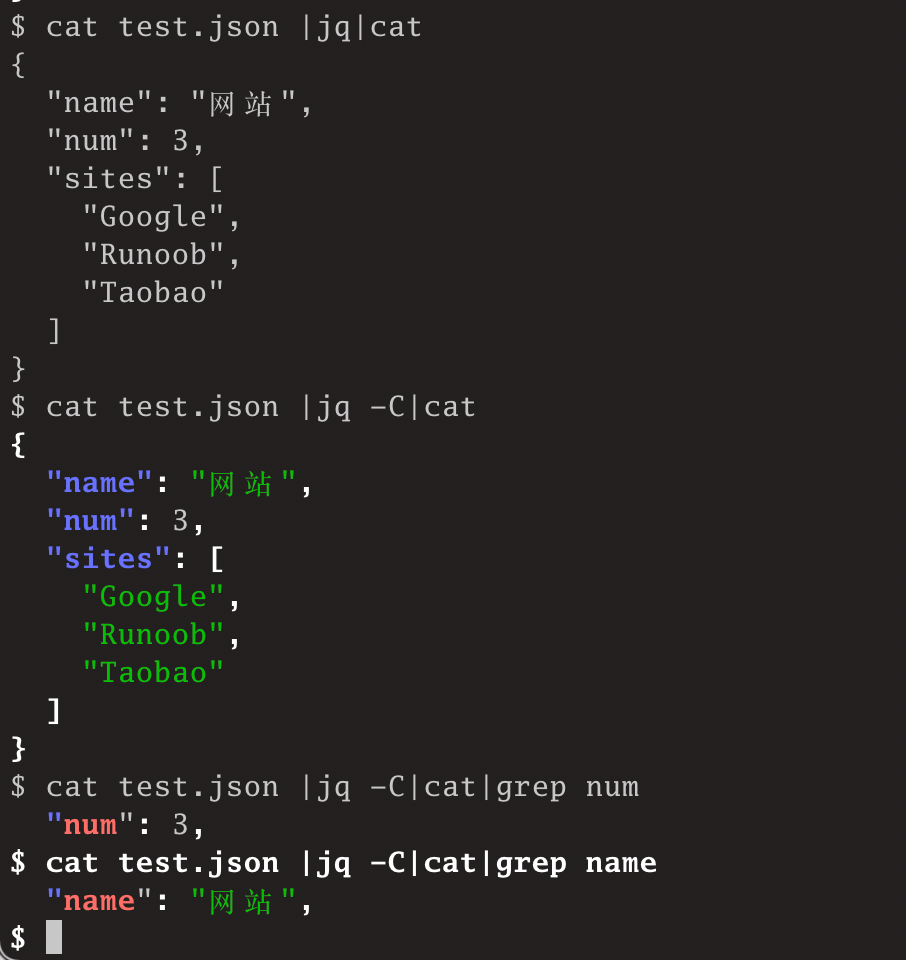
$ cat test.json |jq -C|cat
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq -C|cat|grep num
"num": 3,
$ cat test.json |jq -C|cat|grep name
"name": "网站",
$效果图如下:
同样,我们可以将彩色输出写入到文件中。
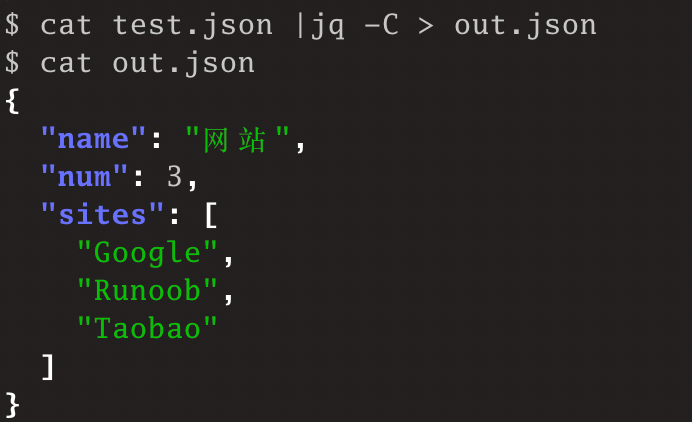
$ cat test.json |jq -C > out.json
$ cat out.json
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$此时,可以看到,直接查看out.json的内容时,就有彩色输出:
可以通过配置环境变量JQ_COLORS来改变默认的颜色输出。请参考后续章节。
3.1.11 以ASCII码输出数据
--ascii-output/-a: JQ通常将非ASCII编码的字符输出为UTF-8,即使输入作为转义序列指定的输入(如\u03bc)。 使用此选项,您可以强制JQ生成纯ASCII输出,每个非ASCII字符用等效的转义序列替换。
$ echo '"\u03bc"'|jq
"μ"
$ echo '"\u03bc"'|jq -a
"\u03bc"
$ echo '"\u03bc"'|jq --ascii-output
"\u03bc"
$ cat test.json |jq
{
"name": "网站",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$ cat test.json |jq -a
{
"name": "\u7f51\u7ad9",
"num": 3,
"sites": [
"Google",
"Runoob",
"Taobao"
]
}
$可以看到,像拉丁字母和中文都被转义成转义序列了。
3.1.12 对对象的键进行排序
--sort-keys/-S: 该参数可以对所有对象的字段(键)进行升序排序。
假设我们的data1.json内容如下:
[
{
"name": "网站",
"inum": 1,
"sites": [
"Google",
"Runoob",
"Taobao"
]
},
{
"tame": "网站",
"anum": 2,
"sites": [
"Google",
"Runoob",
"Taobao"
]
},
{
"name": "网站",
"nbum": 3,
"osites": [
"Google",
"Runoob",
"Taobao"
]
}
]现在我们对其输出时使用-S参数,注意是大写S。
$ cat test1.json |jq
[
{
"name": "网站",
"inum": 1,
"sites": [
"Google",
"Runoob",
"Taobao"
]
},
{
"tame": "网站",
"anum": 2,
"sites": [
"Google",
"Runoob",
"Taobao"
]
},
{
"name": "网站",
"nbum": 3,
"osites": [
"Google",
"Runoob",
"Taobao"
]
}
]默认情况下,并没有对字段进行排序,原样显示出来。
使用-S参数:
$ cat test1.json |jq -S
[
{
"inum": 1,
"name": "网站",
"sites": [
"Google",
"Runoob",
"Taobao"
]
},
{
"anum": 2,
"sites": [
"Google",
"Runoob",
"Taobao"
],
"tame": "网站"
},
{
"name": "网站",
"nbum": 3,
"osites": [
"Google",
"Runoob",
"Taobao"
]
}
]
$可以看到,每个对象中的字段名称已经排序了。
3.1.13 输出原始字符串而非JSON字符串
--raw-output/-r: 直接原样输出字符串而不是JSON数据。
$ echo '"non-JSON-based systems."'|jq
"non-JSON-based systems."
$ echo '"non-JSON-based systems."'|jq -r
non-JSON-based systems.
$ echo '"non-JSON-based systems."'|jq --raw-output
non-JSON-based systems.
$可以看到使用-r参数后,输出没有最外面的双引号。
另外,还有一个参数:
--join-output/-j: 与-r参数类似,但是不自动添加换行符。
$ echo '"non-JSON-based systems."'|jq -j
non-JSON-based systems.$
$
$ echo '"non-JSON-based systems."'|jq --join-output
non-JSON-based systems.$
$可以看到,输出non-JSON-based systems.信息后,控制台直接在后面输出了终端控制符$ 。
3.1.14 从文件中读取过滤器
jq支持类似awk -f命令一样的参数:
-f filename/--from-file filename
通过该参数,我们可以直接将过滤器写在文件中,然后进行过滤操作。
我们以2.1.5节的对所有元素进行过滤的示例,来进行说明。
获取所有的提交的提交消息和提交人信息。
$ cat data.json |jq '.[] | {message: .commit.message, name: .commit.committer.name}'
{
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"name": "William Langford"
}
{
"message": "Fix incorrect if empty string example",
"name": "William Langford"
}
{
"message": "update the version available through Chocolatey",
"name": "William Langford"
}我们将过滤器字符串.[] | {message: .commit.message, name: .commit.committer.name}写入到test.jq文件(注意,不要两侧的单引号)。
$ cat test.jq
# filter in the file
.[] | {message: .commit.message, name: .commit.committer.name}
$ cat data.json |jq -f test.jq
{
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"name": "William Langford"
}
{
"message": "Fix incorrect if empty string example",
"name": "William Langford"
}
{
"message": "update the version available through Chocolatey",
"name": "William Langford"
}
$ cat data.json |jq --from-file test.jq
{
"message": "Fix msys2 installation on AppVeyor\n\nRef: https://www.msys2.org/news/#2020-06-29-new-packagers",
"name": "William Langford"
}
{
"message": "Fix incorrect if empty string example",
"name": "William Langford"
}
{
"message": "update the version available through Chocolatey",
"name": "William Langford"
}可以看到,执行的结果与在命令行的输出是一致的。
这样,当学习了jq更复杂的语法后,可以在文件中写出更加复杂的过滤器。这个时候通过文件加载过滤器会更加方便。此处只是一个简单的示例。
3.1.15 向过滤中传递参数
3.1.15.1 向过滤中传递字符串参数
--arg name value:
This option passes a value to the jq program as a predefined variable. If you run jq with
--arg foo bar, then$foois available in the program and has the value"bar". Note thatvaluewill be treated as a string, so--arg foo 123will bind$footo"123".
该参数可以向jq程序中传递变量,注意,使用--arg foo 123传递的变量foo的值是字符串123,不是整数。
$ echo '[1,2,3]'|jq --arg tool "jq " '.[]*$tool'
"jq "
"jq jq "
"jq jq jq "
$可以看到,整数和字符串相乘,是将字符串进行重复拼接在一起。
$ echo '[1,2,3]'|jq --arg num "2" '.[]*$num'
"2"
"22"
"222"此时,可以看到num变量的值2是一个字符串,不是整型,使用乘法也是对字符串进行多次重复拼接的。
$ echo '["one", "two", "three"]'|jq --arg tool "jq" --arg num "1" '.[] + " " + $tool + " and " + $num + " string"'
"one jq and 1 string"
"two jq and 1 string"
"three jq and 1 string"
$此例中,可以看到,传递的参数tool和num都在过滤器中正常引用了,$tool引用tool变量,$num引用num变量,注意,变量名不需要使用{}包裹起来。
- 可以通过
$ARGS.named来获取命名参数对象。
$ echo '[1,2,3]'|jq --arg num "2" --arg flag "true" '$ARGS.named'
{
"num": "2",
"flag": "true"
}可以看到,我们提供的两个参数都包含在最终显示的对象中了。
也可以在命名参数对象中获取我们定义的参数:
$ echo '[1,2,3]'|jq --arg num "2" --arg flag "true" '$ARGS.named.flag + " " + $ARGS.named.num'
"true 2"或者直接获取:
$ echo '[1,2,3]'|jq --arg num "2" --arg flag "true" '$flag + " " + $num'
"true 2"获取的结果一样。
3.1.15.2 向过滤器传递JSON数据参数
上述使用--arg传输的参数都是字符串类型。如果我们需要传递JSON数据类型的参数到jq过滤器中,则需要使用以下的--argjson参数。
--argjson name JSON-text:
This option passes a JSON-encoded value to the jq program as a predefined variable. If you run jq with
--argjson foo 123, then$foois available in the program and has the value123.
注意,对于字符串参数和对象参数,必须要用单引号包裹起来,其他类型的参数可以包裹也可以不包裹。
# 查看命名参数对象中的内容
$ echo '[1,2,3]'|jq --argjson mystr '"string"' --argjson myobject '{"key":"value"}' --argjson myarray [1,2,3,4] --argjson mynum 2 --argjson mybool true --argjson mynull null '$ARGS.named'
{
"mystr": "string",
"myobject": {
"key": "value"
},
"myarray": [
1,
2,
3,
4
],
"mynum": 2,
"mybool": true,
"mynull": null
}
$
# 查看各传入参数的类型,此条命令不懂没关系,要以忽略,后面专门会讲内置方法type等
$ echo '[1,2,3]'|jq --argjson mystr '"string"' --argjson myobject '{"key":"value"}' --argjson myarray '[1,2,3,4]' --argjson mynum '2' --argjson mybool 'true' --argjson mynull null '$ARGS.named|.[]|type'
"string"
"object"
"array"
"number"
"boolean"
"null"3.1.15.3 通过文件向过滤器中传递参数
我们也可以通过在JSON文件中定义好数据,然后再传入到变量中。使用以下参数:
--slurpfile variable-name filename:
This option reads all the JSON texts in the named file and binds an array of the parsed JSON values to the given global variable. If you run jq with
--slurpfile foo bar, then$foois available in the program and has an array whose elements correspond to the texts in the file namedbar.
该参数会读取文件中的JSON文件,并解析JSON数据,然后放在一个array列表中,然后再绑定该列表到你定义的变量上。
现在假如我们有两个json文件,分别查看其内容:
$ cat arguments1.json
{
"mystr": "string",
"myobject": {
"key": "value"
},
"myarray": [
1,
2,
3,
4
],
"mynum": 2,
"mybool": true,
"mynull": null
}
$ cat arguments2.json
"tool"
$使用--slurpfile参数解析JSON文件数据作为变量内容。
# 从JSON文件中读取数据并解析到array列表中,然后绑定到参数中
$ echo 'null'|jq --slurpfile data1 arguments1.json --slurpfile data2 arguments2.json '$ARGS.named'
{
"data1": [
{
"mystr": "string",
"myobject": {
"key": "value"
},
"myarray": [
1,
2,
3,
4
],
"mynum": 2,
"mybool": true,
"mynull": null
}
],
"data2": [
"tool"
]
}
# 查看获取的两个参数的类型,可以看到,是array列表类型
$ echo 'null'|jq --slurpfile data1 arguments1.json --slurpfile data2 arguments2.json '$ARGS.named|.[]|type'
"array"
"array"
$
# 获取data1参数的值
$ echo 'null'|jq --slurpfile data1 arguments1.json --slurpfile data2 arguments2.json '$ARGS.named.data1'
[
{
"mystr": "string",
"myobject": {
"key": "value"
},
"myarray": [
1,
2,
3,
4
],
"mynum": 2,
"mybool": true,
"mynull": null
}
]
# 获取data2参数的值
$ echo 'null'|jq --slurpfile data1 arguments1.json --slurpfile data2 arguments2.json '$ARGS.named.data2'
[
"tool"
]
$也可以直接像下面这样获取变量的值:
$ echo 'null'|jq --slurpfile data1 arguments1.json --slurpfile data2 arguments2.json '$data1'
[
{
"mystr": "string",
"myobject": {
"key": "value"
},
"myarray": [
1,
2,
3,
4
],
"mynum": 2,
"mybool": true,
"mynull": null
}
]
$ echo 'null'|jq --slurpfile data1 arguments1.json --slurpfile data2 arguments2.json '$data2'
[
"tool"
]
$3.1.15.4 通过文件向过滤器中传递原始字符串参数
我们也可在一个普通文件定义好数据,然后再传入到变量中。使用以下参数:
--rawfile variable-name filename:
This option reads in the named file and binds its contents to the given global variable. If you run jq with
--rawfile foo bar, then$foois available in the program and has a string whose contents are to the texts in the file namedbar.
该参数会读取文件中的所有内容,然后直接当普通文本绑定到你定义的变量上。
请看下面示例。
# 复制文件
$ cp arguments1.json arguments1.txt
$ cp arguments2.json arguments2.txt
$ cat arguments2.txt
"tool"
# 查看命名参数对象中的值
$ echo 'null'|jq --rawfile data1 arguments1.txt --rawfile data2 arguments2.txt '$ARGS.named'
{
"data1": "{\n \"mystr\": \"string\",\n \"myobject\": {\n \"key\": \"value\"\n },\n \"myarray\": [\n 1,\n 2,\n 3,\n 4\n ],\n \"mynum\": 2,\n \"mybool\": true,\n \"mynull\": null\n}\n",
"data2": "\"tool\"\n"
}
# 查看data1参数的值
$ echo 'null'|jq --rawfile data1 arguments1.txt --rawfile data2 arguments2.txt '$data1'
"{\n \"mystr\": \"string\",\n \"myobject\": {\n \"key\": \"value\"\n },\n \"myarray\": [\n 1,\n 2,\n 3,\n 4\n ],\n \"mynum\": 2,\n \"mybool\": true,\n \"mynull\": null\n}\n"
# 查看data2参数的值
$ echo 'null'|jq --rawfile data1 arguments1.txt --rawfile data2 arguments2.txt '$data2'
"\"tool\"\n"
$3.1.15.5 向过滤器中传递字符串位置参数
我们也可以将位置参数传递到过滤器中。使用以下参数:
--args:
Remaining arguments are positional string arguments. These are available to the jq program as
$ARGS.positional[].
剩下的参数是位置参数,可以使用$ARGS.positional[]获取位置参数。
可以像下面这样使用:
$ echo 'null'|jq '$ARGS' --arg tool "jq" --args '"positional argument one"' "positional argument two"
{
"positional": [
"\"positional argument one\"",
"positional argument two"
],
"named": {
"tool": "jq"
}
}
$ echo 'null'|jq '$ARGS.positional[]' --arg tool "jq" --args '"positional argument one"' "positional argument two"
"\"positional argument one\""
"positional argument two"
$可以看到:
- 使用位置参数时,默认不需要使用单引号将需要传递的参数包裹起来。使用单引号包裹时,
'"positional argument one"',会将包裹字符的双引号也作为位置参数的一部分输出。
另外,位置参数必须放在命令的最后的位置,否则会仅输出第一个位置参数。这个是经过多次试验才发现的,请看下面的示例:
$ echo 'null'|jq --arg tool "jq" --args '"positional argument one"' "positional argument two" '$ARGS.positional[]'
"positional argument one"
$ echo 'null'|jq --arg tool "jq" --args '"positional argument one"' "positional argument two" '$ARGS.positional'
"positional argument one"
$ echo 'null'|jq --arg tool "jq" --args '"positional argument one"' "positional argument two" '$ARGS'
"positional argument one"
$ echo 'null'|jq --arg tool "jq" --args '"positional argument one"' "positional argument two" '$'
"positional argument one"
$ echo 'null'|jq --arg tool "jq" --args '"positional argument one"' "positional argument two" ''
"positional argument one"
$ echo 'null'|jq --arg tool "jq" --args '"positional argument one"' "positional argument two"
"positional argument one"
$示例中,我将过滤器放在了位置参数后面,这个时候,无论我怎么修改后面的过滤器字符,如最开始的 '$ARGS.positional[]',到最后直接没有过滤器,jq输出的结果一直都是第一个位置参数"positional argument one"。
上面的将过滤器放在位置参数后面,实质是jq执行的是以下命令:
$ echo 'null'|jq '"positional argument one"'
"positional argument one"如果将'"positional argument one"'两侧的单引号去掉,再执行则会抛出异常:
$ echo 'null'|jq --arg tool "jq" --args "positional argument one" '"positional argument two"'
jq: error: syntax error, unexpected IDENT, expecting $end (Unix shell quoting issues?) at <top-level>, line 1:
positional argument one
jq: 1 compile error
$ echo $?
3
$可以看到异常退出,退出码是3。与执行下面的命令的异常是一样的:
$ echo 'null'|jq "positional argument one"
jq: error: syntax error, unexpected IDENT, expecting $end (Unix shell quoting issues?) at <top-level>, line 1:
positional argument one
jq: 1 compile error
$ echo $?
3结合上面的执行结果可以知道,有以下结论:
- 位置参数应放在命令行参数的最后的位置。
- 位置参数的字符串默认不需要使用单引号包裹。
3.1.15.6 向过滤器中传递JSON位置参数
我们也可以将位置参数传递到过滤器中。使用以下参数:
--jsonargs:
Remaining arguments are positional JSON text arguments. These are available to the jq program as
$ARGS.positional[].
剩下的参数是JSON位置参数,可以使用$ARGS.positional[]获取位置参数。
有了上一节的测试,此处就知道直接将JSON型的位置参数放置在命令行的最后面,直接看下面的示例:
# 同时传递命名参数、字符串型位置参数、JSON型的位置参数到过滤器中
# 通过'$ARGS'可以打印所有的位置参数和命名参数
$ echo 'null'|jq '$ARGS' --arg tool "jq" --args '"positional argument one"' "positional argument two" --jsonargs true false '{"key":"value"}' null 2 '"string"'
{
"positional": [
"\"positional argument one\"",
"positional argument two",
true,
false,
{
"key": "value"
},
null,
2,
"string"
],
"named": {
"tool": "jq"
}
}
# 获取位置参数列表
$ echo 'null'|jq '$ARGS.positional[]' --arg tool "jq" --args '"positional argument one"' "positional argument two" --jsonargs true false '{"key":"value"}' null 2 '"string"'
"\"positional argument one\""
"positional argument two"
true
false
{
"key": "value"
}
null
2
"string"
# 查看位置参数的各元素的数据类型
$ echo 'null'|jq '$ARGS.positional[]|type' --arg tool "jq" --args '"positional argument one"' "positional argument two" --jsonargs true false '{"key":"value"}' null 2 '"string"'
"string"
"string"
"boolean"
"boolean"
"object"
"null"
"number"
"string"
$3.1.16 运行测试用例
最后一个参数。
--run-tests [filename]:
Runs the tests in the given file or standard input. This must be the last option given and does not honor all preceding options. The input consists of comment lines, empty lines, and program lines followed by one input line, as many lines of output as are expected (one per output), and a terminating empty line. Compilation failure tests start with a line containing only "%%FAIL", then a line containing the program to compile, then a line containing an error message to compare to the actual.
Be warned that this option can change backwards-incompatibly.
在给定的文件或标准输入中运行测试,该参数是命令行最后一个参数。将会忽略前面的命令行参数选项。
测试文件的写法是这样的:
- 可以包含备注行,空行、程序行、输入行、输出行、终止的空行等。
你可以使用git clone https://github.com/stedolan/jq.git或git clone git@github.com:stedolan/jq.git下载jq的源码到本地,我这边已经下载好了。
[mzh@MacBookPro jq (master)]$ git remote -v
origin git@github.com:meizhaohui/jq.git (fetch)
origin git@github.com:meizhaohui/jq.git (push)
[mzh@MacBookPro jq (master)]$ ls
AUTHORS Dockerfile NEWS appveyor.yml config jq.1.prebuilt m4 sig
COPYING KEYS README build configure.ac jq.spec modules src
ChangeLog Makefile.am README.md compile-ios.sh docs libjq.pc.in scripts tests
[mzh@MacBookPro jq (master)]$ ls tests/*.test
tests/base64.test tests/jq.test tests/man.test tests/onig.test tests/optional.test可以看到在tests目录下面有几个以.test结尾的文件。这几个就是测试用例文件。
我们来看一下tests/jq.test文件,文件内容比较长,我们只看前100行:
[mzh@MacBookPro jq (master)]$ head -n 100 tests/jq.test
# Tests are groups of three lines: program, input, expected output
# Blank lines and lines starting with # are ignored
#
# Simple value tests to check parser. Input is irrelevant
#
true
null
true
false
null
false
null
42
null
1
null
1
-1
null
-1
# FIXME: much more number testing needed
{}
null
{}
[]
null
[]
{x: -1}
null
{"x": -1}
# The input line starts with a 0xFEFF (byte order mark) codepoint
# No, there is no reason to have a byte order mark in UTF8 text.
# But apparently people do, so jq shouldn't break on it.
.
"byte order mark"
"byte order mark"
# We test escapes by matching them against Unicode codepoints
# FIXME: more tests needed for weird unicode stuff (e.g. utf16 pairs)
"Aa\r\n\t\b\f\u03bc"
null
"Aa\u000d\u000a\u0009\u0008\u000c\u03bc"
.
"Aa\r\n\t\b\f\u03bc"
"Aa\u000d\u000a\u0009\u0008\u000c\u03bc"
"inter\("pol" + "ation")"
null
"interpolation"
@text,@json,([1,.] | (@csv, @tsv)),@html,@uri,@sh,@base64,(@base64 | @base64d)
"<>&'\"\t"
"<>&'\"\t"
"\"<>&'\\\"\\t\""
"1,\"<>&'\"\"\t\""
"1\t<>&'\"\\t"
"<>&'"\t"
"%3C%3E%26'%22%09"
"'<>&'\\''\"\t'"
"PD4mJyIJ"
"<>&'\"\t"
# regression test for #436
@base64
"foóbar\n"
"Zm/Ds2Jhcgo="
@base64d
"Zm/Ds2Jhcgo="
"foóbar\n"
@uri
"\u03bc"
"%CE%BC"
@html "<b>\(.)</b>"
"<script>hax</script>"
"<b><script>hax</script></b>"
[.[]|tojson|fromjson]
["foo", 1, ["a", 1, "b", 2, {"foo":"bar"}]]
["foo",1,["a",1,"b",2,{"foo":"bar"}]]
#
# Dictionary construction syntax
#
[mzh@MacBookPro jq (master)]$我们直接将这100行保存到一个新的文件中去。
[mzh@MacBookPro jq (master)]$ head -n 100 tests/jq.test > myjq.test然后我们执行命令:
[mzh@MacBookPro jq (master ✗)]$ echo 'null'|jq '$ARGS.named' --arg tool "jq"
{
"tool": "jq"
}
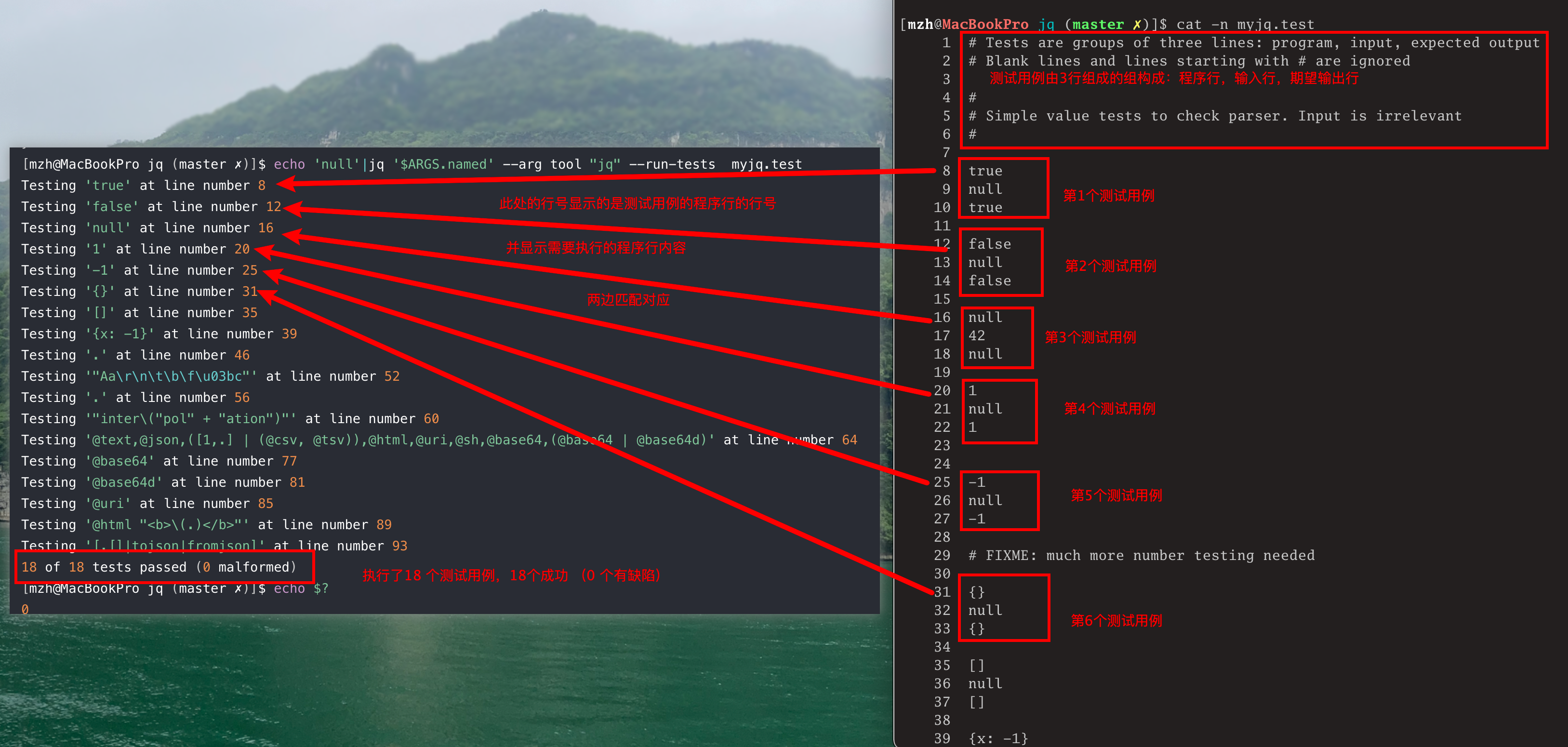
[mzh@MacBookPro jq (master ✗)]$ echo 'null'|jq '$ARGS.named' --arg tool "jq" --run-tests myjq.test
Testing 'true' at line number 8
Testing 'false' at line number 12
Testing 'null' at line number 16
Testing '1' at line number 20
Testing '-1' at line number 25
Testing '{}' at line number 31
Testing '[]' at line number 35
Testing '{x: -1}' at line number 39
Testing '.' at line number 46
Testing '"Aa\r\n\t\b\f\u03bc"' at line number 52
Testing '.' at line number 56
Testing '"inter\("pol" + "ation")"' at line number 60
Testing '@text,@json,([1,.] | (@csv, @tsv)),@html,@uri,@sh,@base64,(@base64 | @base64d)' at line number 64
Testing '@base64' at line number 77
Testing '@base64d' at line number 81
Testing '@uri' at line number 85
Testing '@html "<b>\(.)</b>"' at line number 89
Testing '[.[]|tojson|fromjson]' at line number 93
18 of 18 tests passed (0 malformed)
[mzh@MacBookPro jq (master ✗)]$ echo $?
0
[mzh@MacBookPro jq (master ✗)]$可以看到,jq直接忽略了--run-tests参数前的 '$ARGS.named' --arg tool "jq",只运行了测试用例。
我们来对比一下测试文件和输出结果,说明详见下图:
`
至此,我们已经实验完成所有的参数了!
可以看到,jq非常的强大,连参数都有这么多知识!加油!!
4. 基本过滤器
重要说明
对于官网中的array数据类型,可以译为数组或列表,本总结中两种都是指array!
4.1 身份运算符.
Identity:
.The absolute simplest filter is
.. This is a filter that takes its input and produces it unchanged as output. That is, this is the identity operator.Since jq by default pretty-prints all output, this trivial program can be a useful way of formatting JSON output from, say,
curl.
身份运算符是最简单的过滤器。
身份运算符会将输入流直接输出。由于
jq默认会美化JSON字符的输出,因此,身份运算符默认会将输入流美化后然后输出。在处理十进制数时,可以无损转换。
jq默认不会截断字面数字,除非要进行算术运算。jq尽量会保持数字的原始精度。
国内访问jq的官方时,查看示例时,经常点击Examples没有反应,不显示给出的示例。这个时候最好使用科学上网(翻墙),然后再查看示例。
使用科学上网看到的示例:
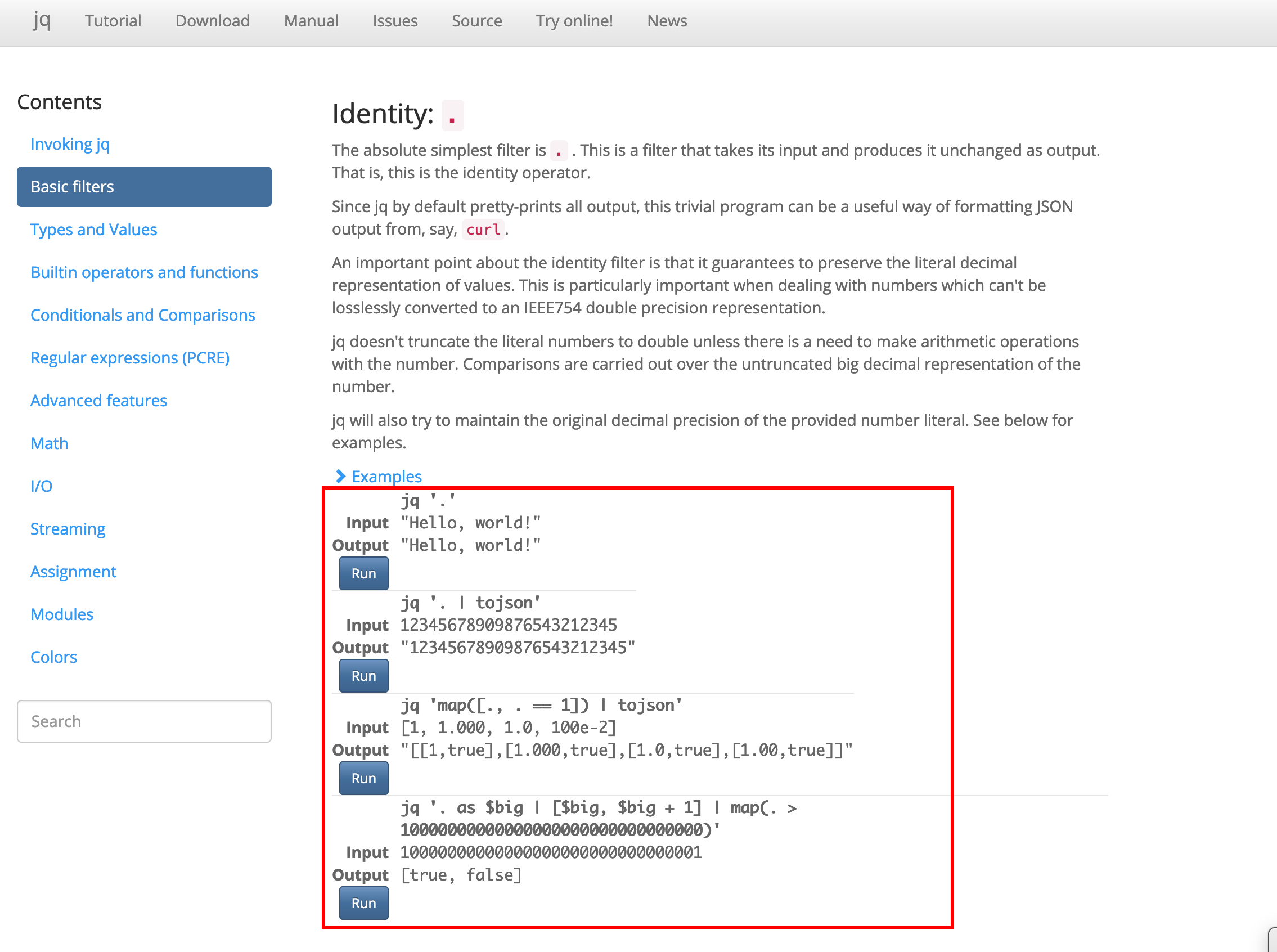
你可以点击Run按钮跳转到jq play页面 https://jqplay.org/jq?q=.&j=%22Hello%2C%20world!%22:
当你没有安装jq程序的时候,可以在这个网站上面进行一些测试。
我们就在本地按示例进行测试。
$ echo '"Hello, world!"'|jq '.'
"Hello, world!"
$ echo '12345678909876543212345'|jq '.|tojson'
"12345678909876543000000"
$ echo [1, 1.000, 1.0, 100e-2]|jq 'map([., . == 1]) | tojson'
"[[1,true],[1,true],[1,true],[1,true]]"
$ echo '10000000000000000000000000000001'|jq '. as $big | [$big, $big + 1] | map(. > 10000000000000000000000000000000)'
[
false,
false
]
$可以看到,我们执行的结果与官方给出的示例的结果存在一些差异。
测试16位数:
# 异常
$ echo '9999999999999999'|jq '.|tojson'
"1e+16"
$ echo '9999999999999998'|jq '.|tojson'
"9999999999999998"
# 异常
$ echo '9999999999999997'|jq '.|tojson'
"9999999999999996"
# 异常
$ echo '9999999999999995'|jq '.|tojson'
"9999999999999996"
$ echo '9999999999999996'|jq '.|tojson'
"9999999999999996"
$ echo '9999999999999994'|jq '.|tojson'
"9999999999999994"
# 异常
$ echo '9999999999999993'|jq '.|tojson'
"9999999999999992"
# 异常
$ echo '9999999999999991'|jq '.|tojson'
"9999999999999992"
$ echo '9999999999999992'|jq '.|tojson'
"9999999999999992"
$ echo '9999999999999990'|jq '.|tojson'
"9999999999999990"可以发现16位数字中,输出也存在异常。
测试15位数:
$ echo '999999999999999'|jq '.|tojson'
"999999999999999"
$ echo '999999999999998'|jq '.|tojson'
"999999999999998"
$ echo '999999999999997'|jq '.|tojson'
"999999999999997"
$ echo '999999999999996'|jq '.|tojson'
"999999999999996"
$ echo '999999999999995'|jq '.|tojson'
"999999999999995"
$ echo '999999999999994'|jq '.|tojson'
"999999999999994"
$ echo '999999999999993'|jq '.|tojson'
"999999999999993"
$ echo '999999999999992'|jq '.|tojson'
"999999999999992"
$ echo '999999999999991'|jq '.|tojson'
"999999999999991"
$ echo '999999999999990'|jq '.|tojson'
"999999999999990"发现全部正常输出。
999 9999 9999 9999是一个非常大的数字,一般够我们使用了。
4.2 对象标识符-索引.foo、.foo.bar
- 最简单的有用过滤器是
.foo,当输入值是JSON对象时,它会生成键对应的值,如果该键不存在,则返回null。 .foo.bar的过滤器与.foo|.bar等效。- 此语法仅适用于简单的类似标识符的键,即全部由字母数字字符和下划线组成且不以数字开头的键。
- 如果键包含特殊字符或以数字开头,则需要用双引号将其括起来,如下所示:
."foo$",否则为.["foo$"]。 - 例如
.["foo::bar"]和.["foo.bar"]能工作,然而.foo::bar不能工作, 并且.foo.bar等价.["foo"].["bar"]。
$ echo '{"foo": 42, "bar": "less interesting data"}'|jq '.foo'
42
$ echo '{"notfoo": true, "alsonotfoo": false}'|jq '.["foo"]'
null
$ echo '{"foo": 42, "bar": "less interesting data"}'|jq '.["foo"]'
42下面我们来测试一些特殊的字符,如包含点号的键、以数字开头的键、包含其他特殊字符的键。
4.2.1 包含点号的键
父键和子键中都包含了.点号,如父键名是parent.key,而子键名是sub.key,我们来看一下下面的解析:
# 直接解析`.parent.key`,没有获取到正确的值,返回的是null
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '.parent.key'
null
# 将键名使用双引号包裹起来,能正常获取到父键"parent.key"对应的值
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '."parent.key"'
{
"sub.key": "value"
}
# 也可以这样,在用双引号包裹父键后,再用中括号包裹起来,感觉多此一举
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '.["parent.key"]'
{
"sub.key": "value"
}如果我们同时要获取到子键对应的值,可以像下面这样操作:
# 连接两次将键名用双引号包裹起来。用双引号包裹父键`parent.key`,同时用双引号包裹父键`sub.key`,可以获取到最后的`value`
# 推荐使用此种方法!!!!
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '."parent.key"."sub.key"'
"value"
# 也可以将父键用中括号括起来
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '.["parent.key"]."sub.key"'
"value"
# 若我们把子键也用中括号括起来,抛出异常
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '.["parent.key"].["sub.key"]'
jq: error: syntax error, unexpected '[', expecting FORMAT or QQSTRING_START (Unix shell quoting issues?) at <top-level>, line 1:
.["parent.key"].["sub.key"]
jq: 1 compile error
# 若我们仅只把子键用中括号括起来,一样也抛出异常
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '."parent.key".["sub.key"]'
jq: error: syntax error, unexpected '[', expecting FORMAT or QQSTRING_START (Unix shell quoting issues?) at <top-level>, line 1:
."parent.key".["sub.key"]
jq: 1 compile error
$
# 若子键也要使用中括号括起来,那应在中间加一上管道符|
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '."parent.key" | .["sub.key"]'
"value"
$ echo '{"parent.key": {"sub.key": "value"}}'|jq '.["parent.key"] | .["sub.key"]'
"value"
$因此,如果我们在键名中包含点号,建议使用双引号包裹键名的方式来过滤!!!
4.2.2 包含双引号的键
假如我们父键和子键中都包含双引号",这时候该怎么处理。
$ echo '{"parent\"key": {"sub\"key": "value"}}'|jq '."parent\"key"."sub\"key"'
"value"当我们键名中包含双引号时,应使用\"进行转义!!再过滤器中也使用\"进行转义!!才能正常获取到值。
4.2.3 包含其他特殊字符的键
假如我们父键和子键中都包含两个冒号::,这时候该怎么处理。
$ echo '{"parent::key": {"sub::key": "value"}}'|jq '."parent::key" ."sub::key"'
"value"
$ echo '{"parent::key": {"sub::key": "value"}}'|jq '."parent::key" ."sub::key"'
"value"
$ echo '{"parent::key": {"sub::key": "value"}}'|jq '."parent::key" . "sub::key"'
"value"此时,我们只用将键名用双引号包裹起来就可以,不用转义。注意,此处,我们在父键和子键之间加了几个空格,你可以随意加多个空格,用于区分开不同的键。
4.2.4 数字处于键的开始位置
假如我们父键和子键键名开头都是数字,这时候该怎么处理。
$ echo '{"1parentkey": {"2subkey": "value"}}'|jq '."1parentkey" ."2subkey"'
"value"
# 如果不加双引号,则会抛出异常
$ echo '{"1parentkey": {"2subkey": "value"}}'|jq '.1parentkey.2subkey'
jq: error: syntax error, unexpected IDENT, expecting $end (Unix shell quoting issues?) at <top-level>, line 1:
.1parentkey.2subkey
jq: 1 compile error此时,我们只用将键名用双引号包裹起来就可以,不用转义。
4.2.5 可选的对象标识符.foo?
.foo?类似.foo标识符,但当.不是array列表或object对象时,不抛出异常。
与.foo标识符相似的行为:
$ echo '{"foo": 42, "bar": "less interesting data"}'|jq '.foo?'
42
$ echo '{"foo": 42, "bar": "less interesting data"}'|jq '.["foo"]?'
42
$ echo '{"notfoo": true, "alsonotfoo": false}'|jq '.foo?'
null不同的行为:
# 输入是字符串时,不带?时抛出异常,退出码是5
$ echo '"not array"'|jq '.foo'
jq: error (at <stdin>:1): Cannot index string with string "foo"
$ echo $?
5
# 输入是字符串时,带?时正常退出,退出码是0
$ echo '"not array"'|jq '.foo?'
$ echo $?
0
# 输入是列表时,不带?时抛出异常,退出码是5
$ echo '[1,2]'|jq '.foo'
jq: error (at <stdin>:1): Cannot index array with string "foo"
$ echo $?
5
# 输入是列表时,带?时正常退出,退出码是0
$ echo '[1,2]'|jq '.foo?'
$ echo $?
0
# 输入是列表时,不带?时抛出异常
$ echo '[1,2]'|jq '[.foo]'
jq: error (at <stdin>:1): Cannot index array with string "foo"
# 输入是列表时,带?时正常退出,由于我们在`.foo?`两侧加了中括号,最后输出的是`[]`,一个空列表
$ echo '[1,2]'|jq '[.foo?]'
[]上面的异常时,抛出的提示是Cannot index array with string,即不能用字符串索引数组(列表)!
下面我们来看一下列表索引。
4.3.6 对象索引
- 你可以通过
.["string"]的方式来获取对象索引的元素,如.["foo"],.foo是一个简写。
$ echo '{"name":"JSON", "good":true}'|jq '.["name"]'
"JSON"
$ echo '{"name":"JSON", "good":true}'|jq '.name'
"JSON"4.3 列表索引.[2]
- 当索引值是整数时,
.[<value>]能够对数组(列表)进行索引。 - 列表索引默认从
0开始。.[2]是返回的是第3个元素。 - 支持负数索引,
-1表示最后一个元素,-2表示倒数第二个元素。
# 获取列表第1个元素
$ echo '[{"name":"JSON", "good":true}, {"name":"XML", "good":false}]'|jq '.[0]'
{
"name": "JSON",
"good": true
}
# 获取列表第2个元素
$ echo '[{"name":"JSON", "good":true}, {"name":"XML", "good":false}]'|jq '.[1]'
{
"name": "XML",
"good": false
}
# 获取列表第3个元素,超过索引最大值,返回null
$ echo '[{"name":"JSON", "good":true}, {"name":"XML", "good":false}]'|jq '.[2]'
null
# 获取列表倒数第1个元素
$ echo '[1,2,3,4,5]'|jq '.[-1]'
5
# 获取列表倒数第2个元素
$ echo '[1,2,3,4,5]'|jq '.[-2]'
4
# 获取列表倒数第3个元素
$ echo '[1,2,3,4,5]'|jq '.[-3]'
3
# 获取列表第1个元素
$ echo '[1,2,3,4,5]'|jq '.[0]'
1
# 获取列表第2个元素
$ echo '[1,2,3,4,5]'|jq '.[1]'
2
# 获取列表第3个元素
$ echo '[1,2,3,4,5]'|jq '.[2]'
3
# 获取列表第5个元素
$ echo '[1,2,3,4,5]'|jq '.[4]'
5
# 获取列表第6个元素,超出索引最大值,返回null
$ echo '[1,2,3,4,5]'|jq '.[5]'
null
$4.4 列表/字符串切片
可以使用类似Python中的切换操作对列表或字符串进行切片处理。如.[10:15]可以返回一个子列表或子字符串。切片输出包含起点元素,不包含终点元素,可以使用负数表示索引号。
$ echo '["a","b","c","d","e"]'|jq '.[2:4]'
[
"c",
"d"
]
$ echo '"abcdefghi"'|jq '.[2:4]'
"cd"
$ echo '["a","b","c","d","e"]'|jq '.[:3]'
[
"a",
"b",
"c"
]
$ echo '["a","b","c","d","e"]'|jq '.[-2:]'
[
"d",
"e"
]
$4.5 列表/对象迭代器
- 当你在使用
.[index]时,如果省略index索引,那么jq将返回数据的所有元素。 - 当你使用
.[]作用在[1,2,3]输入时,将会产生三个独立的数字,而不是一个列表。 - 使用
.[]?作用类似.[],但当输入不是数组或对象时,不输出异常。
# 直接使用身份运算符,输出是数组本身
$ echo '[1,2,3]'|jq '.'
[
1,
2,
3
]
# 使用.[],将会迭代数组中所有元素
$ echo '[1,2,3]'|jq '.[]'
1
2
3
# 使用`.[]`作用于对象组成的数组时,将会输出每一个对象元素
$ echo '[{"name":"JSON", "good":true}, {"name":"XML", "good":false}]'|jq '.[]'
{
"name": "JSON",
"good": true
}
{
"name": "XML",
"good": false
}
# 使用`.[]`作用于空数组时,返回为空
$ echo '[]'|jq '.[]'
# 使用`.[]`作用于对象时,返回对象键的值
$ echo '{"a":1, "b":1}'|jq '.[]'
1
1
# 使用`.[]`作用于对象时,返回对象键的值
$ echo '{"a":1, "b":2}'|jq '.[]'
1
2.[]与.[]?的差异:
$ echo '"a"'|jq '.[]'
jq: error (at <stdin>:1): Cannot iterate over string ("a")
$ echo $?
5
$ echo '"a"'|jq '.[]?'
$ echo $?
04.6 逗号
- 如果两个过滤器用逗号(Comma
,)分隔,那么相同的输入将被送入两个过滤器,两个过滤器的输出值流将按顺序连接:首先是左表达式产生的所有输出,然后是右边表达式产生的所有输出。 例如,过滤器.foo, .bar将“foo”字段和“bar”字段作为单独的输出组合在一起。
# 使用逗号连接的过滤器会分别作用于输入流,然后顺序输出结果
# 可以看到依次获取到对象中键foo的值42,以及键bar的值something else
$ echo '{"foo": 42, "bar": "something else", "baz": true}'|jq '.foo, .bar'
42
"something else"
# 我们也可以使用逗号,连接多个过滤器,每个过滤器都会作用于输入流,然后顺序输出结果
$ echo '{"foo": 42, "bar": "something else", "baz": true}'|jq '.foo, .bar, .baz'
42
"something else"
true
# 在使用逗号连接过滤器时,每个过滤器可以分别进行一系列操作后,再进行连接
$ echo '{"user":"stedolan", "projects": ["jq", "wikiflow"]}'|jq '.user, .projects[]'
"stedolan"
"jq"
"wikiflow"
# 也可以连接两个不同的索引,注意与列表索引切片是不一样的
$ echo '["a","b","c","d","e"]'|jq '.[4,2]'
"e"
"c"与列表切片的差异:
# 列表切片返回的是列表,元素包含起始元素,但不包含终点索引的元素
$ echo '["a","b","c","d","e"]'|jq '.[1:4]'
[
"b",
"c",
"d"
]
# 使用逗号连接的两个索引,只是输出该索引对应的元素本身,并不会形成新的列表
$ echo '["a","b","c","d","e"]'|jq '.[1,4]'
"b"
"e"4.7 管道|
- 管道
|类似于Linux中的|,将左侧的输出流作为右侧的输入流进行处理。 - 如果左侧产生多个结果,那么右侧的的过滤器将会针对所有的结果运行一次。因此
.[]|.foo将会检查输入数组中的每个元素的foo字段。 .a.b.c与.a|.b|.c等价。.会表示管道前一个输出流产生的所有结果。
# 使用管道后,将输出数组每一个元素的name键对应的值
$ echo '[{"name":"JSON", "good":true}, {"name":"XML", "good":false}]'| jq '.[].name'
"JSON"
"XML"
# 使用管道后,将输出数组每一个元素的good键对应的值
$ echo '[{"name":"JSON", "good":true}, {"name":"XML", "good":false}]'| jq '.[].good'
true
false4.8 小括号
- Parenthesis括号就像在任何典型的编程语言中一样用作分组运算符。
# 使用小括号计算前面的加法运算,然后将结果乘以5
$ echo '1'|jq '( . + 2) * 5'
15
# 使用小括号计算前面的字符串拼接,然后进行多次重复拼接
$ echo '"ab"'|jq '( . + "cd") * 5'
"abcdabcdabcdabcdabcd"5. 数据类型和值
- jq 支持与 JSON 相同的一组数据类型 - 数字、字符串、布尔值、数组、对象(在 JSON 中是只有字符串键的哈希)和
null空。 - 布尔值、空值、字符串和数字的编写方式与 JavaScript 相同。
- jq 中的数字在内部由它们的 IEEE754 双精度近似表示。 任何对数字的算术运算,无论是文字还是先前过滤器的结果,都将产生双精度浮点结果。
- 在解析文字时 jq 将存储原始文字字符串。 如果没有对这个值应用任何改变,那么它将以其原始形式输出到输出。但是进行转换时将会导致数据失真。
疑问: IEEE754 双精度是怎么表示的?
5.1 数组
- 数组由
[]包裹。如[1,2,3]。 - 数组的表达式可以是任意的jq表达式,包括管道符
|。 - 可以使用
[]将jq输出流的结果转换成一个数组。 - 表达式
[1,2,3]不是使用逗号分隔数组的内置语法,而是用[]应用到1,2,3而收集的结果。
$ echo '{"user":"stedolan", "projects": ["jq", "wikiflow"]}'|jq '[.user, .projects[]]'
[
"stedolan",
"jq",
"wikiflow"
]
$ echo '[1,2,3]'|jq '[ .[] | . * 2]'
[
2,
4,
6
]5.2 对象
- 使用
{}来构建对象。如{"a": 42, "b": 17}。 - 如果键是类似标识符的,那么可以进行简写,省略掉双引号,如
{a: 42, b: 17}。 - 如果键是由表达式组成,则应用括号包裹起来,如
{("a"+"b"): 59}。 - 键的值可以是任意值。
- 如果输入对象中包含 "user", "title", "id", "content"等字段,你想访问"user"和"title"字段,那么你可以这样
{user: .user, title: .title}。由于这种很常用,可以简写成{user, title}。 - 如果一个表达式产生多个输出结果,输出会产生多个对象。
- 如果使用表达式作为键,则应使用小括号包裹起来。
# 获取键a的值
$ echo '{"a": 42, "b": 17}'|jq '.a'
42
# 获取键a的值,并作为对象中键“a”的值
$ echo '{"a": 42, "b": 17}'|jq '{"a":.a}'
{
"a": 42
}
# 由于"a"和"b"都是标识符,键外侧的双引号可以省略
$ echo '{"a": 42, "b": 17}'|jq '{a: .a, b: .b}'
{
"a": 42,
"b": 17
}
# 使用简写形式,直接获取到键a和键b的值
$ echo '{"a": 42, "b": 17}'|jq '{a, b}'
{
"a": 42,
"b": 17
}同样,使用简写形式获取键的值:
$ echo '{"user":"stedolan","title": "More JQ"}'|jq '{user: .user, title: .title}'
{
"user": "stedolan",
"title": "More JQ"
}
$ echo '{"user":"stedolan","title": "More JQ"}'|jq '{user, title}'
{
"user": "stedolan",
"title": "More JQ"
}产生多个对象的情况:
# 获取titles键的每个元素
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '.titles[]'
"JQ Primer"
"More JQ"
# 由于.titles[]产生2个输出,每个输出都需要与`user`的输出组成一个子对象,这样最终也产生了2个对象输出
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '{user, title: .titles[]}'
{
"user": "stedolan",
"title": "JQ Primer"
}
{
"user": "stedolan",
"title": "More JQ"
}键是表达式的情况:
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '{(.user): .titles}'
{
"stedolan": [
"JQ Primer",
"More JQ"
]
}5.3 递归下降
- 使用
..符号可以递归产生每个值。 - 请注意
..a不起作用,而应使用..|.a。
可以看一下下面简单的示例:
$ echo '[[{"a":1}]]'|jq '..'
[
[
{
"a": 1
}
]
]
[
{
"a": 1
}
]
{
"a": 1
}
1
$ echo '[[{"a":1}]]'|jq '..|.a'
jq: error (at <stdin>:1): Cannot index array with string "a"
$ echo '[[{"a":1}]]'|jq '..|.a?'
1另一个示例:
# ..会递归产生所有的可能的子元素
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '..'
{
"user": "stedolan",
"titles": [
"JQ Primer",
"More JQ"
]
}
"stedolan"
[
"JQ Primer",
"More JQ"
]
"JQ Primer"
"More JQ"
# 直接..user不起作用
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '..user'
jq: error: syntax error, unexpected IDENT, expecting $end (Unix shell quoting issues?) at <top-level>, line 1:
..user
jq: 1 compile error
# 使用..|.user,因为有元素不是对象,是字符串或数组,将不能应用.user作为索引,因为会抛出异常
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '..|.user'
"stedolan"
jq: error (at <stdin>:1): Cannot index string with string "user"
# 加上?问号,避免抛出异常
$ echo '{"user":"stedolan","titles":["JQ Primer", "More JQ"]}'|jq '..|.user?'
"stedolan"6. 配色方案设置
在我们继续下一章的Builtin operators and functions内置运算符和函数之前,我们先跳到手册最后一章Colors配钯方案设置。
- 要替换默认的配色方案,我们只需要设置一个
JQ_COLORS环境变量即可。 - 需要将
JQ_COLORS设置为以:冒号分隔的终端转义颜色,并且按以下顺序设置:null的颜色。false的颜色。true的颜色。number数字的颜色。string字符串的颜色。array数组、列表的颜色。object对象的颜色。
- 默认配置方案,与设置
JQ_COLORS=1;30:0;37:0;37:0;37:0;32:1;37:1;37是作用相同的。 - 每个颜色都由两个部分组成,中间用分号分隔开。
- 其中,第一部分可以是以下值:
- 1 (bright) 高亮
- 2 (dim) 暗
- 4 (underscore) 下划线
- 5 (blink) 闪烁
- 7 (reverse) 反显
- 8 (hidden) 隐藏
- 第二部分可以是以下值:
- 30 (black) 黑色
- 31 (red) 红色
- 32 (green) 绿色
- 33 (yellow) 花色
- 34 (blue) 蓝色
- 35 (magenta) 品红色
- 36 (cyan) 青色
- 37 (white) 白色
相关定义可以在源码src/jv_print.c中看到:
$ cat -n src/jv_print.c|sed -n '24,36p'
24 #define COL(c) (ESC "[" c "m")
25 #define COLRESET (ESC "[0m")
26
27 // Color table. See https://en.wikipedia.org/wiki/ANSI_escape_code#Colors
28 // for how to choose these.
29 static const jv_kind color_kinds[] =
30 {JV_KIND_NULL, JV_KIND_FALSE, JV_KIND_TRUE, JV_KIND_NUMBER,
31 JV_KIND_STRING, JV_KIND_ARRAY, JV_KIND_OBJECT};
32 static char color_bufs[sizeof(color_kinds)/sizeof(color_kinds[0])][16];
33 static const char *color_bufps[8];
34 static const char* def_colors[] =
35 {COL("1;30"), COL("0;37"), COL("0;37"), COL("0;37"),
36 COL("0;32"), COL("1;37"), COL("1;37")};
$我们构建一个包含所有类型的输出:
$ echo '{"name":"JSON", "good":true, "null": null, "boolean_false": false, "array": [1,2,3.14], "object":{"tool": "jq"}}'|jq
{
"name": "JSON",
"good": true,
"null": null,
"boolean_false": false,
"array": [
1,
2,
3.14
],
"object": {
"tool": "jq"
}
}效果图如下:
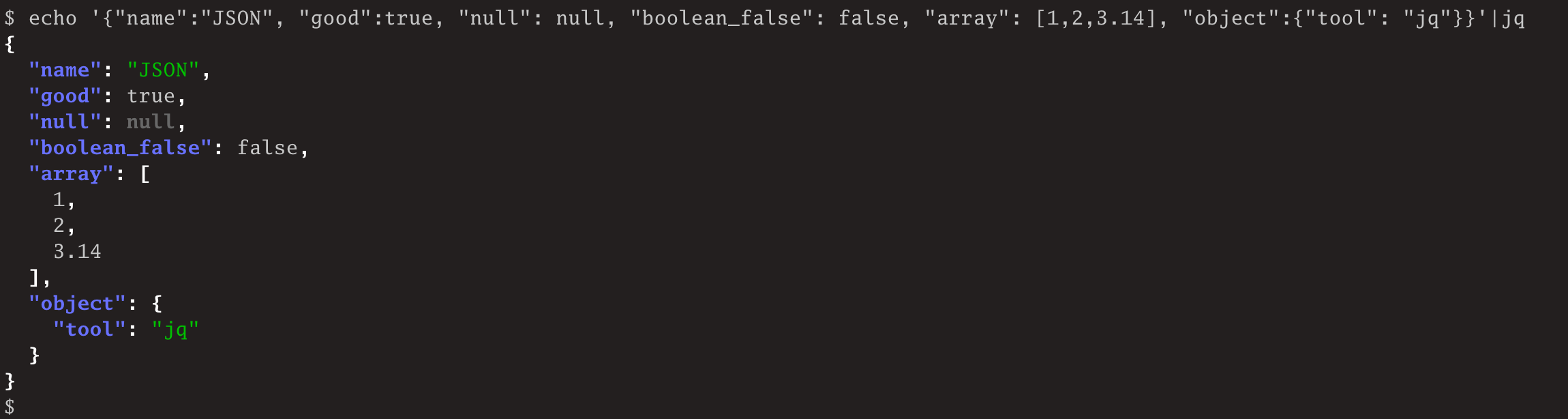
我们改变一下配色方案:
$ export JQ_COLORS="1;31:7;31:1;32:0;37:0;32:1;33:1;37"
$ echo $JQ_COLORS
1;31:7;31:1;32:0;37:0;32:1;33:1;37再次查看效果:
$ echo '{"name":"JSON", "good":true, "null": null, "boolean_false": false, "array": [1,2,3.14], "object":{"tool": "jq"}}'|jq
{
"name": "JSON",
"good": true,
"null": null,
"boolean_false": false,
"array": [
1,
2,
3.14
],
"object": {
"tool": "jq"
}
}效果图如下:
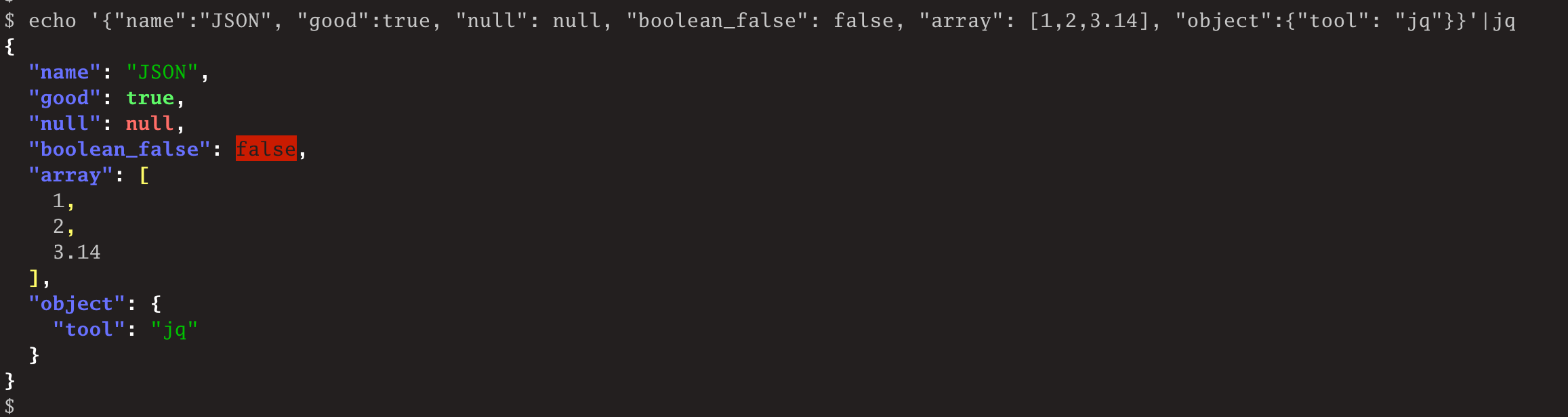
我们将null、false、true和array的配置分别设置为高亮红色、反显红色、高亮绿色、高亮黄色。数字和对象的配色保持不变。
这样我们可以一眼就看出空值和布尔值的不一样!数组的[]能及中间的,逗号都变成黄色了。
如果想还原jq的默认配色方案,我们可以使用删除JQ_COLORS环境变量:
$ unset JQ_COLORS然后jq输出的颜色就是默认配色方案了。
如果后续我们想一直使用这种配色方案,可以将环境变量保存到~/.bashrc文件中。
$ echo -e '# Set the JQ color scheme\nexport JQ_COLORS="1;31:7;31:1;32:0;37:0;32:1;33:1;37"' >> ~/.bashrc
$ tail -n 2 ~/.bashrc
# Set the JQ color scheme
export JQ_COLORS="1;31:7;31:1;32:0;37:0;32:1;33:1;37"可以使用命令source ~/.bashrc使配置生效。
$ source ~/.bashrc7. 内置运算符和函数
- jq运算符会根据参数的类型执行不同的操作。
- jq不会进行隐性式类型转换。
- 所有数字都转换为 IEEE754 双精度浮点表示。
- 当从原始数字文字中提取数字时,数字保持原样不变,直接打印出来。
7.1 内置运算符
7.1.1 加法运算符
+加法运算符(Addition)会根据进行运算的参数的类型进行不同的行为。- 数字相加,则进行算术运算。
- 数组相加,则通过连接形成一个更大的数组。
- 字符串相加,则通过连接形成一个更大的字符串。
- 对象相加,则把所有键值对插入到一个新的对象中,如果两个对象中有键相同,则以右边的对象的键值对为准。
null与其他类型相加,值是该值本身。
# 数字相加,进行算术加法运行
$ echo '{"a": 7}'|jq '.a + 1'
8
# 整数直接相加
$ echo '{"a": 3}'|jq '.a + 2'
5
# 浮点数相加,存在精度问题
$ echo '{"a": 3.1415}'|jq '.a + 2'
5.141500000000001
# 两个数组相加,将所有子元素合并成一个更大的数组,类似于Python中的list.extend
$ echo '{"a": [1,2], "b": [3,4]}'|jq '.a + .b'
[
1,
2,
3,
4
]
# 字符串相加,拼接成一个更大的字符串
$ echo '{"tool": "JQ"}'|jq '.tool + " is nice"'
"JQ is nice"
# 注意,字符串相加时,进行拼接时,不会自动在中间加空格间隔
$ echo '{"tool": "JQ"}'|jq '.tool + "is nice"'
"JQis nice"
# 1与空null相加,输出为1
$ echo '{"a": 1}'|jq '.a + null'
1
# 空null与1相加,输出为1
$ echo '{}'|jq '.a + 1'
1
$ echo 'null'|jq
null
# 对象相加,键相同时,以右边的对象为准
$ echo 'null'|jq '{a: 1} + {b: 2} + {c: 3} + {a: 42}'
{
"a": 42,
"b": 2,
"c": 3
}
# 尝试布尔值相加,抛出异常,布尔值和布尔值不能相加
$ echo '{"boolean": true}'|jq '.boolean + false'
jq: error (at <stdin>:1): boolean (true) and boolean (false) cannot be added
$ echo $?
5
# 布尔值可以和null空相加
$ echo '{"boolean": true}'|jq '.boolean + null'
true7.1.2 减法运算符
- 减法(Subtraction)运算符是
-。 - 作用于数字时,进行普通的算术减法运算。
- 作用于数组时,从第一个数组中删除所有出现在第二个数组中的元素。
- 对象和对象之间不能相减。
- 布尔和布尔之间也不能相减。
# 整数相减
$ echo '{"a":3}'|jq '4 - .a'
1
# 浮点数相减,存在精度问题
$ echo '{"a":3.1415}'|jq '4 - .a'
0.8584999999999998
# 浮点数相减,存在精度问题
$ echo '{"a": -3.1415}'|jq '4 - .a'
7.141500000000001
# 数组相减,会移除数组中相同的元素
$ echo '["xml", "yaml", "json"]'|jq '. - ["xml", "yaml"]'
[
"json"
]
# 数组相减,不会理会第二个数组中多出的元素,如"other"
$ echo '["xml", "yaml", "json"]'|jq '. - ["xml", "yaml", "other"]'
[
"json"
]
# 数组相减,判断元素是否相同,是大小写敏感的,只有完全一样的才会移除掉
$ echo '["xml", "yaml", "json"]'|jq '. - ["XML", "yaml"]'
[
"xml",
"json"
]
# 尝试对象减对象,抛出异常,对象和对象不能相减
$ echo '{"tool": "JQ"}'|jq '. - {"tool": "other"}'
jq: error (at <stdin>:1): object ({"tool":"JQ"}) and object ({"tool":"ot...) cannot be subtracted
$ echo $?
5
# 尝试布尔值相减,抛出异常,布尔值和布尔值不能相减
$ echo '{"boolean": true}'|jq '.boolean - false'
jq: error (at <stdin>:1): boolean (true) and boolean (false) cannot be subtracted
$ echo $?
57.1.3 乘法
- 乘法(Multiplication)运算符使用
*。 - 两数相乘,进行算术相乘。
- 字符串乘以数字,则多次拼接字符串,形成一个长的字符串。字符串乘以0,则返回空。
- 两个对象相乘,则对对象进行递归拼接,工作方法类似于加法运算,相同键时,以右边键为准。
- 布尔值不能与数字相乘,布尔值也不能与布尔值相乘,布尔值也不能与字符串相乘。
- 数组不能与数字相乘,也不能与数组相乘。
# 数字相乘
$ echo '3.14'|jq '. * 2'
6.28
$ echo '3.1415926'|jq '. * 2'
6.2831852
# 数字相乘,也存在精度问题
$ echo '3.1415926'|jq '. * 3'
9.424777800000001
$ echo '3'|jq '. * 3'
9
$ echo '"jq"'|jq
"jq"
# 字符串与数字相乘,会多次拼接该字符串
$ echo '"jq"'|jq '. * 3'
"jqjqjq"
# 字符串与数字相乘,当数大于1时,数字会向下取整,然后再与字符串相乘
$ echo '"jq"'|jq '. * 3.14'
"jqjqjq"
$ echo '"jq"'|jq '. * 3.14155'
"jqjqjq"
$ echo '"jq"'|jq '. * 3.9'
"jqjqjq"
$ echo '"jq"'|jq '. * 3.99999'
"jqjqjq"
# 字符串与数字相乘,当数大于0且小于1时,数字会向上取整得到1,然后再与字符串相乘,即输出字符串本身
$ echo '"jq"'|jq '. * 0.99999'
"jq"
$ echo '"jq"'|jq '. * 0.5999'
"jq"
$ echo '"jq"'|jq '. * 0.5'
"jq"
$ echo '"jq"'|jq '. * 0.4'
"jq"
$ echo '"jq"'|jq '. * 0.1'
"jq"
$ echo '"jq"'|jq '. * 0.0001'
"jq"
$ echo '"jq"'|jq '. * 0.000000000001'
"jq"
# 字符串与0相乘,得到空null
$ echo '"jq"'|jq '. * 0'
null
$ echo '"jq"'|jq '. * -0'
null
# 字符串与负数相乘,得到空null
$ echo '"jq"'|jq '. * -1'
null
$ echo '"jq"'|jq '. * -1.2'
null
$ echo '"jq"'|jq '. * -100'
null
# 字符串与字符串不能相乘
$ echo '"jq"'|jq '. * "JQ"'
jq: error (at <stdin>:1): string ("jq") and string ("JQ") cannot be multiplied
$
# 布尔值不能与数字相乘
$ echo 'true'|jq '. * 1'
jq: error (at <stdin>:1): boolean (true) and number (1) cannot be multiplied
# 布尔值也不能与布尔值相乘
$ echo 'true'|jq '. * false'
jq: error (at <stdin>:1): boolean (true) and boolean (false) cannot be multiplied
# 布尔值也不能与字符串相乘
$ echo 'true'|jq '. * "JQ"'
jq: error (at <stdin>:1): boolean (true) and string ("JQ") cannot be multiplied
# 数组不能与数字相乘
$ echo '[1,2,3]'|jq '.*3'
jq: error (at <stdin>:1): array ([1,2,3]) and number (3) cannot be multiplied
# 数组与数组也不能相乘
$ echo '[1,2,3]'|jq '.* [1,2]'
jq: error (at <stdin>:1): array ([1,2,3]) and array ([1,2]) cannot be multiplied
# 对象和对象相乘,进行递归拼接
$ echo 'null'|jq '{"k": {"a": 1, "b": 2}} * {"k": {"a": 0,"c": 3}}'
{
"k": {
"a": 0,
"b": 2,
"c": 3
}
}7.1.4 除法
- 数字相除就是普通的算术除法,0不能作为除数。
- 字符串除以字符串,则会将第一个字符串用第二个字符串作为分隔符进行拆分。
# 10/5*3=6
$ echo '5'|jq '10 / . * 3'
6
# 字符串相除,用`, `分隔第一个字符串,得到一个数组
$ echo '"a, b,c,d, e"'|jq '. / ", "'
[
"a",
"b,c,d",
"e"
]
# 字符串相除,用`b,c`分隔第一个字符串
$ echo '"a, b,c,d, e"'|jq '. / "b,c"'
[
"a, ",
",d, e"
]
# 字符串相除,当第一个字符串中不存在第二个字符串,直接将第一个字符串放在数组中
$ echo '"a, b,c,d, e"'|jq '. / "b,cc"'
[
"a, b,c,d, e"
]
$ echo '"a, b,c,d, e"'|jq '. / "a,b,c"'
[
"a, b,c,d, e"
]
# 1/0时会抛出异常
$ echo '[1,0,-1]'|jq '.[] | (1 / .)'
1
jq: error (at <stdin>:1): number (1) and number (0) cannot be divided because the divisor is zero
# 使用?可以避免异常抛出
$ echo '[1,0,-1]'|jq '.[] | (1 / .)?'
1
-17.1.5 取模运算符
%运算符是取模运算符。
$ echo '[6,7,8,9]'|jq '.[]| . % 2'
0
1
0
1
$ echo '[6,7,8,9]'|jq '.[]| . % 3'
0
1
2
0
$ echo '[6,7,8,9]'|jq '.[]| . % 4'
2
3
0
1
$ echo '[6,7,8,9]'|jq '.[]| . % 1'
0
0
0
07.2 内置函数
7.2.1 length长度
- 字符串的长度是它包含的 Unicode 代码点的数量(如果它是纯 ASCII,它将与以字节为单位的 JSON 编码长度相同)。
- 数组的长度是元素的个数。
- 对象的长度是键值对的数量。
null的长度是0。- 布尔值没有长度。
$ echo '[[1,2,3], "string", {"a":2, "b":[3,4,5]}, null]'|jq '.[] | length'
3
6
2
0
$ echo 'true'|jq '.|length'
jq: error (at <stdin>:1): boolean (true) has no length7.2.2 utf8bytelength UTF8字节长度
- 将字符串以UTF-8编码后的字节长度。
- 仅字符串支持该函数。
# 测试希腊字母
$ echo -e '"\u03bc"'
"μ"
$ echo -e '"\u03bc"'|jq ".|length"
1
$ echo -e '"\u03bc"'|jq ".|utf8bytelength"
2
# 测试中文
$ echo '"测试"'|jq '.|length'
2
$ echo '"测试"'|jq '.|utf8bytelength'
6
# 测试字母
$ echo '"JQ"'| jq ".|length"
2
$ echo '"JQ"'| jq ".|utf8bytelength"
2
# 仅字符串支持UTF-8编码长度
$ echo 'true'| jq ".|utf8bytelength"
jq: error (at <stdin>:1): boolean (true) only strings have UTF-8 byte length
$ echo '{"tool": "jq"}'| jq ".|utf8bytelength"
jq: error (at <stdin>:1): object ({"tool":"jq"}) only strings have UTF-8 byte length7.2.3 keys 所有的键
- 内置函数
keys用于返回对象的所有的键组成的列表。并按 unicode 代码点顺序“按字母顺序”排序。 - 当内置函数
keys作用于数组时,返回从0开始到数组长度-1的数字序列组成的数组。 keys_unsorted内置函数作用类似,但是按对象的键的原始顺序输出,不进行排序。
# 排序后的输出
$ echo '{"abc": 1, "abcd": 2, "Foo": 3}'|jq 'keys'
[
"Foo",
"abc",
"abcd"
]
# 输入流是数组时,直接输出数组对应的索引组成的序列数组
$ echo '[42,3,35]'|jq 'keys'
[
0,
1,
2
]
# 不排序,按原始顺序输出键的数组
$ echo '{"abc": 1, "abcd": 2, "Foo": 3}'|jq 'keys_unsorted'
[
"abc",
"abcd",
"Foo"
]
# 对于输入流是数组时,keys和keys_unsorted的作用相同
$ echo '[42,3,35]'|jq 'keys_unsorted'
[
0,
1,
2
]null、字符串、布尔值都没有keys,不能使用该函数。
$ echo 'null'|jq 'keys'
jq: error (at <stdin>:1): null (null) has no keys
$ echo '"string"'|jq 'keys'
jq: error (at <stdin>:1): string ("string") has no keys
$ echo 'true'|jq 'keys'
jq: error (at <stdin>:1): boolean (true) has no keys7.2.4 map 将过滤器应用到所有元素
- 对于任意的过滤器
x,map(x)将会将过滤器应用于输入流的每个元素,并返回一个新的数组。 map(. + 1)将会将数组中每个元素自增1。- 类似的,
map_values(x)也会将过滤器应用于输入流的每个元素,但输出是一个对象。 map(x)等价于[.[] | x],map_values(x)等价于.[] |= x。
# 数组每个元素自增1
$ echo '[1,2,3]'|jq 'map(.+1)'
[
2,
3,
4
]
# 验证其定义
$ echo '[1,2,3]'|jq '[.[] | .+1 ]'
[
2,
3,
4
]
# 输入是对象,map会对所有键的值进行处理
$ echo '{"a": 2, "b": 3, "c": 4}'|jq 'map(.+1)'
[
3,
4,
5
]
# map_values会直接对对象的所有键的值进行处理,并保留对象的键
$ echo '{"a": 2, "b": 3, "c": 4}'|jq 'map_values(.+1)'
{
"a": 3,
"b": 4,
"c": 5
}
# 验证定义
$ echo '{"a": 2, "b": 3, "c": 4}'|jq '.[] |= .+1'
{
"a": 3,
"b": 4,
"c": 5
}7.2.5 has 检查是否有给定键
重要说明
为了减少控制台输出的行数,并且与官方的手册中输出结果保持一致,我后面都使用jq -c紧凑型输出结果。并设置重命名:
alias jq='jq -c'- 内置函数
has判断是否输入流的对象是否包含对应的键,包含则返回true,不包含则返回false。或者判断输入流的数组在指定索引处是否有元素。
$ echo '[{"foo": 42}, {}]'| jq 'map(has("foo"))'
[true,false]
$ echo '[[0,1], ["a","b","c"]]'|jq 'map(has(2))'
[false,true]与has相反的是in内置函数。
in内置函数返回输入键是否在给定对象中,或者输入索引是否对应于给定数组中的元素。 它本质上是has的倒置版本。
$ echo '["foo", "bar"]'|jq '.[] | in({"foo": 42})'
true
false
$ echo '[2, 0]'|jq 'map(in([0,1]))'
[false,true]7.2.6 del删除元素
- 内置函数
del会删除对像中指定键的元素。或者删除数组中指定索引的元素。
# 删除对象中键为foo的元素
$ echo '{"foo": 42, "bar": 9001, "baz": 42}'|jq 'del(."foo")'
{"bar":9001,"baz":42}
# 删除对象中键为foo的元素
$ echo '{"foo": 42, "bar": 9001, "baz": 42}'|jq 'del(.foo)'
{"bar":9001,"baz":42}
# 删除对象中键为bar的元素
$ echo '{"foo": 42, "bar": 9001, "baz": 42}'|jq 'del(.bar)'
{"foo":42,"baz":42}
# 删除数组中索引为1或2的元素
$ echo '["foo", "bar", "baz"]'|jq 'del(.[1, 2])'
["foo"]
# 删除数组中索引为0或1或2的元素
$ echo '["foo", "bar", "baz"]'|jq 'del(.[0, 1, 2])'
[]
# 删除数组中索引为0或1或2或3的元素,索引为3的元素本来就不存在,此处不报错
$ echo '["foo", "bar", "baz"]'|jq 'del(.[0, 1, 2, 3])'
[]
# 删除数组中索引为2的元素
$ echo '["foo", "bar", "baz"]'|jq 'del(.[2])'
["foo","bar"]7.2.7 to_entries 对象转换成健值对组成的列表
to_entries内置函数可以将对象进行转换,对于每一个k: v键值对,会转换成以下对象{"key": k, "value": v},将将这些对象放在数组中。from_entries刚好进行相反的操作。- 而
with_entries(foo)是操作to_entries | map(foo) | from_entries的快捷方式。 from_entries支持以下名称的键:key,Key,name,Name,value,Value。
看以下示例:
# 将对象转换成了包含键值对的数组
$ echo '{"a": 1, "b": 2}'|jq 'to_entries'
[{"key":"a","value":1},{"key":"b","value":2}]
$
# 反向操作,最后得到相应的对象
$ echo '[{"key":"a","value":1},{"key":"b","value":2}]'|jq 'from_entries'
{"a":1,"b":2}from_entries支持不同的键的名称:
# 使用key或Key作为键,使用value或Value作为健
$ echo '[{"key":"a","value":1},{"Key":"b","Value":2}]'|jq 'from_entries'
{"a":1,"b":2}
# 使用name或Name作为键,使用value或Value作为健
$ echo '[{"name":"a","value":1},{"Name":"b","Value":2}]'|jq 'from_entries'
{"a":1,"b":2}注意,不能用其他值作为键:
# 用NAME作为键,抛出异常
$ echo '[{"name":"a","value":1},{"NAME":"b","v":2}]'|jq 'from_entries'
jq: error (at <stdin>:1): Cannot use null (null) as object keywith_entries的使用:
$ echo '{"a": 1, "b": 2}'|jq 'with_entries(.key |= "KEY_" + .)'
{"KEY_a":1,"KEY_b":2}可以看到可以形成新的键。
7.2.8 select 筛选
- 如果对输入流进行
foo过滤后返回true的话,那么select(foo)将会原样返回输出,否则没有输出。 - 这个对过滤数组非常有用,如
[1,2,3] | map(select(. >= 2))将会返回[2,3]。
# 检查定义
$ echo '2'|jq '. > 1'
true
$ echo '2'|jq '. > 2'
false
# 由于. > 1 返回的true, 因此select(. > 1)返回输入流2本身
$ echo '2'|jq 'select(. > 1)'
2
# 由于. > 2 返回的false, 因此select(. > 2)不返回任何东西
$ echo '2'|jq 'select(. > 2)'
$筛选过滤数组:
# 筛选出数组中大于2的元素
$ echo '[1,5,3,0,7]'|jq 'map(select(. >= 2))'
[5,3,7]
# 筛选出数组中子元素对象的键id的值是"second"的元素
$ echo '[{"id": "first", "val": 1}, {"id": "second", "val": 2}]'|jq '.[] | select(.id == "second")'
{"id":"second","val":2}
# 迭代显示数组中每一个对象元素
$ echo '[{"id": "first", "val": 1}, {"id": "second", "val": 2}]'|jq '.[]'
{"id":"first","val":1}
{"id":"second","val":2}7.2.9 arrays等 筛选出指定的元素
arrays筛选出所有数组。objects筛选出所有对象。iterables筛选出所有可迭代值。booleans筛选出所有布尔值。numbers筛选出所有数字。normals筛选出所有普通数。finites筛选出所有有限数。strings筛选出所有字符串。nulls筛选出所有空值。values筛选出所有非空值。scalars筛选出所有不可迭代值。
下面我们看一下示例:
# 获取数组
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | arrays'
[1,2]
[3,4]
# 获取对象
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | objects'
{"tool":"jq"}
{"name":"JSON"}
# 获取可迭代值,包括数组和对象是可迭代的
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | iterables'
[1,2]
[3,4]
{"tool":"jq"}
{"name":"JSON"}
# 获取不可迭代值,包含数字、字符串、null、布尔值
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | scalars'
1
"foo"
5
-2
3.1415926
null
true
false
"bar"
$
# 获取布尔值
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | booleans'
true
false
# 获取所有数字
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | numbers'
1
5
-2
3.1415926
# # 获取所有普通数
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | normals'
1
5
-2
3.1415926
# 获取所有有限数
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | finites'
1
5
-2
3.1415926
$
# 获取所有字符串
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | strings'
"foo"
"bar"
$
# 获取所有空值null
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | nulls'
null
# # 获取所有非空值
$ echo '[[1,2],[3,4],{"tool": "jq"},1,"foo",5,-2,3.1415926,{"name": "JSON"},null,true,false,"bar"]'|jq '.[] | values'
[1,2]
[3,4]
{"tool":"jq"}
1
"foo"
5
-2
3.1415926
{"name":"JSON"}
true
false
"bar"7.2.10 empty 不返回任何值
- 内置函数
empty不返回任何值,也不会输出null,什么也不输出。有时会很有用。 - 我理解可以类似于Python中的
pass进行占位。
$ echo 'null'|jq '1, empty, 2'
1
2
$ echo 'null'|jq '[1,2,empty,3]'
[1,2,3]7.2.11 自己抛出带消息的异常
- 使用
error(message)抛出带消息的异常。可以使用try..catch语法进行捕获。
$ echo 'null'|jq 'error("raise error by myself")'
jq: error (at <stdin>:1): raise error by myself
$ echo $?
5可以看到使用error抛出异常时,退出码为5。
7.2.12 halt退出
- 内置函数
halt可以直接退出jq程序,并且不输出任何内容。退出码为0。 - 内置函数
halt_error会直接退出jq程序,并将输入流输出到标准异常中(注意:字符串没有两侧的双引号。程序不会自动换行。) halt_error默认退出码是5,你可以通过halt_error(exit_code)设置不同的退出码。
请看示例:
# 使用halt会直接退出,退出码是0,不会输出任何消息
$ echo '"Error: somthing went wrong\nOther message."'|jq 'halt'
$ echo $?
0
# 使用halt_error会异常退出,退出码默认是5,会直接将输入流输出
# 字符串两侧的双引号不会输出,也不会自动添加换行符
$ echo '"Error: somthing went wrong\nOther message."'|jq 'halt_error'
Error: somthing went wrong
Other message.$ echo $?
5
# 使用halt_error指定退出码为2
$ echo '"Error: somthing went wrong\nOther message."'|jq 'halt_error(2)'
Error: somthing went wrong
Other message.$ echo $?
2
# 使用halt_error也可以指定退出码为0
$ echo '"Error: somthing went wrong\nOther message."'|jq 'halt_error(0)'
Error: somthing went wrong
Other message.$ echo $?
07.2.13 add 操作
- 内置函数
add作用于array输入流,并将数组中的元素相加作为输出。 - 根据元素类型不同,作用有可能是算术加法、字符串拼接等。作用与
+操作符一样。
# 字符串序列的数组可以相加,将所有字符串拼接在一起
$ echo '["a","b","c"]'|jq 'add'
"abc"
# 数字序列的数组可以相加,将所有数字进行算术加法求和
$ echo '[1,2,3]'|jq 'add'
6
# 空元素相加返回null
$ echo '[]'|jq 'add'
null
# 字符串与数字不能相加
$ echo '["a","b",1]'|jq 'add'
jq: error (at <stdin>:1): string ("ab") and number (1) cannot be added
# 数字也不能和布尔值相加
$ echo '[1,2,true]'|jq 'add'
jq: error (at <stdin>:1): number (3) and boolean (true) cannot be added
# 布尔值也不能相加
$ echo '[false,true]'|jq 'add'
jq: error (at <stdin>:1): boolean (false) and boolean (true) cannot be added
$7.2.14 any有元素为true
过滤器
any将布尔值数组作为输入,如果数组的任何元素为真(true),则生成true作为输出。如果输入是空数组,则
any返回false。any(condition)形式将给定的条件应用于输入数组的元素。
# 数组元素中有一个为true,any就会返回true
$ echo '[true, false]'|jq 'any'
true
# 数组元素中没有true,则返回false
$ echo '[false, false]'|jq 'any'
false
# 空数组时,any返回false
$ echo '[]'|jq 'any'
false
# 数字元素组成的数组时,any返回也是true
$ echo '[1,2]'|jq 'any'
true
# 数字0作为数组元素时,any返回也是true
$ echo '[0]'|jq 'any'
true
# 字符串作为数组元素时,any返回也是true
$ echo '["string"]'|jq 'any'
true
# 对象作为数组元素时,any返回也是true
$ echo '[{"name": "JQ"}]'|jq 'any'
true
# 空数组作为数组元素时,any返回也是true
$ echo '[[]]'|jq 'any'
true
# null空作为数组元素时,any返回是false
$ echo '[null]'|jq 'any'
false
# 多个null空作为数组元素时,any返回也是false
$ echo '[null,null]'|jq 'any'
false7.2.15 all所有元素为true
- 内置函数
all与any类似,只是需要数组中所有元素都是true才返回true。 - 如果输入流是
[]空数组,输出是true。
$ echo '[true, false]'|jq 'all'
false
$ echo '[true, true]'|jq 'all'
true
$ echo '[]'|jq 'all'
true7.2.16 flatten 展平数组
- 内置函数
flatten可以将多层嵌套的数组展平到同一平面上来,并形成新的数组。你也可以通过flatten(depth)来指定展平深度。不指定时,默认全部展平。
我们来看一下示例。
# flatten不带参数,会把每层中的数值都解析出来,然后形成一个新的数组
$ echo '[1, [2], [[3]]]'|jq 'flatten'
[1,2,3]
# 指定层数为1
# 子元素不是数组的数字1,被直接收集起来,作为第1个元素,
# 子元素`[2]`剥去一层`[]`就只剩下数字2了,作为第2个元素
# 子元素`[[3]]`剥去一层`[]`后,剩下的值为`[3]`,作为第3个元素
# 因此,输入流剥去一层`[]`后形成的数据是`[1, 2, [3]]
$ echo '[1, [2], [[3]]]'|jq 'flatten(1)'
[1,2,[3]]
$
# 如果指定展平深度为0,那输出数据就是输入流的数据
$ echo '[1, [2], [[3]]]'|jq 'flatten(0)'
[1,[2],[[3]]]
# 指定展平深度为2,在展平一层数据的基础上再剥去一层`[]`,即将`1, 2, [3]`再剥去一层中括号
# 只有`[3]`外面有括号,去掉后,剩下的数据是3,再和前面的1,2组合在一起,形成了`[1, 2, 3]`这样的新的数据。
$ echo '[1, [2], [[3]]]'|jq 'flatten(2)'
[1,2,3]
# 如果设置深度为负数,则抛出异常
$ echo '[1, [2], [[3]]]'|jq 'flatten(-1)'
jq: error (at <stdin>:1): flatten depth must not be negative
# 设置再深的深度,输出结果不会再变更
$ echo '[1, [2], [[3]]]'|jq 'flatten(3)'
[1,2,3]数组中包含对象的示例:
$ echo '[{"foo": "bar"}, [{"foo": "baz"}]]'|jq 'flatten'
[{"foo":"bar"},{"foo":"baz"}]
$ echo '[{"foo": "bar"}, [{"foo": "baz"}]]'|jq 'flatten(1)'
[{"foo":"bar"},{"foo":"baz"}]这个内置函数可以快速去除掉数组中所有的子数组,将所有有效元素放在同一个平面,然后形成一个新的数组。在有的时候应该会很有用。
下面看一个特殊的,如果对象的值是数组的话,对象的值中的数组并不会被展平。
$ echo '[{"foo": "bar"}, [{"foo": [1,2,3]}]]'|jq 'flatten'
[{"foo":"bar"},{"foo":[1,2,3]}]
$可以看到,只将[{"foo": [1,2,3]}]展平为{"foo": [1,2,3]}。键foo对应的值[1,2,3]并没有被展平。
7.2.17 range数字系列
- 内置函数
range可以返回数字系列。 range(n)输出从0到n-1的数字系列。range(start; end)输出从start到end-1的数字系列(不包含end)。range(start; end; step),输出从start到end-1中间步长为step的数字系列(不包含end),步长默认为1。- 注意,当有多个参数时,参数中间是用
;分号分隔,不是,逗号。
# 直接使用`range(4)`,将迭代输出0,1,2,3,不会输出4,不包含4
$ echo 'null'|jq 'range(4)'
0
1
2
3
# 使用`range(2:4)`将会迭代输出2,3
$ echo 'null'|jq 'range(2;4)'
2
3
# 将输出结果组成一个数组
$ echo 'null'|jq '[range(4)]'
[0,1,2,3]
$ echo 'null'|jq '[range(2;4)]'
[2,3]
$
# 设置步长为3
$ echo 'null'|jq '[range(0;10;3)]'
[0,3,6,9]
# 设置步长为-3时,从0到10之间没有小于0的数据,输出为空数组
$ echo 'null'|jq '[range(0;10;-3)]'
[]
# 设置步长为-2,输出依次是0, -2, -4
$ echo 'null'|jq '[range(0;-5;-2)]'
[0,-2,-4]
# 步长也可以设置为小数
$ echo 'null'|jq '[range(0; 12; 2.25)]'
[0,2.25,4.5,6.75,9,11.25]7.2.18 floor 向下取整
floor函数,其功能是“向下取整”,或者说“向下舍入”,即取不大于x的最大整数。
$ echo '3.1415'|jq 'floor'
3
$ echo '3.9415'|jq 'floor'
3
$ echo '0.9415'|jq 'floor'
0
$ echo '-0.9415'|jq 'floor'
-1
$ echo '-0.0015'|jq 'floor'
-17.2.19 sqrt 开方
sqrt返回数字的平方根。
$ echo '9'|jq 'sqrt'
3
$ echo '8'|jq 'sqrt'
2.8284271247461903
$ echo '4'|jq 'sqrt'
2
$ echo '2'|jq 'sqrt'
1.4142135623730951
$ echo '0'|jq 'sqrt'
0
# 负数没有平方根
$ echo '-2'|jq 'sqrt'
null7.2.20 tonumber 字符串转换成数字
tonumber将会将格式正常的数字字符串转换成数字。
# 字符串转数字
$ echo '"1001"'|jq 'tonumber'
1001
# 超过有效范围的数字被忽略
$ echo '"1.23456789012345678901234567890"'|jq 'tonumber'
1.2345678901234567
$
$ echo '"1.2345678901234567"'|jq 'tonumber'
1.2345678901234567
$
# 指数的使用
$ echo '"1.2e2"'|jq 'tonumber'
120
$ echo '"1.2e3"'|jq 'tonumber'
1200
$ echo '"1.2e-3"'|jq 'tonumber'
0.0012
$tostring将数字转换成字符串。
$ echo '1002'|jq 'tostring'
"1002"
$ echo '1.2e3'|jq 'tostring'
"1200"
# 指数转换成小数字符串
$ echo '1.2e-3'|jq 'tostring'
"0.0012"
# 位数太长时出现精度问题
$ echo '1.2345678901234567890'|jq 'tostring'
"1.2345678901234567"
$7.2.21 type类型
- 内置函数
type返回参数的的类型。
$ echo '[0, false, [1,2,3], {"tool": "JQ"}, null, "hello"]'|jq 'map(type)'
["number","boolean","array","object","null","string"]依次输出的数据类型为:数字、布尔值、数组、对象、空值、字符串。
7.2.22 sort数组排序
- 内置函数
sort可以对数组进行排序,值按以下顺序排序:null空值。false布尔值假。true布尔值真。- 数字。
- 字符串,按字母顺序排列。
- 数组。
- 对象。
- 对象的排序相对复杂一些,首先比较它们键的集合,如果键相同,则一个一个地比较键的值。
sort可用于按对象的特定字段或通过应用任何 jq 过滤器进行排序。sort_by(foo)通过比较foo在每个元素上的结果来比较两个元素。
$ echo '["string","String", null, true, false,1, -1.2, [1,2,3], {"name": "JSON"},[1,2,4],{"name": "jq"},[1,1,2], {"Name": "jq"}]'|jq 'sort'
[null,false,true,-1.2,1,"String","string",[1,1,2],[1,2,3],[1,2,4],{"Name":"jq"},{"name":"JSON"},{"name":"jq"}]可以看到:
- 数字是按从负到正排序。
- 字符串是大写字母先排序,小写字母后排序。
- 数组的话,按每个索引进行排序。
- 对象的话,按键名排序(大写字母在前,小写字母在后),键名相同的话,则再按值排序。
按指定键名排序:
# 按键foo进行排序
$ echo '[{"foo":4, "bar":10}, {"foo":3, "bar":100}, {"foo":2, "bar":1}]'|jq 'sort_by(.foo)'
[{"foo":2,"bar":1},{"foo":3,"bar":100},{"foo":4,"bar":10}]
# 按键bar进行排序
$ echo '[{"foo":4, "bar":10}, {"foo":3, "bar":100}, {"foo":2, "bar":1}]'|jq 'sort_by(.bar)'
[{"foo":2,"bar":1},{"foo":4,"bar":10},{"foo":3,"bar":100}]7.2.23 group_by分组
- 内置函数
group_by(.foo)可以对数组中的对象按.foo的值进行排序(按sort函数的方式排序),并按foo字段进行分组,形成一个大的分组后的数组。
# 获取每个子对象的foo字段的值
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'map(.foo)'
[1,3,1,null]
# 第1和第3个子对象有相同的键值1,会分为一组。
# 按sort排序的话,排序应为null,1,1,3
# 因此,第4个元素排在第1位,第1个元素和第3个元素合并为一组,并排在第2位,而第2个元素对应的键foo的值3最大,排在最后一个位置,也就是第3位,最终形成3个子数组
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'group_by(.foo)'
[[{"other":"other value"}],[{"foo":1,"bar":10},{"foo":1,"bar":100}],[{"foo":3,"bar":100}]]
# 获取每个子对象的bar字段的值
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'map(.bar)'
[10,100,100,null]
# 第2和第3个子对象有相同的键值100,会分为一组。
# 按sort排序的话,排序应为null,10,100,100
# 因此,第4个元素排在第1位,第1个元素排在第2位,第2个元素和第3个元素合并为一组,并排在第3位,最终形成3个子数组
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'group_by(.bar)'
[[{"other":"other value"}],[{"foo":1,"bar":10}],[{"foo":3,"bar":100},{"foo":1,"bar":100}]]
$
# 获取每个子对象的other字段的值
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'map(.other)'
[null,null,null,"other value"]
# 前3个子对象都没有键other,.other的值都是null空,会分为一组。
# 第4个子对象有键other,对应的值非空,会被单独分为一组。因此最后形成两个子数组。
# 分组组内元素按原始顺序输出。
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'group_by(.other)'
[[{"foo":1,"bar":10},{"foo":3,"bar":100},{"foo":1,"bar":100}],[{"other":"other value"}]]看一下,下面这种{"other": null}这种更特殊的情况:
# 按foo字段排序时,与上面的{"other": "other value"}时一样
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'map(.foo)'
[1,3,1,null]
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'group_by(.foo)'
[[{"other":null}],[{"foo":1,"bar":10},{"foo":1,"bar":100}],[{"foo":3,"bar":100}]]
# 按bar字段排序时,与上面的{"other": "other value"}时一样
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'map(.bar)'
[10,100,100,null]
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'group_by(.bar)'
[[{"other":null}],[{"foo":1,"bar":10}],[{"foo":3,"bar":100},{"foo":1,"bar":100}]]
# 按other字段排序时,与上面的{"other": "other value"}时的结果就不一样了!!!!
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'map(.other)'
[null,null,null,null]
# 4个元素的other字段的输出结果都是null空
# 前3个元素对象因为没有other字段,那么.other的值是null空;而第4个元素有other字段,但其.other的值直接是null空
# 因此,4个元素的.other值都是null空,就会统一分配到一个组中
# 也就是最后在数组中只会形成一个子的数组元素!
# 这与{"other": "other value"}时是不一样的!!!!
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'group_by(.other)'
[[{"foo":1,"bar":10},{"foo":3,"bar":100},{"foo":1,"bar":100},{"other":null}]]7.2.24 min/max 最小最大值
- 内置函数
min或max可以获取输入数组中的最小值、最大值。 - 而
min_by(exp)或max_by(exp)允许你指定一个特殊的字段或属性来获取最小最大值。如min_by(.foo)则按子元素中foo字段排序后,获取最小值。
# 获取数组中的最小值
$ echo '[5,4,2,7]'|jq 'min'
2
# 获取数组中的最大值
$ echo '[5,4,2,7]'|jq 'max'
7
# 按foo字段排序获取最小值
$ echo '[{"foo":1, "bar":14}, {"foo":2, "bar":3}]'|jq 'min_by(.foo)'
{"foo":1,"bar":14}
# 按bar字段排序获取最小值
$ echo '[{"foo":1, "bar":14}, {"foo":2, "bar":3}]'|jq 'min_by(.bar)'
{"foo":2,"bar":3}
# 按foo字段排序获取最大值
$ echo '[{"foo":1, "bar":14}, {"foo":2, "bar":3}]'|jq 'max_by(.foo)'
{"foo":2,"bar":3}
# 按bar字段排序获取最大值
$ echo '[{"foo":1, "bar":14}, {"foo":2, "bar":3}]'|jq 'max_by(.bar)'
{"foo":1,"bar":14}对字符串求最小最大值:
# 字符串会按字母升序排序
$ echo '["one", "two", "three", "four"]'|jq 'sort'
["four","one","three","two"]
# 最小值是four
$ echo '["one", "two", "three", "four"]'|jq 'min'
"four"
# 最大值是two
$ echo '["one", "two", "three", "four"]'|jq 'max'
"two"
# 获取每个子元素的长度
$ echo '["one", "two", "three", "four"]'|jq 'map(length)'
[3,3,5,4]
# 长度最小为3,one和two长度都为3,one排在前面,因此取one作为最小值
$ echo '["one", "two", "three", "four"]'|jq 'min_by(length)'
"one"
# 长度最大为5,对应的值是three
$ echo '["one", "two", "three", "four"]'|jq 'max_by(length)'
"three"7.2.25 unique 数组去重
unique可以去除数组中重复的元素。unique_by(path_exp)可以理解为使用group_by分组后,然后取每个组里面的一个元素,作为最终的数组元素。
可参考7.2.23 group_by分组 小节。
# 对数字系列去重
$ echo '[1,2,5,3,5,3,1,3]'|jq 'unique'
[1,2,3,5]
# 对字符串长度去重
$ echo '["chunky", "bacon", "kitten", "cicada", "asparagus"]'|jq 'unique_by(length)'
["bacon","chunky","asparagus"]
# 对字符串长度去重
$ echo '["one", "two", "three", "four"]'|jq 'unique_by(length)'
["one","four","three"]
# 按foo字段去重
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'unique_by(.foo)'
[{"other":"other value"},{"foo":1,"bar":10},{"foo":3,"bar":100}]
# 按bar字段去重
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'unique_by(.bar)'
[{"other":"other value"},{"foo":1,"bar":10},{"foo":3,"bar":100}]
# 按other字段去重
# 前三个元素对象没有other字段,.other都是null空,只保留第一个元素{"foo":1, "bar":10}
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": "other value"}]'|jq 'unique_by(.other)'
[{"foo":1,"bar":10},{"other":"other value"}]
# 当第4个元素对象的other键的值是null时,四个元素对象的.other值都是null空。
# 因此只保留第一个元素对象
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'unique_by(.other)'
[{"foo":1,"bar":10}]7.2.26 reverse 数组反转
- 内置函数
reverse会将数组元素的前后次序进行颠倒(反转)。
$ echo '[1,2,3,4]'|jq 'reverse'
[4,3,2,1]
$ echo '["one", "two", "three", "four"]'|jq 'reverse'
["four","three","two","one"]
$ echo '[{"foo":1, "bar":10}, {"foo":3, "bar":100}, {"foo":1, "bar":100}, {"other": null}]'|jq 'reverse'
[{"other":null},{"foo":1,"bar":100},{"foo":3,"bar":100},{"foo":1,"bar":10}]7.2.27 contains 包含
内置函数
contains(element)处理输入流是否完全包含元素element。最后返回布尔值。判断标准如下:
- 如果元素B是字符串,并且是输入流(A是字符串)的子串的话,则认为A包含B。
- 如果数组B中的所有元素都被A的元素所包含,那么认为数组A包含数组B。
- 如果对象B中的所有值都包含在对象A中,则认为对象A包含对象B。
看如下示例:
# 字符串foo包含在字符串foobar中,因此返回true
$ echo '"foobar"'|jq 'contains("foo")'
true
# 字符串bar包含在字符串foobar中,因此也返回true
$ echo '"foobar"'|jq 'contains("bar")'
true
# 数组["baz", "bar"]第一个元素baz包含在输入数组的第二个元素foobaz中
# 数组["baz", "bar"]第二个元素bar包含在输入数组的第一个元素foobar中
# 因此数组["baz", "bar"]中每一个元素都被输入流数组所包含
# 因此返回true
$ echo '["foobar", "foobaz", "blarp"]'|jq 'contains(["baz", "bar"])'
true
$ echo '["foobar", "foobaz", "blarp"]'|jq 'contains(["baz", "bar", "arp"])'
true
# 数组["bazzzzz", "bar"]第一个元素bazzzzz不被输入数组的任何一个元素包含
# 因此两个数组不存在包含关系,返回false
$ echo '["foobar", "foobaz", "blarp"]'|jq 'contains(["bazzzzz", "bar"])'
false
# 存在嵌套时,需要看对应的path是否真的存在
$ echo '{"foo": 12, "bar":[1,2,{"barp":12, "blip":13}]}'|jq 'contains({foo: 12, bar: [{barp: 12}]})'
true
# 此处不存在 bar: [{barp: 15}] 这个子元素
# 最终返回false
$ echo '{"foo": 12, "bar":[1,2,{"barp":12, "blip":13}]}'|jq 'contains({foo: 12, bar: [{barp: 15}]})'
falseinside(b)操作刚好是contains的反向操作。即检查输入流是否在b中。
$ echo '"bar"'|jq 'inside("foobar")'
true
$ echo '["baz", "bar"]'|jq 'inside(["foobar", "foobaz", "blarp"])'
true
$ echo '["bazzzzz", "bar"]'|jq 'inside(["foobar", "foobaz", "blarp"])'
false
$ echo '{"foo": 12, "bar": [{"barp": 12}]}'|jq 'inside({"foo": 12, "bar":[1,2,{"barp":12, "blip":13}]})'
true
$ echo '{"foo": 12, "bar": [{"barp": 15}]}'|jq 'inside({"foo": 12, "bar":[1,2,{"barp":12, "blip":13}]})'
false7.2.28 indices 索引位置
- 内置函数
indices(s)可以输出s在输入字符串或数组中的索引位置。
请看示例:
# 判断字符串`, `在长字符串的索引位置
# 字符串位置从0开始标号
$ echo '"a,b, cd, efg, hijk"'|jq 'indices(", ")'
[3,7,12]
$ echo '[0,1,2,1,3,1,4]'|jq 'indices(1)'
[1,3,5]
$ echo '[0,1,2,3,1,4,2,5,1,2,6,7]'|jq 'indices([1,2])'
[1,8]- 内置函数
index(s)、rindex(s)会输出s在输入流中第一次或最后一次出现处的索引。当有多次匹配时,这两个函数的结果相当于indices(s)的第1个元素和最后一个元素的值。
$ echo '"a,b, cd, efg, hijk"'|jq 'index(", ")'
3
$ echo '"a,b, cd, efg, hijk"'|jq 'rindex(", ")'
12
$ echo '[0,1,2,1,3,1,4]'|jq 'index(1)'
1
$ echo '[0,1,2,1,3,1,4]'|jq 'rindex(1)'
5
$ echo '[0,1,2,3,1,4,2,5,1,2,6,7]'|jq 'index([1,2])'
1
$ echo '[0,1,2,3,1,4,2,5,1,2,6,7]'|jq 'rindex([1,2])'
8
$
# 仅有一次匹配的情况
# 此时index和rindex返回的结果是一样的
$ echo '[1]'|jq 'index(1)'
0
$ echo '[1]'|jq 'rindex(1)'
07.2.29 startswith/endswith 以字符串开头/结尾
startswith(str)判断给定输入流是否以str字符串开头。endswith(str)判断给定输入流是否以str字符串结尾。startswith和endswith的输入流应是字符串。
# 对单个字符串进行判断
$ echo '"JQ"'|jq 'startswith("JQ")'
true
$ echo '"JQ"'|jq 'endswith("JQ")'
true
# 输入流应该是字符串
$ echo 'true'|jq 'startswith("true")'
jq: error (at <stdin>:1): startswith() requires string inputs
# 对数组中多个字符串元素进行判断
$ echo '["fo", "foo", "barfoo", "foobar", "barfoob"]'|jq '[.[]|startswith("foo")]'
[false,true,false,true,false]
$ echo '["fo", "foo", "barfoo", "foobar", "barfoob"]'|jq '[.[]|endswith("foo")]'
[false,true,true,false,false]7.2.30 combinations数组元素组合
- 内置函数
combinations可以输出输入流数组中所有数组从每个子数组中取一个元素出来形成数组的所有组合。 - 如果给定参数
n,即combinations(n),将会输出输入数组子元素的 n 次重复的所有组合。
# 不带参数时,输入流的数组必须包含子数组
$ echo '[0, 1]'|jq 'combinations'
jq: error (at <stdin>:1): Cannot iterate over number (0)
# 从一个子元素中取一个元素出来,可以形成2个数组
$ echo '[[0, 1]]'|jq 'combinations'
[0]
[1]
# 有两个子数组时,从每个子数组中取一个元素形成一个新的数组,有 2 * 2 = 4种情形
$ echo '[[1,2], [3, 4]]'|jq 'combinations'
[1,3]
[1,4]
[2,3]
[2,4]
# 有三个子数组时,从每个子数组中取一个元素形成一个新的数组,有 2 * 2 * 2= 8种情形
$ echo '[[1,2], [3, 4], [5,6]]'|jq 'combinations'
[1,3,5]
[1,3,6]
[1,4,5]
[1,4,6]
[2,3,5]
[2,3,6]
[2,4,5]
[2,4,6]
$ echo '[[1,2], [3, 4], [5,6]]'|jq 'combinations'|wc -l
8
# 有四个子数组时,从每个子数组中取一个元素形成一个新的数组,有 2 * 2 * 2 * 2= 16种情形
$ echo '[[1,2], [3, 4], [5,6], [7,8]]'|jq 'combinations'
[1,3,5,7]
[1,3,5,8]
[1,3,6,7]
[1,3,6,8]
[1,4,5,7]
[1,4,5,8]
[1,4,6,7]
[1,4,6,8]
[2,3,5,7]
[2,3,5,8]
[2,3,6,7]
[2,3,6,8]
[2,4,5,7]
[2,4,5,8]
[2,4,6,7]
[2,4,6,8]
$ echo '[[1,2], [3, 4], [5,6], [7,8]]'|jq 'combinations'|wc -l
16
# 有2个子数组时,从每个子数组中取一个元素形成一个新的数组,有 3 * 3 = 9种情形
$ echo '[[1,2,3], [3,4,6]]'|jq 'combinations'
[1,3]
[1,4]
[1,6]
[2,3]
[2,4]
[2,6]
[3,3]
[3,4]
[3,6]
# 有2个子数组时,从每个子数组中取一个元素形成一个新的数组,有 3 * 3 = 9种情形
$ echo '[[1,2,3], [1,2,3]]'|jq 'combinations'
[1,1]
[1,2]
[1,3]
[2,1]
[2,2]
[2,3]
[3,1]
[3,2]
[3,3]带参数的情况:
# 输入流包含两个子元素时,如果带参数,取0次子元素只能得到一个空数组
$ echo '[0, 1]'|jq 'combinations(0)'
[]
# 输入流包含两个子元素时,如果带参数,取1次子元素,分别形成数组,可形成2个数组
$ echo '[0, 1]'|jq 'combinations(1)'
[0]
[1]
# 输入流包含两个子元素时,如果带参数,取2次子元素,分别形成数组,可形成 2 * 2 = 4 个数组
$ echo '[0, 1]'|jq 'combinations(2)'
[0,0]
[0,1]
[1,0]
[1,1]
# 输入流包含两个子元素时,如果带参数,取3次子元素,分别形成数组,可形成 2 * 2 * 2 = 8 个数组
$ echo '[0, 1]'|jq 'combinations(3)'
[0,0,0]
[0,0,1]
[0,1,0]
[0,1,1]
[1,0,0]
[1,0,1]
[1,1,0]
[1,1,1]
# 输入流包含两个子数组时,如果带参数,取1次子数组,分别形成数组,可形成 2 个数组
$ echo '[[1,2], [3, 4]]'|jq 'combinations(1)'
[[1,2]]
[[3,4]]
# 输入流包含两个子数组时,如果带参数,取2次子数组,分别形成数组,可形成 2 * 2 = 4 个数组
$ echo '[[1,2], [3, 4]]'|jq 'combinations(2)'
[[1,2],[1,2]]
[[1,2],[3,4]]
[[3,4],[1,2]]
[[3,4],[3,4]]
# 输入流包含两个子数组时,如果带参数,取3次子数组,分别形成数组,可形成 2 * 2 * 2 = 8 个数组
$ echo '[[1,2], [3, 4]]'|jq 'combinations(3)'
[[1,2],[1,2],[1,2]]
[[1,2],[1,2],[3,4]]
[[1,2],[3,4],[1,2]]
[[1,2],[3,4],[3,4]]
[[3,4],[1,2],[1,2]]
[[3,4],[1,2],[3,4]]
[[3,4],[3,4],[1,2]]
[[3,4],[3,4],[3,4]]7.2.31 移除字符串两端指定字符
- 内置函数
ltrimstr(str)移除输入流中字符串左侧的str字符串。 - 内置函数
rtrimstr(str)移除输入流中字符串右侧的str字符串。
$ echo '"start_end"'|jq 'ltrimstr("start")'
"_end"
$ echo '"start_end"'|jq 'rtrimstr("end")'
"start_"
$ echo '["fo", "foo", "barfoo", "foobar", "afoo"]'|jq '[.[]|ltrimstr("foo")]'
["fo","","barfoo","bar","afoo"]
$ echo '["fo", "foo", "barfoo", "foobar", "afoo"]'|jq '[.[]|rtrimstr("foo")]'
["fo","","bar","foobar","a"]7.2.32 字符串与字符串代码点编号之间的转换
可以简单理解为将字符串中的每一个字符转换为对应的ASCII码中对应的十进制数(并不能严格这么理解),然后组成一个数组。
ASCII码一览表可参考 http://c.biancheng.net/c/ascii/
内置函数
explode将字符串转换成对应的十进制数组成的数组。内置函数
implode则与explode相反,将十进制数组成的数组转换成字符串。
我们看一下示例。
$ echo '"foobar"'|jq 'explode'
[102,111,111,98,97,114]
$ echo '[102,111,111,98,97,114]'|jq 'implode'
"foobar"
$ echo '[65, 66, 67]'|jq 'implode'
"ABC"
$ echo '"ABC"'|jq 'explode'
[65,66,67]可以看到,使用explode将字符串转换成了对应的十进制系列。而implode做的事情刚好相反。
下面我在在ASCII表中摘抄几个相关的信息放在这里。
ASCII 编码一览表
| 二进制 | 十进制 | 十六进制 | 字符 |
|---|---|---|---|
| 01000001 | 65 | 41 | A |
| 01000010 | 66 | 42 | B |
| 01000011 | 67 | 43 | C |
| 01011000 | 88 | 58 | X |
| 01011001 | 89 | 59 | Y |
| 01011010 | 90 | 5A | Z |
| 01100001 | 97 | 61 | a |
| 01100010 | 98 | 62 | b |
| 01100110 | 102 | 66 | f |
| 01101111 | 111 | 6F | o |
| 01110010 | 114 | 72 | r |
| 01111000 | 120 | 78 | x |
| 01111001 | 121 | 79 | y |
| 01111010 | 122 | 7A | z |
| 01111111 | 127 | 7F | DEL (Delete) |
可以看到,上述示例中输出的数字,刚好与各字母对应的十进制数相同。
当然,并不是所有的字符转换后,都可以在ASCII码表中查找到对应的数字。如下示例:
$ echo '"工具"'|jq 'explode'
[24037,20855]
$ echo '"工具"'|jq 'explode'|jq 'implode'
"工具"可以看到,输出的数字非常的大,而ASCII码中最大的数字是127。
实际上,对于这种不能用ASCII码表示的字符,jq会将其转换成UTF-8编码,然后再获取对应数据的十进制数。
你可以在 http://www.mytju.com/classcode/tools/encode_utf8.asp 进行中文字符串的查询。
如,我们查询"工具"这个字符串。
查询结果如下:
| 字符 | 编码10进制 | 编码16进制 | Unicode编码10进制 | Unicode编码16进制 |
|---|---|---|---|---|
| 工 | 15054757 | E5B7A5 | 24037 | 5DE5 |
| 具 | 15041975 | E585B7 | 20855 | 5177 |
我们测试一下,按照3.1.11 以ASCII码输出数据章节,我们先将汉字转换成对应的UTF-8编码格式。
$ echo '"工具"'|jq -a
"\u5de5\u5177"可以看到,其对应的UTF-8编码与上表中的”Unicode编码16进制“列的数据相同。
我们再将其转换成"Unicode编码10进制"组成的数组:
$ echo '"工具"'|jq -a 'explode'
[24037,20855]可以看到,对应的10进制数与上表中的"Unicode编码10进制"列的数据相同。
7.2.33 字符串拆分与拼接
- 内置函数
split(sep)可以将将输入流中的字符串使用sep进行分隔拆分形成数组。 - 内置函数
join(sep)可以将数组中的元素拼接在一起,并使用sep作为分隔符,最后形成一个数组。 join在拼接前,会先将数字和布尔值转换成字符串,null转成空字符串,不支持数组和对象,然后再将这些字符串进行拼接。
# 将数级中的元素用`, `拼接在一起
$ echo '["a","b,c,d","e"]'|jq 'join(", ")'
"a, b,c,d, e"
# 将数级中的元素用`, `拼接在一起,然后再使用`, `进行拆分,得到原始的输入数组了
$ echo '["a","b,c,d","e"]'|jq 'join(", ")'|jq 'split(", ")'
["a","b,c,d","e"]
# 对包含数字、布尔值和空值的元素进行拼接
$ echo '["a",1,2.3,true,null,false]'|jq 'join(", ")'
"a, 1, 2.3, true, , false"
$ echo '["a",1,2.3,true,null,false]'|jq 'join("")'
"a12.3truefalse"
$ echo '["a",1,2.3,true,null,false]'|jq 'join(" ")'
"a 1 2.3 true false"拼接连接不支持数组元素和对象元素:
$ echo '["a",1,2.3,true,null,false, {"tool": "jq"}]'|jq 'join(" ")'
jq: error (at <stdin>:1): string ("a 1 2.3 tr...) and object ({"tool":"jq"}) cannot be added
$ echo '["a",1,2.3,true,null,false, [1,2,3]]'|jq 'join(" ")'
jq: error (at <stdin>:1): string ("a 1 2.3 tr...) and array ([1,2,3]) cannot be added7.2.34 字符串大小写转换
内置函数
ascii_upcase可以将字符串转换成全大写的形式。内置函数
ascii_downcase可以将字符串转换成全小写的形式。
$ echo '"hello jq"'|jq 'ascii_upcase'
"HELLO JQ"
$ echo '"Hello JQ"'|jq 'ascii_downcase'
"hello jq"对于不包含字母的字符串,会保持原样:
$ echo '"工具"'|jq 'ascii_upcase'
"工具"
$ echo '"工具"'|jq 'ascii_downcase'
"工具"7.2.35 循环控制函数
- The
while(cond; update)function allows you to repeatedly apply an update to.untilcondis false. 循环对输入流进行处理,直到条件变成false为止。 - The
until(cond; next)function allows you to repeatedly apply the expressionnext, initially to.then to its own output, untilcondis true. 循环对输入流进行处理,直到条件变成true为止。
我们先看一下while的使用:
# .的值满足条件时,输出.的值,然后将.的值进行更新,. = . * 2
$ echo '1'|jq '[while(.<100; . * 2)]'
[1,2,4,8,16,32,64]
$ echo '1'|jq '[while(.<100; . * 3)]'
[1,3,9,27,81]
$ echo '1'|jq '[while(.<100; . * 4)]'
[1,4,16,64]
$ echo '1'|jq '[while(.<100; . * 5)]'
[1,5,25]
# .的值满足条件时,输出.的值,然后将.的值进行更新,. = . + 20
$ echo '1'|jq '[while(.<100; . + 20)]'
[1,21,41,61,81]
$ echo '1'|jq '[while(.<100; . + 30)]'
[1,31,61,91]
$ echo '1'|jq '[while(.<100; . + 40)]'
[1,41,81]可以看到,当条件cond满足要求时,如针对. < 100这个条件,输入流初时值是1,即点.对应的值是1,1<100成立,因此需要根据update定义的. * 2来更新.点对应的值,第1个循环后,.的值变成了2,并且输出变更前.的值1。再次判断. < 100是否成立,成立,又更新一次点的值,.就变成了4,此时输出变更前的值2。...。当.的值变成64时,. < 100满足条件,因此将点的值更新为128,并输出64。128 < 100不满足条件,因此不对点的值进行更新,也不输出值。
注意,并不是每次都会输出输入流的原始值:
# 输入值99 < 100 满足条件,会打印出99
$ echo '99'|jq '[while(.<100; . + 40)]'
[99]
# 输入值100 < 100 不满足条件,不会打印100,后面的数字也不会更新
$ echo '100'|jq '[while(.<100; . + 40)]'
[]
# 输入值101 < 100 不满足条件,不会打印101,后面的数字也不会更新
$ echo '101'|jq '[while(.<100; . + 40)]'
[]再来看一下until的使用:
$ echo '101'|jq '[until(.<100; . - 40)]'
[61]
$ echo '101'|jq '[until(.<100; . - 30)]'
[71]
$ echo '101'|jq '[until(.<100; . - 20)]'
[81]
$ echo '140'|jq '[until(.<100; . - 20)]'
[80]until循环是一直判断输入流的是否满足条件(如.<100),如果不满足的话,就对.的值进行更新(如. = . 20),此时并不会输出当前.的值,只到点的值不满足条件,此时才输出当前点对应的值。
再来看一下官方给的示例:
$ echo '4'|jq '[.,1]|until(.[0] < 1; [.[0] - 1, .[1] * .[0]])|.[1]'
24我们来剖析一下这个示例。
步骤如下:
1. 输入流是4
2. [.,1] 命令后,形成一个数组[4, 1]
3. cond条件是 `.[0] < 1`, 即判断数组中第一个元素的值是否小于1,现在是数组第1个元素是4,4 < 1条件不满足,那么就要更新next的值
4. next指定的值是`[.[0] - 1, .[1] * .[0]]`,即对将数组的第1个元素减1作为数组第1个元素,数组的第2个元素乘以第1个元素的值作为第2个元素,那么在第1次条件判断后,数组变成了`[4 - 1, 4 * 1]` = `[3, 4]`。
5. 再进行第二次判断 3 < 1不满足条件,则需要再次求next,next就变成了`[3 - 1, 4 * 3]` = `[2, 12]`。
6. 再进行第三次判断 2 < 1不满足条件,则需要再次求next,next就变成了`[2 - 1, 12 * 2]` = `[1, 24]`。
7. 再进行第四次判断 1 < 1不满足条件,则需要再次求next,next就变成了`[1 - 1, 24 * 1]` = `[0, 24]`。
8. 再进行第五次判断 0 < 1满足条件,不用计算next数据
因此until循环函数获取到的值是`[0, 24]`。
9,最后 `|.[1]` 需要获取数组的第2个元素,也就是24。即24是最终的结果。这个正是jq返回的结果!7.2.36 recurse 递归
recurse(f)函数允许您搜索递归结构,并从所有级别提取有趣的数据。
假设你有如下数据:
{"name": "/", "children": [
{"name": "/bin", "children": [
{"name": "/bin/ls", "children": []},
{"name": "/bin/sh", "children": []}]},
{"name": "/home", "children": [
{"name": "/home/stephen", "children": [
{"name": "/home/stephen/jq", "children": []}]}]}]}现在假设您要提取所有存在的文件名。 您需要检索 .name、.children[].name、.children[].children[].name 等。
$ echo '{"name": "/", "children": [{"name": "/bin", "children": [{"name": "/bin/ls", "children": []}, {"name": "/bin/sh", "children": []}]}, {"name": "/home", "children": [{"name": "/home/stephen", "children": [{"name": "/home/stephen/jq", "children": []}]}]}]}'|jq '.name'
"/"
$
$ echo '{"name": "/", "children": [{"name": "/bin", "children": [{"name": "/bin/ls", "children": []}, {"name": "/bin/sh", "children": []}]}, {"name": "/home", "children": [{"name": "/home/stephen", "children": [{"name": "/home/stephen/jq", "children": []}]}]}]}'|jq '.children[].name'
"/bin"
"/home"
$
$ echo '{"name": "/", "children": [{"name": "/bin", "children": [{"name": "/bin/ls", "children": []}, {"name": "/bin/sh", "children": []}]}, {"name": "/home", "children": [{"name": "/home/stephen", "children": [{"name": "/home/stephen/jq", "children": []}]}]}]}'|jq '.children[].children[].name'
"/bin/ls"
"/bin/sh"
"/home/stephen"有了recurse你可以这样做:
$ echo '{"name": "/", "children": [{"name": "/bin", "children": [{"name": "/bin/ls", "children": []}, {"name": "/bin/sh", "children": []}]}, {"name": "/home", "children": [{"name": "/home/stephen", "children": [{"name": "/home/stephen/jq", "children": []}]}]}]}'|jq 'recurse(.children[]) | .name '
"/"
"/bin"
"/bin/ls"
"/bin/sh"
"/home"
"/home/stephen"
"/home/stephen/jq"可以看到程序递归获取到各级name属性了。
- 当
recurse不带参数时,recurse等价于recurse(.[]?)。 recurse(f)与recurse(f; . != null)相同,可以在不考虑递归深度的情况下使用。recurse(f; condition)是一个生成器。
我们来看一下例子。
# 这个例子我把官方示例中最后一级的空数组中加了数字1或数字2,便于观察
# 可以看到递归函数做了以下事情:
# 第1步,最开始打印了输入流本身,输出 {"foo":[{"foo":[1]},{"foo":[{"foo":[2]}]}]}
# 第2步,取对象foo字段的值,输出 [{"foo":[1]},{"foo":[{"foo":[2]}]}]
# 第3步,上一步输出的值是包含两个对象的数组,这一步就打印出两个数组元素,是两个对象,即 {"foo":[1]} 和 {"foo":[{"foo":[2]}]}
# 观察输出可以看出,jq是先按深度进行递归处理的,即先把前面的元素处理完成,再处理后面的元素
# 因此,后面的步骤是先把`{"foo" : [1]}`这个对象处理完成后,再处理`{"foo":[{"foo":[2]}`对象
# 第4步,处理`{"foo" : [1]}`对象,打印其值,并输出foo字段的值[1],然后再输出1。1已经是最内层的数据了,说明这个对象处理完成了。
# 第5步,处理`{"foo":[{"foo":[2]}]}`对象,打印其值,并输出foo字段的值[{"foo":[2]}],然后再输出数组中的元素{"foo":[2]},然后对输出对象中foo字段的值[2],最后输出数组中的元素2。 这个对象的所有层的数据都处理完成。
$ echo '{"foo":[{"foo": [1]}, {"foo":[{"foo":[2]}]}]}'|jq 'recurse'
{"foo":[{"foo":[1]},{"foo":[{"foo":[2]}]}]}
[{"foo":[1]},{"foo":[{"foo":[2]}]}]
{"foo":[1]}
[1]
1
{"foo":[{"foo":[2]}]}
[{"foo":[2]}]
{"foo":[2]}
[2]
2可以看到,程序会不断递归向下,获取对象或数组的值,并按深度优先的方式向更深层的数据进行处理。
看手册上简单的例子:
$ echo '{"foo":[{"foo": []}, {"foo":[{"foo":[]}]}]}'|jq 'recurse(.foo[])'
{"foo":[{"foo":[]},{"foo":[{"foo":[]}]}]}
{"foo":[]}
{"foo":[{"foo":[]}]}
{"foo":[]}
$ echo '{"a":0,"b":[1]}'|jq 'recurse'
{"a":0,"b":[1]}
0
[1]
1
$ echo '2'|jq 'recurse(. * .; . < 20)'
2
4
167.2.37 walk遍历
walk会递归处理输入流的每个元素。
看一下示例:
# 如果子元素是列表,则对列表中的元素进行排序,是其他类型的话,则原样输出
$ echo '[[4, 1, 7], [8, 5, 2], {"tool": "JQ"}, [3, 6, 9]]'|jq 'walk(if type == "array" then sort else . end)'
[[1,4,7],[2,5,8],[3,6,9],{"tool":"JQ"}]
# 首先判断子元素是否为object对象,是对象的话,就使用with_entries( .key |= sub( "^_+"; "") )将对象的键名进行替换,如果键名是以多个下划线_开头,则把下划线去掉;否则就什么也不做,直接输出对象。
$ echo '[ { "_a": { "__b": 2 } } ]'|jq 'walk( if type == "object" then with_entries( .key |= sub( "^_+"; "") ) else . end )'
[{"a":{"b":2}}]
$ echo '[ { "_a": { "__b": 2 } }, {"tool": "JQ"} ]'|jq 'walk( if type == "object" then with_entries( .key |= sub( "^_+"; "") ) else . end )'
[{"a":{"b":2}},{"tool":"JQ"}]注意:
此处的
with_entries参考"7.2.7 to_entries 对象转换成健值对组成的列表"小节。此处的
sub函数是一个正则替换函数。后面会讲。
此处简单给出一个示例:
$ echo '"__JQ"'|jq 'sub("^_+"; "This is ")'
"This is JQ"可以看到,sub会将所有匹配的字符串__一起替换成新值This is 。
7.2.38 $ENV,env环境变量
$ENV是一个对象,表示 jq 程序启动时设置的环境变量。env输出一个代表 jq 当前环境的对象。- 目前没有用于设置环境变量的内置函数。
获取所有的环境变量:
$ echo 'null'|jq '$ENV'
{
"SHELL": "/bin/bash",
"HISTSIZE": "3000",
"SSH_TTY": "/dev/pts/0",
"USER": "meizhaohui",
"JQ_COLORS": "1;31:7;31:1;32:0;37:0;32:1;33:1;37",
"LANG": "en_US.UTF-8",
"_": "/usr/bin/jq"
}
$
$ echo 'null'|jq 'env'
{
"SHELL": "/bin/bash",
"HISTSIZE": "3000",
"SSH_TTY": "/dev/pts/0",
"USER": "meizhaohui",
"JQ_COLORS": "1;31:7;31:1;32:0;37:0;32:1;33:1;37",
"LANG": "en_US.UTF-8",
"_": "/usr/bin/jq"
}获取单个环境变量:
$ echo 'null'|jq '$ENV.JQ_COLORS'
"1;31:7;31:1;32:0;37:0;32:1;33:1;37"
$ echo 'null'|jq 'env.JQ_COLORS'
"1;31:7;31:1;32:0;37:0;32:1;33:1;37"7.2.39 transpose转置
矩阵转置:
例如:矩阵
的转置矩阵就是
例如:矩阵
的转置矩阵就是
- 转置可能是锯齿状的矩阵(数组的数组)。 行用
null空值填充,因此结果始终为矩形。
$ echo '[[1], [2,3]]'|jq 'transpose'
[[1,2],[null,3]]
$ echo '[[1,0], [2,3]]'|jq 'transpose'
[[1,2],[0,3]]
$ echo '[[2,4], [1,3]]'|jq 'transpose'
[[2,1],[4,3]]
$ echo '[[1,2,3], [4,5,6]]'|jq 'transpose'
[[1,4],[2,5],[3,6]]7.2.40 bsearch(x)二分搜索
bsearch(x)对输入数组中的x进行二分搜索。 如果输入已排序并包含x,则bsearch(x)将返回其在数组中的索引; 否则,如果数组已排序,它将返回 (-1 - ix),其中ix是一个插入点,这样在ix处插入x后,数组仍将被排序。 如果数组未排序,bsearch(x)将返回一个可能不感兴趣的整数。
对于已经排序好的数组,如果在数组中查找到x,则返回x对应的索引值:
$ echo '[1,3,5,8]'|jq 'bsearch(1)'
0
$ echo '[1,3,5,8]'|jq 'bsearch(3)'
1
$ echo '[1,3,5,8]'|jq 'bsearch(5)'
2
$ echo '[1,3,5,8]'|jq 'bsearch(8)'
3对于已经排序好的数组,如果在数组中查找不到x:
# 在数组中找不到0,0应插入在插入点数字1的前面,1的索引是0,按说明,则返回 -1 - 0 = -1
$ echo '[1,3,5,8]'|jq 'bsearch(0)'
-1
# 在数组中找不到2,2应插入在插入点数字3的前面,3的索引是1,按说明,则返回 -1 - 1 = -2
$ echo '[1,3,5,8]'|jq 'bsearch(2)'
-2
# 在数组中找不到4,3应插入在插入点数字5的前面,5的索引是2,按说明,则返回 -1 - 2 = -3
$ echo '[1,3,5,8]'|jq 'bsearch(4)'
-3
# 在数组中找不到6,6应插入在插入点数字8的前面,8的索引是3,按说明,则返回 -1 - 3 = -4
$ echo '[1,3,5,8]'|jq 'bsearch(6)'
-4
# 在数组中找不到7,7应插入在插入点数字8的前面,8的索引是3,按说明,则返回 -1 - 3 = -4
$ echo '[1,3,5,8]'|jq 'bsearch(7)'
-4
# 在数组中找不到9,9应插入在插入点数字8的后面,8后面的数字索引应该是4,按说明,则返回 -1 - 4 = -5
$ echo '[1,3,5,8]'|jq 'bsearch(9)'
-5
# 在数组中找不到10,10应插入在插入点数字8的后面,8后面的数字索引应该是4,按说明,则返回 -1 - 4 = -5
$ echo '[1,3,5,8]'|jq 'bsearch(10)'
-5
# 在数组中找不到11,11应插入在插入点数字8的后面,8后面的数字索引应该是4,按说明,则返回 -1 - 4 = -5
$ echo '[1,3,5,8]'|jq 'bsearch(11)'
-5未排序的数组进行二分搜索:
$ echo '[1,5,3,8]'|jq 'bsearch(1)'
0
$ echo '[1,5,3,8]'|jq 'bsearch(5)'
1
$ echo '[1,5,3,8]'|jq 'bsearch(3)'
-2
$ echo '[1,5,3,8]'|jq 'bsearch(8)'
3
$ echo '[1,5,3,8]'|jq 'bsearch(4)'
-2
$ echo '[1,5,3,8]'|jq 'bsearch(6)'
-4此时结果没多大意义。因此使用bsearch前,应对数组进行排序。
$ echo '[1,5,3,8]'|jq 'sort'
[1,3,5,8]
$ echo '[1,5,3,8]'|jq 'sort'|jq 'bsearch(1)'
0
$ echo '[1,5,3,8]'|jq 'sort'|jq 'bsearch(5)'
2
$ echo '[1,5,3,8]'|jq 'sort'|jq 'bsearch(3)'
1
$ echo '[1,5,3,8]'|jq 'sort'|jq 'bsearch(8)'
3
$ echo '[1,5,3,8]'|jq 'sort'|jq 'bsearch(4)'
-3
$ echo '[1,5,3,8]'|jq 'sort'|jq 'bsearch(6)'
-4如果数组是逆序的,也认为是没有排序的:
# 逆序时,未能找到
$ echo '[3,2,1]'|jq 'bsearch(3)'
-4
$ echo '[3,2,1]'|jq 'bsearch(2)'
1
$ echo '[3,2,1]'|jq 'bsearch(1)'
-1
# 排序后正常找到
$ echo '[3,2,1]'|jq 'sort|bsearch(1)'
0
$ echo '[3,2,1]'|jq 'sort|bsearch(2)'
1
$ echo '[3,2,1]'|jq 'sort|bsearch(3)'
2可以看到, 此时不能正常的找到数据。
7.2.41 字符串插值
- 在字符串中,您可以在反斜杠后的括号中放置表达式。 无论表达式返回什么,都将被插入到字符串中。
$ echo '42'|jq '"The input was \(.), which is one less than \(.+1)"'
"The input was 42, which is one less than 43"
$ echo '{"tool":"JQ"}'|jq '"The input was \(.), the tool is \(.tool)"'
"The input was {\"tool\":\"JQ\"}, the tool is JQ"7.2.42 tojson/fromjson 将数据转为JSON
tojson将数据转为JSON数据。fromjson将JSON数据转换成值。tojson与tostring是不同的。
$ echo '[1, "foo", ["foo"]]'|jq '[.[]|tostring]'
["1","foo","[\"foo\"]"]
$ echo '[1, "foo", ["foo"]]'|jq '[.[]|tojson]'
["1","\"foo\"","[\"foo\"]"]
$ echo '[1, "foo", ["foo"]]'|jq '[.[]|tojson|fromjson]'
[1,"foo",["foo"]]7.2.43 格式化字符串和转义
@foo语法用于格式化和转义字符串,这对于构建 URL、使用 HTML 或 XML 等语言的文档等很有用。 @foo 可以单独用作过滤器,可能的转义有:
@text: 调用tostring函数,返回字符串。@json:将输入序列化为JSON。@html: 应用HTML转义,对<>&'"进行转义。@uri: 通过将所有保留的 URI 字符映射到 %XX 序列来应用百分比编码。@csv:将输入数组转换成CSV字符串。@tsv:将输入数组转换成以TAB分隔的字符串数据。@base64:将字符串转为base64编码。@base64d:base64编码解码。
示例:
# 将JSON欢乐时光转换成文本
$ echo '{"tool": "jq"}'|jq '@text'
"{\"tool\":\"jq\"}"
$ echo '{"tool": "jq"}'|jq '@json'
"{\"tool\":\"jq\"}"
# uri转换
$ echo '{"search":"what is jq?"}'|jq '@uri "https://www.google.com/search?q=\(.search)"'
"https://www.google.com/search?q=what%20is%20jq%3F"
# 将HTML特殊符号进行转义
$ echo '"<head><body>HTML Body</body></body>"'|jq '@html'
"<head><body>HTML Body</body></body>"
# base64编码和解码
$ echo '"This is a message"'|jq '@base64'
"VGhpcyBpcyBhIG1lc3NhZ2U="
$ echo '"This is a message"'|jq '@base64'|jq '@base64d'
"This is a message"
# 将数组转换为字符串
$ echo '[[1,2,3],[4,5,6],[7,8,9]]'|jq '.[]|@csv'
"1,2,3"
"4,5,6"
"7,8,9"
$ echo '[[1,2,3],[4,5,6],[7,8,9]]'|jq '.[]|@tsv'
"1\t2\t3"
"4\t5\t6"
"7\t8\t9"7.2.44 Dates日期相关
jq 提供了一些基本的日期处理功能,以及一些高级和低级的内置函数。在所有情况下,这些内置函数都专门处理 UTC 时间。
fromdateiso8601内置函数将 ISO 8601 格式的日期时间解析为自 Unix 纪元 (1970-01-01T00:00:00Z) 以来的秒数。todateiso8601内置函数则相反,将秒数转换成ISO 8601格式的日期时间。todate是todateiso8601的别名。fromdate内置函数解析日期时间字符串。目前fromdate仅支持 ISO 8601 日期时间字符串,但未来它将尝试解析更多格式的日期时间字符串。now内置函数会输出从Unix纪元时间到现在的秒数。
还有一些C库时间函数的低级jq接口。
gmtime输出时间格式组成的数组,按以下顺序排列:年、月(从零开始)、日月份(从一开始)、一天中的小时、一小时中的一分钟、一分钟中的秒、一周中的某天和一年中的某天——除非另有说明,否则都是基于一的。对于 1900 年 3 月 1 日之前或 2099 年 12 月 31 日之后的日期,某些系统上的星期几可能是错误的。localtime类似于gmtime,但使用的是本地时间设置。strptime(fmt)内置函数解析与fmt参数匹配的输入字符串,输出时间数组。strftime(fmt)内置函数使用给定格式格式化时间 (GMT)。
# 获取从纪元时间到当前时间的秒数
$ echo 'null'|jq 'now'
1631229668.32639
# 将秒数时间转换成以指定格式化时间输出
$ echo 'null'|jq 'now'|jq 'strftime("%Y-%m-%dT%H:%M:%SZ")'
"2021-09-09T23:21:54Z"
# 将时间字符串解析成时间数组
# 注意月份是从0开始算的,输出数组中第2个元素8表示9月,并且是按UTC时间输出的
$ echo '"2021-09-09T23:21:54Z"'|jq 'strptime("%Y-%m-%dT%H:%M:%SZ")'
[2021,8,9,23,21,54,4,251]
# 将时间秒数转换成ISO 8601格式时间字符串
# 可以看到,小数部分的秒数据被忽略掉
$ echo '1631229668.32639'|jq 'todate'
"2021-09-09T23:21:08Z"
# 将时间秒数转换成ISO 8601格式时间字符串
$ echo '1631229668.32639'|jq 'todateiso8601'
"2021-09-09T23:21:08Z"
# 将ISO格式时间字符串转换成时间秒数
# 可以看到,小数部分的秒数据被忽略掉
$ echo '1631229668.32639'|jq 'todateiso8601'|jq 'fromdateiso8601'
1631229668
# 获取UTC时区的时间数组
# 注意月份是从0开始算的,输出数组中第2个元素8表示9月,并且是按UTC时间输出的
$ echo 'null'|jq 'now|gmtime'
[2021,8,9,23,32,6.525592088699341,4,251]
# 获取北京时区的时间数组
# 注意月份是从0开始算的,输出数组中第2个元素8表示9月,并且是按UTC时间输出的
# 北京时间比UTC时间快8小时间
# 现在是 2021-09-10 07时32分14.26秒,今天是周五,是一年中的252天
$ echo 'null'|jq 'now|localtime'
[2021,8,10,7,32,14.263200044631958,5,252]
# 生成北京时间的字符串,你可以使用这个当`date`命令行使用
$ echo 'null'|jq 'now|localtime|strftime("%Y-%m-%d %H:%M:%S")'
"2021-09-10 07:38:33"
$ echo 'null'|jq 'now|localtime|strftime("%Y-%m-%d %H:%M:%S")'
"2021-09-10 07:38:35"
$ echo 'null'|jq 'now|localtime|strftime("%Y-%m-%d %H:%M:%S")'
"2021-09-10 07:38:38"7.2.45 builtins获取内置函数数组
builtins可以获取jq的所有内置函数的数组。由于具有相同名称但不同参数的函数被视为单独的函数,因此all/0、all/1和all/2都将出现在列表中。
# 输出排序后的内置函数数组信息
$ echo 'null'|jq 'builtins|sort'
["IN/1","IN/2","INDEX/1","INDEX/2","JOIN/2","JOIN/3","JOIN/4","acos/0","acosh/0","add/0","all/0","all/1","all/2","any/0","any/1","any/2","arrays/0","ascii_downcase/0","ascii_upcase/0","asin/0","asinh/0","atan/0","atan2/2","atanh/0","booleans/0","bsearch/1","builtins/0","capture/1","capture/2","cbrt/0","ceil/0","combinations/0","combinations/1","contains/1","copysign/2","cos/0","cosh/0","debug/0","del/1","delpaths/1","drem/2","empty/0","endswith/1","env/0","erf/0","erfc/0","error/0","error/1","exp/0","exp10/0","exp2/0","explode/0","expm1/0","fabs/0","fdim/2","finites/0","first/0","first/1","flatten/0","flatten/1","floor/0","fma/3","fmax/2","fmin/2","fmod/2","format/1","frexp/0","from_entries/0","fromdate/0","fromdateiso8601/0","fromjson/0","fromstream/1","gamma/0","get_jq_origin/0","get_prog_origin/0","get_search_list/0","getpath/1","gmtime/0","group_by/1","gsub/2","gsub/3","halt/0","halt_error/0","halt_error/1","has/1","hypot/2","implode/0","in/1","index/1","indices/1","infinite/0","input/0","input_filename/0","input_line_number/0","inputs/0","inside/1","isempty/1","isfinite/0","isinfinite/0","isnan/0","isnormal/0","iterables/0","j0/0","j1/0","jn/2","join/1","keys/0","keys_unsorted/0","last/0","last/1","ldexp/2","leaf_paths/0","length/0","lgamma/0","lgamma_r/0","limit/2","localtime/0","log/0","log10/0","log1p/0","log2/0","logb/0","ltrimstr/1","map/1","map_values/1","match/1","match/2","max/0","max_by/1","min/0","min_by/1","mktime/0","modf/0","modulemeta/0","nan/0","nearbyint/0","nextafter/2","nexttoward/2","normals/0","not/0","now/0","nth/1","nth/2","nulls/0","numbers/0","objects/0","path/1","paths/0","paths/1","pow/2","pow10/0","range/1","range/2","range/3","recurse/0","recurse/1","recurse/2","recurse_down/0","remainder/2","repeat/1","reverse/0","rindex/1","rint/0","round/0","rtrimstr/1","scalars/0","scalars_or_empty/0","scalb/2","scalbln/2","scan/1","select/1","setpath/2","significand/0","sin/0","sinh/0","sort/0","sort_by/1","split/1","split/2","splits/1","splits/2","sqrt/0","startswith/1","stderr/0","strflocaltime/1","strftime/1","strings/0","strptime/1","sub/2","sub/3","tan/0","tanh/0","test/1","test/2","tgamma/0","to_entries/0","todate/0","todateiso8601/0","tojson/0","tonumber/0","tostream/0","tostring/0","transpose/0","trunc/0","truncate_stream/1","type/0","unique/0","unique_by/1","until/2","utf8bytelength/0","values/0","walk/1","while/2","with_entries/1","y0/0","y1/0","yn/2"]
# 计算数组中有多少个元素
$ echo 'null'|jq 'builtins|sort|length'
217可以看到,jq的内置函数多达217个!!!
8. 条件与比较
Conditionals and Comparisons是条件与比较。
8.1 比较
8.1.1 等与不等
- 使用
==判断两个值是否相等。 - 使用
!=判断两个值是否不相等。 ==类似于JavaScript中的===,只有当数据类型相同,并且值相等时才认为它们相等。
看下面的示例:
$ echo '[1, 1.0, "1", "banana"]'|jq '.[] == 1'
true
true
false
false可以看到,数字1与1相等,同样1.0也与1相等,但字符串1与1不相等。同样字符串banana与数字1也不相等。
8.1.2 大于小于
>, >=, <=, <大于、大于等于、小于等于、小于。- 进行判断时,按
sort函数排序方式进行判断。参考:7.2.22 sort数组排序小节。
$ echo '[1, 1.0, "1", "banana"]'|jq '.[] < 1'
false
false
false
false
$ echo '[1, 1.0, "1", "banana"]'|jq '.[] > 1'
false
false
true
true
$ echo '[1, 1.0, "1", "banana"]'|jq '.[] >= 1'
true
true
true
true
$ echo '[1, 1.0, "1", "banana"]'|jq '.[] <= 1'
true
true
false
false8.2 条件语句
8.2.1 if条件语法
if A then B else C endwill act the same asBifAproduces a value other than false or null, but act the same asCotherwise.Checking for false or null is a simpler notion of "truthiness" than is found in Javascript or Python, but it means that you'll sometimes have to be more explicit about the condition you want: you can't test whether, e.g. a string is empty using
if .name then A else B end, you'll need something more likeif (.name | length) > 0 then A else B endinstead.If the condition
Aproduces multiple results, thenBis evaluated once for each result that is not false or null, andCis evaluated once for each false or null.More cases can be added to an if using
elif A then Bsyntax.
if A then B else C end语句的意思是,如果A产生的值是真的(非false,也不是null)时,则执行B,否则执行C。- 不能直接测试是否,例如,你要判断一个字符串为空,你不能用
if .name then A else B end来判断非空,而应像下面这样if (.name | length) > 0 then A else B end来判断。 - 你也可以使用
elif A then B语法。 - 在jq中认为false和null是假,empty不是真也不是假,其他的都是真。
# 同时使用if/elif/else的情况
$ echo '[0,1,2,3]'|jq '.[]|if . == 0 then "zero" elif . == 1 then "one" else "other" end'
"zero"
"one"
"other"
"other"
# 将结果转换成数组
$ echo '[0,1,2,3]'|jq '[.[]|if . == 0 then "zero" elif . == 1 then "one" else "other" end]'
["zero","one","other","other"]下面来验证一下,判断字符串为空的情况:
$ echo '{"name": "JQ"}'|jq 'if .name then "not empty" else "empty" end'
"not empty"
$ echo '{"name": ""}'|jq 'if .name then "not empty" else "empty" end'
"not empty"此时,可以发现,就算我们对象的键name对应的值为空字符串时,这种方式判断也输出了not empty非空,说明判断异常。
应该使用下面这种方式判断:
$ echo '{"name": "JQ"}'|jq 'if (.name | length ) > 0 then "not empty" else "empty" end'
"not empty"
$ echo '{"name": ""}'|jq 'if (.name | length ) > 0 then "not empty" else "empty" end'
"empty"这样通过字符串的长度值可以正常判断字符串是否非空。
我们可以在jq源码的tests/jq.test文件中找到更多的测试用例,其中就有if语句相关的测试用例。我们试试看。
$ sed -n '1069,1106p' jq.test
# Conditionals
#
[.[] | if .foo then "yep" else "nope" end]
[{"foo":0},{"foo":1},{"foo":[]},{"foo":true},{"foo":false},{"foo":null},{"foo":"foo"},{}]
["yep","yep","yep","yep","nope","nope","yep","nope"]
[.[] | if .baz then "strange" elif .foo then "yep" else "nope" end]
[{"foo":0},{"foo":1},{"foo":[]},{"foo":true},{"foo":false},{"foo":null},{"foo":"foo"},{}]
["yep","yep","yep","yep","nope","nope","yep","nope"]
[if 1,null,2 then 3 else 4 end]
null
[3,4,3]
[if empty then 3 else 4 end]
null
[]
[if 1 then 3,4 else 5 end]
null
[3,4]
[if null then 3 else 5,6 end]
null
[5,6]
[if true then 3 end]
7
[3]
[if false then 3 end]
7
[7]
[if false then 3 else . end]
7
[7]我们来测试一下:
# 可以盾到,在if条件中,会对每一个项(如1,null,2)分别判断是否是真的,1和2是真,而null是假,因此1和2对应输出的是3,null对应输出4
$ echo 'null'|jq '[if 1,null,2 then 3 else 4 end]'
[3,4,3]
# 由于empty不返回任何东西,也不返回null,因此,其既不是真也不是假
$ echo 'null'|jq 'empty'
# 因此不会输出3也不会输出4,最后是一个空数组
$ echo 'null'|jq '[if empty then 3 else 4 end]'
[]
# 由于1永远是真,所有if语句返回3,4,然后形成数组,就是[3, 4]
$ echo 'null'|jq '[if 1 then 3,4 else 5 end]'
[3,4]
# 在JQ中0也认为是真的,因此也会输出数组[3, 4]
# 在jq中认为false和null是假,empty不是真也不是假,其他的都是真
$ echo 'null'|jq '[if 0 then 3,4 else 5 end]'
[3,4]
# null空为假,那么会执行else后的语句,因此if输出5,6,最后形成数组[5,6]
$ echo 'null'|jq '[if null then 3 else 5,6 end]'
[5,6]
# 当if语句中没有else部分的时候,jq会报异常!!!
$ echo '7'|jq '[if true then 3 end]'
jq: error: syntax error, unexpected end (Unix shell quoting issues?) at <top-level>, line 1:
[if true then 3 end]
jq: error: Possibly unterminated 'if' statement at <top-level>, line 1:
[if true then 3 end]
jq: 2 compile errors
$ echo '7'|jq '[if false then 3 end]'
jq: error: syntax error, unexpected end (Unix shell quoting issues?) at <top-level>, line 1:
[if false then 3 end]
jq: error: Possibly unterminated 'if' statement at <top-level>, line 1:
[if false then 3 end]
jq: 2 compile errors
$ echo '7'|jq '[if false then 3 else . end]'
[7]可以看到if语句中如果没有else部分,被认为是一个异常的语句。
再看测试用例中稍微复杂的例子:
# 如果输入数组中元素对象的foo键的值是真的话,则输出`yep`,否则输出为`nope`
# {"foo":false},{"foo":null}和{}三个对象的foo键对应的值都是假的,因此会输出`nope`
$ echo '[{"foo":0},{"foo":1},{"foo":[]},{"foo":true},{"foo":false},{"foo":null},{"foo":"foo"},{}]'|jq '[.[] | if .foo then "yep" else "nope" end]'
["yep","yep","yep","yep","nope","nope","yep","nope"]
# 此例中,当数组中元素对象的baz字段为真进输出strange,或者元素对象的foo键的值是真的话,则输出`yep`,其他情况则输出为`nope`
$ echo '[{"foo":0},{"foo":1},{"foo":[]},{"foo":true},{"foo":false},{"foo":null},{"foo":"foo"},{}]'|jq '[.[] | if .baz then "strange" elif .foo then "yep" else "nope" end]'
["yep","yep","yep","yep","nope","nope","yep","nope"]
# 我们弄一个实际有baz键的示例
# 可以看到strange能够正常显示出来
$ echo '[{"baz":0},{"foo":1},{"baz":[]},{"foo":true},{"foo":false},{"foo":null},{"foo":"foo"},{}]'|jq '[.[] | if .baz then "strange" elif .foo then "yep" else "nope" end]'
["strange","yep","strange","yep","nope","nope","yep","nope"]
# if求阶乘,使用了递归函数fac
# fac(n) = (n-1)fac(n-1)
$ echo '[1,2,3,4]'|jq 'def fac: if . == 1 then 1 else . * (. - 1 | fac) end; [.[] | fac]'
[1,2,6,24]8.3 其他
8.3.1 布尔运算符
jq支持and,or,not等布尔运算符。false和null认为是假,其他都是真。- 如果操作数产生多个结果,则运算符将会与每个输入产生一个结果。
not实际上是一个内置函数而不是一个操作符,可以通过过滤器管道使用。如.foo|not。- 这三个值仅会产生
true或false。
注意一点,只有null和false才认为是假的,其他都是真的!!!
$ echo 'null'|jq '42 and "a string"'
true
$ echo 'null'|jq '42 and "0"'
true
$ echo 'null'|jq '0 and "0"'
true
$ echo 'null'|jq '0 and null'
false
$ echo 'null'|jq '0 or null'
true
$ echo 'null'|jq '(true, false) or false'
true
false
$ echo 'null'|jq '(true, true) and (true, false)'
true
false
true
false
$ echo 'null'|jq '[true, false | not]'
[false,true]
$ echo 'null'|jq '[(true, false) | not]'
[false,true]8.3.2 替代运算符
//是替代运算符。a//b的意思是,如果a的值是真的,则输出a; 如果a的值是假的,则用b替代,输出b的值。- 这对于给
.foo提供默认值比较有用。
# 对象中存在`foo`键,对应的值19是真值,因此.foo // 42 会输出19
$ echo '{"foo": 19}'|jq '.foo // 42'
19
# 对象中不存在`foo`键,.foo输出是`null`空,因此.foo // 42 会输出替代值42,因此输出42
$ echo '{}'|jq '.foo // 42'
42
$ echo '{}'|jq '.foo'
null
# 就算对象的`foo`键存在,但其值是`null`或`false`,值是假的,因此最后输出的值也会使用替代值42进行替换。
$ echo '{"foo": false}'|jq '.foo // 42'
42
$ echo '{"foo": null}'|jq '.foo // 42'
42
# 空字符串`""`是真的,不会被替换掉,因此最后输出空
$ echo '{"foo": ""}'|jq '.foo // 42'
""8.3.3 异常捕获try..catch
- 错误可以通过使用
try EXP catch EXP来捕获。 如果执行第一个表达式失败,则执行第二个表达式并显示错误消息。 try EXP使用空作为异常处理程序,即异常了不输出任何东西。
# 直接尝试在输入流中找a键,抛出异常,并且退出码是5
$ echo 'true'|jq '.a'
jq: error (at <stdin>:1): Cannot index boolean with string "a"
$ echo $?
5
# 当使用try .. catch捕获异常后,执行了catch后面的语句,显示了后面的字符串,并且退出码是0,正常退出
$ echo 'true'|jq 'try .a catch ". is not an object"'
". is not an object"
$ echo $?
0
# try对数组每个元素进行处理,由于没有catch后面的部分,只会显示没有异常的元素的结果
# {}空对象的.a是null空,{"a":1}的.a是1,而true的.a会抛出异常,不会显示
# 此时整体的退出码是0
$ echo '[{}, true, {"a":1}]'|jq '[.[]|try .a]'
[null,1]
$ echo $?
0
# true是没有a键的,抛出异常
$ echo '[{}, true, {"a":1}]'|jq '[.[]|.a]'
jq: error (at <stdin>:1): Cannot index boolean with string "a"
$ echo $?
5
# 捕获自定义异常
$ echo 'null'|jq 'try error("some exception") catch .'
"some exception"
$ echo $?
08.3.4 跳出控制语句
try/catch的一个方便用途是打破像reduce、foreach、while等控制结构。- JQ中有一个命名语法标签的语法,用于中断或跳转。语法如下
label $out | ... break $out ... - 中断实际效果像左侧的标签输出为
empty一样。 - 中断和相应标签之间的关系是词法上的:标签必须从中断处“可见”。
- 打破
reduce可以这样label $out | reduce .[] as $item (null; if .==false then break $out else ... end)。
我们看一下测试用例中的示例:
# 当数组中的元素大于1时,就跳出if判断语句,不执行后续元素的if判断操作
# 最后"hi!"表示执行完前面的过滤器后,应在数组中加上一个元素"hi!"
$ echo '[0,1,2]'|jq '[(label $here | .[] | if .>1 then break $here else . end), "hi!"]'
[0,1,"hi!"]
$ echo '[0,1,2]'|jq '[(label $here | .[] | if .>1 then break $here else . end)]'
[0,1]
# 由于第2个元素2应满足大于1的要求,执行break $here退出操作
# 后面的第3个元素1直接不会再进行判断,直接忽略掉
$ echo '[0,2,1]'|jq '[(label $here | .[] | if .>1 then break $here else . end), "hi!"]'
[0,"hi!"]
$ echo '[0,2,1]'|jq '[(label $here | .[] | if .>1 then break $here else . end)]'
[0]8.3.5 错误抑制/可选运算符
?可以进行错误抑制。如EXP?,是try EXP的简化形式。
# 不使用错误抑制,抛出异常
$ echo '[{}, true, {"a":1}]'|jq '[.[]|.a]'
jq: error (at <stdin>:1): Cannot index boolean with string "a"
# 使用错误抑制,就是布尔值没有键a也不会报错
$ echo '[{}, true, {"a":1}]'|jq '[.[]|.a?]'
[null,1]
$ echo '[{}, true, {"a":1}]'|jq '[.[]|(.a)?]'
[null,1]
# 使用异常捕获,也不会抛出异常
$ echo '[{}, true, {"a":1}]'|jq '[.[]|try .a]'
[null,1]9 正则表达式PCRE
- jq 使用 Oniguruma 正则表达式库,php、ruby、TextMate、Sublime Text 等也是如此,所以这里的描述将集中在 jq 的细节上。
可以按如下方式定义过滤器的模式来使用正则表达式:
STRING | FILTER( REGEX )
STRING | FILTER( REGEX; FLAGS )
STRING | FILTER( [REGEX] )
STRING | FILTER( [REGEX, FLAGS] )STRING、FILTER、REGEX是jq字符串,并受字符串插值的影响。REGEX在字符串插值后,REGEX应该是一个有效的PCRE表达式。FILTER过滤器则是下面定义的像test、match、capture等关键字之一。FLAGS表示标志,支持以下标志开关。g全局搜索,不仅仅匹配第一个。i大小写不敏感。m多行模式搜索,'.' 将匹配换行符。s单行模式,('^' -> '\A', '$' -> '\Z')。n忽略空匹配。p表示s和m都开启,即同时开启单行模式和多行模式。l查找最长的匹配。x扩展正则表达式格式,忽略空格和注释。要匹配此模式下的空格,请使用转义\s,如test( "a\sb", "x" )。
此处不详细介绍正则表达式怎么使用。 正则表达式 - 语法 可参考菜鸟教程上面的这篇教程 正则表达式 - 语法 。
9.1 test测试是否匹配
test关键字语法如下:test(val)或test(regex; flags)。test类似于match,但不返回匹配对象,只返回true或false。
# 先匹配`fo`字符,再匹配0次或1次字符`o`
$ echo '"fo"'|jq 'test("foo?")'
true
# 先匹配`fo`字符,再匹配1次或多次字符`o`
$ echo '"fo"'|jq 'test("foo+")'
false
# 先匹配`fo`字符,再匹配0次或多次字符`o`
$ echo '"fo"'|jq 'test("foo*")'
true
# 先匹配`fo`字符,再匹配1次字符`o`
$ echo '"fo"'|jq 'test("foo")'
false
# 使用扩展模式(x),并忽略大小写(i)进行匹配字符`aBc`,只要能够匹配上就返回true,匹配不上则返回false
$ echo '["xabcd", "ABC"]'|jq '.[] | test("a B c # spaces are ignored"; "ix")'
true
true虽然test可以测试出正则是否匹配上,但我们不能知道到底哪里匹配上了。
9.2 capture捕获组
由于match匹配中涉及到captures捕获组的概念,因此此处先测试capture的使用。
capture的语法capture(val)或capture(regex; flags)。- 将命名的捕获收集到一个 JSON 对象中,以每个捕获的名称作为键,匹配的字符串作为对应的值。
# 匹配小写字母组成的字符串放在键a中,匹配数字组成的字符串放在键n中
$ echo '"xyzzy-14"'|jq 'capture("(?<a>[a-z]+)-(?<n>[0-9]+)")'
{"a":"xyzzy","n":"14"}
# 匹配类似配置文件中键值对,获取到相应的option键的值为name,value键的值为JQ
$ echo '"name=JQ"'|jq 'capture("(?<option>[a-z]+)=(?<value>[A-Z]+)")'
{"option":"name","value":"JQ"}
# 使用捕获组进行匹配后,可以方便对捕获到数据进行再处理
# 如下直接读取到了对应的捕获组的信息
$ echo '"name=JQ"'|jq 'capture("(?<option>[a-z]+)=(?<value>[A-Z]+)")|.option'
"name"
$ echo '"name=JQ"'|jq 'capture("(?<option>[a-z]+)=(?<value>[A-Z]+)")|.value'
"JQ"9.3 match显示匹配对象
match匹配时,会返回匹配对象,匹配对象中的关键字意义如下:offset- UTF-8 代码点中从输入开始的偏移量length- 匹配的 UTF-8 代码点长度string- 匹配的字符串captures- 表示捕获组的对象数组。
捕获组对象具有以下字段:
offset- UTF-8 代码点中从输入开始的偏移量length- 此捕获组的 UTF-8 代码点长度string- 被捕获的字符串name- 捕获组的名称(如果未命名,则为null)
# 不区分大小写匹配一次或多次`abc`字符串,因为没有加`g`全局搜索开关,仅匹配到开头位置的`abc`就停止匹配了。
$ echo '"abc Abc"'|jq 'match("(abc)+"; "i")'
{"offset":0,"length":3,"string":"abc","captures":[{"offset":0,"length":3,"string":"abc","name":null}]}
# 不区分大小写匹配一次或多次`abc`字符串,`g`全局搜索开关开启,会进行多次匹配
# 所以会匹配到位置0-2处`abc`,以及位置`4-6`处的`Abc`
$ echo '"abc Abc"'|jq 'match("(abc)+"; "gi")'
{"offset":0,"length":3,"string":"abc","captures":[{"offset":0,"length":3,"string":"abc","name":null}]}
{"offset":4,"length":3,"string":"Abc","captures":[{"offset":4,"length":3,"string":"Abc","name":null}]}
# 区分大小写匹配字符串`foo`,并且只匹配第一次后就不再继续匹配
# 仅匹配到开头处的字符串`foo`,由于匹配正则中没有使用`()`进行分组,`captures`将是一个空的数组。
$ echo '"foo bar foo"'|jq 'match("foo")'
{"offset":0,"length":3,"string":"foo","captures":[]}
# 区分大小写匹配字符串`foo`,开启`g`全局搜索开关,因此在匹配第一次后,还会继续匹配
# 因此先匹配到开头处的字符串`foo`,由于匹配正则中没有使用`()`进行分组,`captures`将是一个空的数组。
# 再匹配到结尾处的字符串`FOO`,由于匹配正则中没有使用`()`进行分组,`captures`将是一个空的数组。
$ echo '"foo bar FOO"'|jq 'match(["foo", "ig"])'
{"offset":0,"length":3,"string":"foo","captures":[]}
{"offset":8,"length":3,"string":"FOO","captures":[]}
# 如果我们在正则中加上`()`进行组匹配,则会捕获到组,但此时仍然是无名称的捕获组
$ echo '"foo bar FOO"'|jq 'match("(foo)"; "ig")'
{"offset":0,"length":3,"string":"foo","captures":[{"offset":0,"length":3,"string":"foo","name":null}]}
{"offset":8,"length":3,"string":"FOO","captures":[{"offset":8,"length":3,"string":"FOO","name":null}]}
# 我们可以给捕获组指定一个名称,叫做test,使用`(?<test>foo)`来指定,即匹配到`foo`字符串作为一个捕获组,并命名为`test`
$ echo '"foo bar FOO"'|jq 'match("(?<test>foo)"; "ig")'
{"offset":0,"length":3,"string":"foo","captures":[{"offset":0,"length":3,"string":"foo","name":"test"}]}
{"offset":8,"length":3,"string":"FOO","captures":[{"offset":8,"length":3,"string":"FOO","name":"test"}]}我们修改一下官方示例:
# 匹配0到1个bar形成命名组
$ echo '"foo bar foo foo Foo FOO barbar foo"'|jq 'match("foo (?<bar123>bar)? foo"; "ig")'
{"offset":0,"length":11,"string":"foo bar foo","captures":[{"offset":4,"length":3,"string":"bar","name":"bar123"}]}
{"offset":12,"length":8,"string":"foo Foo","captures":[{"offset":-1,"string":null,"length":0,"name":"bar123"}]}
$
# 匹配0个或多个bar形成命名组
$ echo '"foo bar foo foo Foo FOO barbar foo"'|jq 'match("foo (?<bar123>bar)* foo"; "ig")'
{"offset":0,"length":11,"string":"foo bar foo","captures":[{"offset":4,"length":3,"string":"bar","name":"bar123"}]}
{"offset":12,"length":8,"string":"foo Foo","captures":[{"offset":-1,"string":null,"length":0,"name":"bar123"}]}
{"offset":22,"length":14,"string":"FOO barbar foo","captures":[{"offset":29,"length":3,"string":"bar","name":"bar123"}]}
# 匹配任意字符,最后计算形成的数组的长度
$ echo '"abc"'|jq '[ match("."; "g")] | length'
3
# 计算字符串的长度
$ echo '"abc"'|jq 'length'
3
# 匹配任意字符
$ echo '"abc"'|jq '[ match("."; "g")]'
[{"offset":0,"length":1,"string":"a","captures":[]},{"offset":1,"length":1,"string":"b","captures":[]},{"offset":2,"length":1,"string":"c","captures":[]}]9.4 scan扫描
scan获取正则匹配后的非重叠子串。如果没有匹配,则输出为empty空。如果要捕获匹配字符串的所有项,请使用[]将表达式包裹起来。
# 匹配zz字符串
$ echo '"xyzzy-14"'|jq 'scan("zz")'
"zz"
# 匹配`, `字符串
$ echo '["a,b, c, d, e,f",", a,b, c, d, e,f, "]'|jq '[.[] | scan(", ")]'
[", ",", ",", ",", ",", ",", ",", ",", "]
# 匹配`, `字符串,后接1个或多个字母字符串
$ echo '["a,b, c, d, e,f",", a,b, c, d, e,f, abc"]'|jq '[.[] | scan(", [a-z]+")]'
[", c",", d",", e",", a",", c",", d",", e",", abc"]注意,scan不能加flag,否则会抛出异常:
$ echo '["a,b, c, d, e,f",", a,b, c, d, e,f, ABC"]'|jq '.[] | scan(", [a-z]+"; "i")'
jq: error: scan/2 is not defined at <top-level>, line 1:
.[] | scan(", [a-z]+"; "i")
jq: 1 compile error9.5 split 拆分字符串
- 为了向后兼容,
split只是进行字符串拆分,不是正则表达式。参考7.2.33 字符串拆分与拼接小节。 - 而
splits可以接受正则,输出是流而不是数组。
split只有一个参数的时候:
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'split("[1-9]+")'
["abc123Def456Ghi","JK[a-z]+789Lm"]
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'split("[a-z]+")'
["abc123Def456Ghi[1-9]+JK","789Lm"]可以看到,当split只有一个参数时,此时该参数不是正则表达式,而被当作普通的字符。
split有两个参数的情况:
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'split("[1-9]+"; "i")'
["abc","Def","Ghi[","-","]+JK[a-z]+","Lm"]
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'split("[a-z]+"; "i")'
["","123","456","[1-9]+","[","-","]+789",""]当split有两个参数时,第一个参数是正则表达式,第二个参数是flags。此时会按正则方式进行拆分。
而使用splits的结果有些不一样:
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'splits("[1-9]+")'
"abc"
"Def"
"Ghi["
"-"
"]+JK[a-z]+"
"Lm"
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'splits("[a-z]+")'
""
"123D"
"456G"
"[1-9]+JK["
"-"
"]+789L"
""
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'splits("[1-9]+"; "i")'
"abc"
"Def"
"Ghi["
"-"
"]+JK[a-z]+"
"Lm"
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'splits("[a-z]+"; "i")'
""
"123"
"456"
"[1-9]+"
"["
"-"
"]+789"
""
$可以看到,splits无论一个参数还是两个参数,第一个都是正则表达式,第二个是flags标志。最终输出是流,而不是数组。
9.6 sub替换
sub语法格式sub(regex; tostring),sub(regex; tostring; flags)。gsub语法格式gsub(regex; string),gsub(regex; string; flags)。
# 将匹配到的多个小写字母组成的字符串替换成@@@,可以看到,默认只替换第一个
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("[a-z]+"; "@@@"; "i")'
"@@@123Def456Ghi[1-9]+JK[a-z]+789Lm"
# 全局替换
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("[a-z]+"; "@@@"; "ig")'
"@@@123@@@456@@@[1-9]+@@@[@@@-@@@]+789@@@"
# 将匹配到的数字字符串替换成@@@,默认只替换第一个
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("[1-9]+"; "@@@")'
"abc@@@Def456Ghi[1-9]+JK[a-z]+789Lm"
# 全局替换
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("[1-9]+"; "@@@"; "g")'
"abc@@@Def@@@Ghi[@@@-@@@]+JK[a-z]+@@@Lm"我们在tostring中也可以使用命名捕获的引用。
# 获取任意字符作为head命名捕获组,然后将捕获组进行替换成后面的字符
# 在第二个参数中`\(.head)`表示捕获组head的值,即字符a,因此最后就输出了"Head=a Tail=bcdef"
# 也就是将捕获组替换成第二个参数对象的字符串
$ echo '"abcdef"'|jq 'sub("^(?<head>.)"; "Head=\(.head) Tail=")'
"Head=a Tail=bcdef"
# 对test捕获命名组进行替换
# 不区分大小写对匹配到`foo`,将其替换成`__foo^^`这样的字符串
$ echo '"foo bar FOO"'|jq 'sub("(?<test>foo)"; "__\(.test)^^"; "ig")'
"__foo^^ bar __FOO^^"我们再看一个复杂的:
# 不区分捕获字母组成的字符串,并将其设置为捕获命名组char,并对其进行替换,在其前面加上`_AA_`,在其后面加上`_BB_`字符串
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("(?<char>[a-z]+)"; "_AA_\(.char)_BB_"; "ig")'
"_AA_abc_BB_123_AA_Def_BB_456_AA_Ghi_BB_[1-9]+_AA_JK_BB_[_AA_a_BB_-_AA_z_BB_]+789_AA_Lm_BB_"
# 捕获数字组成的字符串,并将其设置为捕获命名组char,并对其进行替换,在其前面加上`_AA_`,在其后面加上`_BB_`字符串
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("(?<num>[1-9]+)"; "_AA_\(.num)_BB_"; "g")'
"abc_AA_123_BB_Def_AA_456_BB_Ghi[_AA_1_BB_-_AA_9_BB_]+JK[a-z]+_AA_789_BB_Lm"当然,我们在替换字符串中可以不使用捕获命名组的:
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("(?<num>[1-9]+)"; "_AA__BB_"; "g")'
"abc_AA__BB_Def_AA__BB_Ghi[_AA__BB_-_AA__BB_]+JK[a-z]+_AA__BB_Lm"此时,可以看到数字的数字字符串都被替换成_AA__BB_字符串了。
gsub类似于sub,只是在全局进行搜索替换:
# 使用sub只替换第一个
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'sub("(?<num>[1-9]+)"; "_AA_\(.num)_BB_")'
"abc_AA_123_BB_Def456Ghi[1-9]+JK[a-z]+789Lm"
# 使用gsub则都会替换,等价于sub增加`g`标志
$ echo '"abc123Def456Ghi[1-9]+JK[a-z]+789Lm"'|jq 'gsub("(?<num>[1-9]+)"; "_AA_\(.num)_BB_")'
"abc_AA_123_BB_Def_AA_456_BB_Ghi[_AA_1_BB_-_AA_9_BB_]+JK[a-z]+_AA_789_BB_Lm"10. 高级特性
- 在大多数编程语言中变量是必需的,在
jq中变量是一个高级特性。 jq中支持定义函数。jq的很多标准库都是使用jq的函数定义的。jq也有一些递归运算符,但主要在内部使用,并使用比较棘手。jq其实是与生成器强相关的,有很多有用的程序来处理生成器。- 支持
I/O。
10.1 变量
- 变量以
... as $identifier | ...这种方式定义并使用。 - 使用
$variable来定义变量。
下面是数组求平均值的示例:
length as $array_length | add / $array_length我们实际写一个:
# 求数组元素的和
$ echo '[1,2,3,4,5]'|jq 'add'
15
# 求数组元素的个数
$ echo '[1,2,3,4,5]'|jq 'length'
5
# 求数组的平均值,将length作为了变量$len,然后传递到管道后面`add / $len`中
$ echo '[1,2,3,4,5]'|jq 'length as $len | add / $len'
3再看官方手册上面的一个介绍。
现在我们有一个输入:
{"posts": [{"title": "Frist psot", "author": "anon"},
{"title": "A well-written article", "author": "person1"}],
"realnames": {"anon": "Anonymous Coward",
"person1": "Person McPherson"}}现在想获取每篇博客的作者的真实名称。像下面这样:
{"title": "Frist psot", "author": "Anonymous Coward"}
{"title": "A well-written article", "author": "Person McPherson"}测试这个示例:
将JSON数据写入到posts.json文件,文件内容如下:
{
"posts": [
{
"title": "Frist psot",
"author": "anon"
},
{
"title": "A well-written article",
"author": "person1"
}
],
"realnames": {
"anon": "Anonymous Coward",
"person1": "Person McPherson"
}
}获取每篇博客的真实作者信息:
# 非简写形式,通过指定.realnames的值作为$names变量
# .posts[]将会获取每个博客对象。
# .title 则会获取每个博客对象的title标题的值
# .author 则会获取每个博客对象的author作者的值
# 再将.atuhor的值作为键名,求得$names里面对应键的值,也就是作者的真名,将其作为author字段的值
$ cat posts.json |jq '.realnames as $names | .posts[] | {"title": .title, "author": $names[.author]}'
{
"title": "Frist psot",
"author": "Anonymous Coward"
}
{
"title": "A well-written article",
"author": "Person McPherson"
}
# 简写形式
$ cat posts.json |jq '.realnames as $names | .posts[] | {title, author: $names[.author]}'
{
"title": "Frist psot",
"author": "Anonymous Coward"
}
{
"title": "A well-written article",
"author": "Person McPherson"
}再看几个手册上的示例:
# .bar的值是200,将其做为变量x
# .foo 则会获取到值10
# . + $x 则会使用 10 + x变量的值200=210
$ echo '{"foo":10, "bar":200}'|jq '.bar as $x | .foo | . + $x'
210
# 首先 `. as $i` 将当前输入值赋值给变量i
# `[(.*2|. as $i| $i), $i]` 这个数组表达式要分两部分来看
# 先看右边的`$i`,这是第二个元素,是直接将变量i的值作为第二个元素,也就是5
# 再看左边的`(.*2|. as $i| $i)`, 刚开始输入值是5,也就是.是5,那么 .*2 就变成了10
# 这个时候又有一个`|. as $i`,即将乘以2后的值10作为变量i的值,
# 这个时候注意啦,变量i相当于被重新赋值了,只对数组第1个元素产生影响,对第二个元素无影响
# 最后`| $i`则会打印变量i的值10作为第一个元素的值
$ echo '5'|jq '. as $i|[(.*2|. as $i| $i), $i]'
[
10,
5
]
# 这个例子中,同时对数组中的多个元素进行一一对应的变量定义,然后求变量的和
$ echo '[2, 3, {"c": 4, "d": 5}]'|jq '. as [$a, $b, {c: $c}] | $a + $b + $c'
9
# 可以看到,变量按定义的前后顺序,依次与对应的元素进行匹配
# 当数组元素是对象时,则通过对象的键来进行匹配,如对象的键是"c",匹配变量c,对象的键是"d",匹配变量d
$ echo '[2, 3, {"c": 4, "d": 5}]'|jq '. as [$a, $b, {c: $c}] | [$a, $b,$c]'
[
2,
3,
4
]
$ echo '[2, 3, {"c": 4, "d": 5}]'|jq '. as [$a, $b, {c: $c, d: $d}] | [$a, $b,$c, $d]'
[
2,
3,
4,
5
]
# 对多个变量进行求和运算
$ echo '[2, 3, {"c": 4, "d": 5}]'|jq '. as [$a, $b, {c: $c, d: $d}] | [$a, $b, $c, $d]|add'
14
# 对输入流多个元素进行变量处理
$ echo '[[0], [0, 1], [2, 1, 0]]'|jq '.[] as [$a, $b] | {a: $a, b: $b}'
{
"a": 0,
"b": null
}
{
"a": 0,
"b": 1
}
{
"a": 2,
"b": 1
}10.2 函数
- 可以通过
def关键字来定义函数。函数定义后,就可以将其作为过滤器使用。
如定义increment自增过滤器:
$ echo '[1,2,3,4]'|jq 'def increment: . + 1; [.[]|increment]'
[2,3,4,5]按同样的思路,我们可以定义一个double过滤器:
$ echo '[1,2,3,4]'|jq 'def double: . * 2; [.[]|double]'
[2,4,6,8]再复杂一点,定义一个乘方运算:
# 定义乘方时,函数中还使用了递归
$ echo '[1,2,3,4]'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; [.[]|power(1)]'
[1,2,3,4]
$ echo '[1,2,3,4]'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; [.[]|power(2)]'
[1,4,9,16]
$ echo '[1,2,3,4]'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; [.[]|power(3)]'
[1,8,27,64]
$ echo '[1,2,3,4]'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; [.[]|power(4)]'
[1,16,81,256]
$ echo '[1,2,3,4]'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; [.[]|power(5)]'
[1,32,243,1024]
$ echo '2'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; power(1)'
2
$ echo '2'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; power(2)'
4
$ echo '2'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; power(3)'
8
$ echo '2'|jq 'def power(n): if n > 1 then . * power( n - 1) else . end; power(4)'
16看手册上的例子:
$ echo '5'|jq 'def foo(f): f|f; foo(. * 2)'
20
$ echo '5'|jq 'def foo(f): f|f|f; foo(. * 2)'
40
# 输入流的值是5,函数中需要执行三次f。
# 第一次执行用户的表达式 5 * 2 + 2 = 12
# 第二次执行用户的表达式 12 * 2 + 2 = 26
# 第三次执行用户的表达式 26 * 2 + 2 = 54
# 因此最后输出为54
$ echo '5'|jq 'def foo(f): f|f|f; foo(. * 2 + 2)'
54可以看到,使用foo过滤器可以多次重复执行用户定义的表达式。
再看手册的两个例子:
# 基础知识
# 数字相加,是将新数组中的元素追加到原数组中
$ echo '[1,2]'|jq '. + [3,4]'
[1,2,3,4]
# map的话,会对数组中每个元素执行表达式`.[0]`,然后就结果组成新的数组
$ echo '[[1,2],[10,20]]'|jq 'map(.[0])'
[1,10]
# 测试map定义,可以看到,与上在贩结果一致
$ echo '[[1,2],[10,20]]'|jq 'def mmap(f): [.[] | f]; mmap(.[0])'
[1,10]
# addvalue函数,会将用户定义的表达式的值与输入流相加
# 对于`map(addvalue(.[0])`的意思就是将数组中每个元素(即子数组)的第一个元素,追加到原来的数组后面
$ echo '[[1,2],[10,20]]'|jq 'def addvalue(f): . + [f]; map(addvalue(.[0]))'
[[1,2,1],[10,20,10]]
# 这个addvalue函数的定义与上面有所不同,将map移到函数定义里面了
# addvalue(.[0]) 表达式,先计算`.[0]`,因为输入流是'[[1,2],[10,20]]',因此`.[0]`其实就是第一个子元素,也就是数组`[1,2]`
# 再看函数定义里面`f as $x | map(. + $x)`,将用户定义的表达式获取的值作为变量x的值,然后使用map过滤器对输入流的每一个元素与变量x相加,将结果形式数组
# 也就是用第一个元素`[1,2]`与表达式`.[0]`的值`[1,2]`相加,得到`[1,2,1,2]`
# 用第二个元素`[10,20]`与表达式`.[0]`的值`[1,2]`相加,得到`[10,20,1,2]`
# 再将两个值作为元素放在数组中,形成最后的结果`[[1,2,1,2],[10,20,1,2]]`
$ echo '[[1,2],[10,20]]'|jq 'def addvalue(f): f as $x | map(. + $x); addvalue(.[0])'
[[1,2,1,2],[10,20,1,2]]更复杂的,求斐波那契数列:
$ echo '[0,1,2,3,4,5,6,7,8,9]'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; map(fib(.))'
[0,1,1,2,3,5,8,13,21,34]
$ echo '9'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(.)'
34
$ echo '10'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(.)'
55
$ echo '11'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(.)'
89
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(12)'
144
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(13)'
233
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(14)'
377
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(15)'
610
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(16)'
987
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(17)'
1597
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(18)'
2584
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(19)'
4181
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(20)'
6765
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(21)'
10946
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(22)'
17711
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(23)'
28657
$ echo 'null'|jq 'def fib(n): if n == 0 then 0 elif n == 1 then 1 elif n >= 2 then fib(n-1) + fib(n-2) else . end; fib(24)'
46368
$斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列:0、1、1、2、3、5、8、13、21、34、……在数学上,斐波那契数列以如下被以递推的方法定义:F(0)=0,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N*)在现代物理、准晶体结构、化学等领域,斐波纳契数列都有直接的应用,为此,美国数学会从 1963 年起出版了以《斐波纳契数列季刊》为名的一份数学杂志,用于专门刊载这方面的研究成果。
斐波那契数列指的是这样一个数列:
这个数列从第3项开始,每一项都等于前两项之和。
可以看到,我们使用jq获取到的值与百度百科上面定义的数据是一样。
10.3 Reduce
reduce允许你将多个值合并在一起形成一个单一的值。
如:
# 依次将输入流中的每个数作为item变量,并与初始值0进行相加,得到最后的值为10
$ echo '[1,2,3,4]'|jq 'reduce .[] as $item (0; . + $item)'
10
# 依次将输入流中的每个数作为item变量,并与初始值20进行相加,得到最后的值为30
$ echo '[1,2,3,4]'|jq 'reduce .[] as $item (20; . + $item)'
30
# 依次将输入流中的每个数作为item变量,并与初始值40进行相加,得到最后的值为50
$ echo '[1,2,3,4]'|jq 'reduce .[] as $item (40; . + $item)'
5010.4 isempty是否为空
isempty(exp),如果exp表达式输出为空(no outputs),则输出为true,否则输出为false。
$ echo 'null'|jq 'isempty(.)'
false
$ echo 'null'|jq 'isempty(null)'
false
$ echo 'null'|jq 'isempty(empty)'
true
$ echo 'null'|jq 'isempty("")'
false只有不输出任何东西的时候,isempty(exp)才会返回true真。
10.5 limit输出最多n个值
limit(n; exp)可以输出表达式exp中的前n个结果。first(exp)输出第一个元素。last(exp)输出最后一个元素。nth(n; exp)输出第n+1个元素。
$ echo 'null'|jq 'range(10)'
0
1
2
3
4
5
6
7
8
9
# 输出3个元素
$ echo 'null'|jq '[range(10)]|[limit(3; .[])]'
[0,1,2]
$ echo 'null'|jq '[range(10)]|[limit(5; .[])]'
[0,1,2,3,4]
$ echo 'null'|jq '[range(10)]|[limit(10; .[])]'
[0,1,2,3,4,5,6,7,8,9]
$ echo 'null'|jq '[range(10)]|[limit(12; .[])]'
[0,1,2,3,4,5,6,7,8,9]
# 输出第1个元素
$ echo 'null'|jq '[range(10)]|first(.[])'
0
# 输出最后一个元素
$ echo 'null'|jq '[range(10)]|last(.[])'
9
# 输出第 2 + 1 个元素
$ echo 'null'|jq '[range(10)]|nth(2;.[])'
2
# 输出第 1 + 1 个元素
$ echo 'null'|jq '[range(10)]|nth(1;.[])'
1
# 输出第 0 + 1 个元素
$ echo 'null'|jq '[range(10)]|nth(0;.[])'
0
# 输出第 9 + 1 个元素
$ echo 'null'|jq '[range(10)]|nth(9;.[])'
910.6 foreach对每个元素执行操作
$ echo '[[2,1], [5,3], [6,4]]'|jq '[foreach .[] as [$i, $j] (0; . + $i - $j)]'
[1,3,5]
$ echo '[1,2,null,3,4,null,"a","b",null]'|jq '[foreach .[] as $item ([[],[]]; if $item == null then [[],.[0]] else [(.[0] + [$item]),[]] end;if $item == null then .[1] else empty end )]'
[[1,2],[3,4],["a","b"]]10.7 模块
jq也有库、模块系统,模块是后缀为.jq的文件。jq默认从默认的搜索路径搜索模块。你可以通过import或include改变搜索路径。~是家目录,.是当前目录。$ORIGIN是jq可执行程序所在目录。- 默认搜索路径是给
-L命令行选项的搜索路径,否则是["~/.jq", "$ORIGIN/../lib/jq", "$ORIGIN/../lib"]。 - 不允许具有相同名称的连续组件以避免歧义(例如,
foo/foo)。 - 使用
-L$HOME/.jq可以在$HOME/.jq/foo.jq和$HOME/.jq/foo/foo.jq中找到模块foo。 - 如果
$HOME/.jq是一个文件,则它会被导入到主程序中。
这个主题,官方文档并没有给出示例,我们只能通过其源码仓库进行搜索一下,如我们搜索module关键字,可以搜索到类似如下这样的信息:
[mzh@MacBookPro jq (master ✗)]$ grep -Rn 'module' *|grep -v '\.c'|grep '\.test:'|grep module
tests/jq.test:1454:# module system
tests/jq.test:1484:module (.+1); 0
tests/jq.test:1503:modulemeta
tests/jq.test:1507:modulemeta | .deps |= length
tests/jq.test:1513:jq: error: syntax error, unexpected ';', expecting $end (Unix shell quoting issues?) at /home/nico/ws/jq/tests/modules/syntaxerror/syntaxerror.jq, line 1:
tests/jq.test:1551:{if:0,and:1,or:2,then:3,else:4,elif:5,end:6,as:7,def:8,reduce:9,foreach:10,try:11,catch:12,label:13,import:14,include:15,module:16}
tests/jq.test:1553:{"if":0,"and":1,"or":2,"then":3,"else":4,"elif":5,"end":6,"as":7,"def":8,"reduce":9,"foreach":10,"try":11,"catch":12,"label":13,"import":14,"include":15,"module":16}
tests/jq.test:1668:#["as","def","module","import","include","if","then","else","elif","end","reduce","foreach","and","or","try","catch","label","break","__loc__"]
tests/jq.test:1672:#["as","def","module","import","include","if","then","else","elif","end","reduce","foreach","and","or","try","catch","label","break","__loc__"]
可以看到jq.test1454行处就是关于模块的测试用例:
[mzh@MacBookPro jq (master ✗)]$ sed -n '1454,1482p' tests/jq.test
# module system
import "a" as foo; import "b" as bar; def fooa: foo::a; [fooa, bar::a, bar::b, foo::a]
null
["a","b","c","a"]
import "c" as foo; [foo::a, foo::c]
null
[0,"acmehbah"]
include "c"; [a, c]
null
[0,"acmehbah"]
import "data" as $e; import "data" as $d; [$d[].this,$e[].that,$d::d[].this,$e::e[].that]|join(";")
null
"is a test;is too;is a test;is too"
include "shadow1"; e
null
2
include "shadow1"; include "shadow2"; e
null
3
import "shadow1" as f; import "shadow2" as f; import "shadow1" as e; [e::e, f::e]
null
[2,3]
[mzh@MacBookPro jq (master ✗)]$我们在tests目录中发现了modules目录,看一下其中的文件:
[mzh@MacBookPro modules (master ✗)]$ ls
a.jq c home1 lib shadow2.jq test_bind_order.jq test_bind_order1.jq
b data.json home2 shadow1.jq syntaxerror test_bind_order0.jq test_bind_order2.jq
[mzh@MacBookPro modules (master ✗)]$看一下文件内容:
./shadow2.jq:1:def e: 3;
./test_bind_order1.jq:1:def sym1: 1;
./test_bind_order1.jq:2:def sym2: 1;
./home1/.jq:1:def foo: "baz";
./home1/.jq:2:def f: "wat";
./home1/.jq:3:def f: "foo";
./home1/.jq:4:def g: "bar";
./home1/.jq:5:def fg: f+g;
./test_bind_order0.jq:1:def sym0: 0;
./test_bind_order0.jq:2:def sym1: 0;
./test_bind_order.jq:1:import "test_bind_order0" as t;
./test_bind_order.jq:2:import "test_bind_order1" as t;
./test_bind_order.jq:3:import "test_bind_order2" as t;
./test_bind_order.jq:4:def check: if [t::sym0,t::sym1,t::sym2] == [0,1,2] then true else false end;
./a.jq:1:module {version:1.7};
./a.jq:2:def a: "a";
./test_bind_order2.jq:1:def sym2: 2;
./lib/jq/f.jq:1:def f: "f is here";
./lib/jq/e/e.jq:1:def bah: "bah";
./home2/.jq/g.jq:1:def g: 1;
./c/c.jq:1:module {whatever:null};
./c/c.jq:2:import "a" as foo;
./c/c.jq:3:import "d" as d {search:"./"};
./c/c.jq:4:import "d" as d2{search:"./"};
./c/c.jq:5:import "e" as e {search:"./../lib/jq"};
./c/c.jq:6:import "f" as f {search:"./../lib/jq"};
./c/c.jq:7:import "data" as $d;
./c/c.jq:8:def a: 0;
./c/c.jq:9:def c:
./c/c.jq:10: if $d::d[0] != {this:"is a test",that:"is too"} then error("data import is busted")
./c/c.jq:11: elif d2::meh != d::meh then error("import twice doesn't work")
./c/c.jq:12: elif foo::a != "a" then error("foo::a didn't work as expected")
./c/c.jq:13: elif d::meh != "meh" then error("d::meh didn't work as expected")
./c/c.jq:14: elif e::bah != "bah" then error("e::bah didn't work as expected")
./c/c.jq:15: elif f::f != "f is here" then error("f::f didn't work as expected")
./c/c.jq:16: else foo::a + "c" + d::meh + e::bah end;
./c/d.jq:1:def meh: "meh";
./syntaxerror/syntaxerror.jq:1:wat;
./b/b.jq:1:def a: "b";
./b/b.jq:2:def b: "c";
./shadow1.jq:1:def e: 1;
./shadow1.jq:2:def e: 2;
[mzh@MacBookPro modules (master ✗)]$可以看到,模块文件里面的内部大部分都是定义的函数。
我们来测试一下。
假如我们编写一个mymodule.jq的文件,查看其内容如下:
$ cat mymodule.jq
#!/bin/jq
# 自定义模块
# 以#井号开头的行是注释
# Filename: mymodule.jq
# Author: meizhaohui
# 两倍
def double:
. * 2;
# 自增1
def increment: . + 1;
# 幂
def power(n):
if (n > 1) then
. * power( n - 1)
else
.
end;
# 斐波那契数列
def fib(n):
if n == 0 then
0
elif n == 1 then
1
elif n >= 2 then
fib(n-1) + fib(n-2)
else
.
end;
# 大写
def upper:
.|ascii_upcase;
# 小写:
def lower:
.|ascii_downcase;现在我们来测试一下使用我们的模块。
10.7.1 导入自定义模块
- 我们使用
import RelativePathString as NAME这种方式导入模块。然后使用NAME::youfunname的方式调用自定义的函数。
$ echo '2'|jq 'import "mymodule" as M; M::double'
4
$ echo '2'|jq 'import "mymodule" as M; M::increment'
3
$ echo '2'|jq 'import "mymodule" as M; M::power(3)'
8
$ echo 'null'|jq 'import "mymodule" as M; M::fib(2)'
1
$ echo 'null'|jq 'import "mymodule" as M; M::fib(3)'
2
$ echo 'null'|jq 'import "mymodule" as M; M::fib(4)'
3
$ echo '"JQ is cool!"'|jq 'import "mymodule" as M; M::upper'
"JQ IS COOL!"
$ echo '"JQ is cool!"'|jq 'import "mymodule" as M; M::lower'
"jq is cool!"10.7.2 包含模块文件
- 我们也可以使用
include RelativePathString;这种方式导入模块文件。
看以下示例:
$ echo '2'|jq 'include "mymodule"; double'
4
$ echo '2'|jq 'include "mymodule"; increment'
3
$ echo '2'|jq 'include "mymodule"; power(3)'
8
$ echo 'null'|jq 'include "mymodule"; fib(2)'
1
$ echo 'null'|jq 'include "mymodule"; fib(3)'
2
$ echo 'null'|jq 'include "mymodule"; fib(4)'
3
$ echo '"JQ is cool!"'|jq 'include "mymodule"; upper'
"JQ IS COOL!"
$ echo '"JQ is cool!"'|jq 'include "mymodule"; lower'
"jq is cool!"可以看到此种方式的输出结果与上一节的相同。
10.7.3 导入JSON数据
可以使用import RelativePathString as $NAME方式导入JSON文件(.json文件)中的数据,并使用$NAME::NAME调用数据。
如我们有一个data.json的文件,其内容如下:
{
"this": "is a test",
"that": "is too"
}测试:
$ echo 'null'|jq 'import "data" as $DATA; $DATA::DATA'
[
{
"this": "is a test",
"that": "is too"
}
]
$ echo 'null'|jq 'import "data" as $DATA; $DATA[]'
{
"this": "is a test",
"that": "is too"
}
$ echo 'null'|jq 'import "data" as $DATA; $DATA[].this'
"is a test"
$ echo 'null'|jq 'import "data" as $DATA; $DATA[].that'
"is too"10.7.4 将模块放在~/.jq文件中
如果我们将我们的模块文件复制为.jq,则jq程序会自动加载模块文件的内容。
$ cp mymodule.jq .jq
$ echo '2'|jq 'double'
4
$ echo '2'|jq 'power(2)'
4
$ echo '"JQ is cool!"'|jq 'upper'
"JQ IS COOL!"
$ echo '"JQ is cool!"'|jq 'lower'
"jq is cool!"可以看到,此时我们的自定义模块可以直接使用。
10.8 其他主题
- 数学函数。
One-input C math functions:
acosacoshasinasinhatanatanhcbrtceilcoscosherferfcexpexp10exp2expm1fabsfloorgammaj0j1lgammaloglog10log1plog2logbnearbyintpow10rintroundsignificandsinsinhsqrttantanhtgammatruncy0y1.Two-input C math functions:
atan2copysigndremfdimfmaxfminfmodfrexphypotjnldexpmodfnextafternexttowardpowremainderscalbscalblnyn.Three-input C math functions:
fma.
向上取整:
$ echo '2.1'|jq 'ceil'
3
$ echo '2.4'|jq 'ceil'
3
$ echo '2.5'|jq 'ceil'
3
$ echo '2.9'|jq 'ceil'
3向下取整:
$ echo '2.1'|jq 'floor'
2
$ echo '2.4'|jq 'floor'
2
$ echo '2.5'|jq 'floor'
2
$ echo '2.9'|jq 'floor'
2四舍五入:
$ echo '2.1'|jq 'round'
2
$ echo '2.4'|jq 'round'
2
$ echo '2.45'|jq 'round'
2
$ echo '2.5'|jq 'round'
3
$ echo '2.9'|jq 'round'
3幂:
$ echo 'null'|jq 'pow(2;3)'
8
$ echo 'null'|jq 'pow(2;4)'
16
$ echo 'null'|jq 'pow(2;5)'
32
$ echo 'null'|jq 'pow(2;6)'
64- 手册中
Recursion、Generators and iterators、I/O、Streaming等其他主题相对复杂。此处不提。忽略。
本文完!
==========================================================================